핵심 요약
기존 텍스트 기반 모델의 한계를 넘어 음성을 직접 처리하는 Gemini 2.5 Flash Native Audio 모델의 대규모 업데이트가 이루어졌다. 이번 업데이트는 복잡한 워크플로우 처리, 정교한 기능 호출(Function Calling), 그리고 문맥 유지 능력을 강화하여 더 자연스러운 대화형 AI 구축을 지원한다. 특히 70개 이상의 언어를 지원하는 실시간 음성 대 음성(Speech-to-Speech) 번역 기능을 통해 화자의 억양과 속도를 유지하는 고도화된 통역 경험을 제공한다. 현재 Vertex AI와 Google AI Studio를 통해 개발자들에게 제공되며, 구글 번역 앱 등 실제 서비스에도 순차적으로 적용되고 있다.
배경
Vertex AI 또는 Google AI Studio 사용 권한, 기능 호출(Function Calling)에 대한 기본 이해, Gemini API 활용 지식
대상 독자
음성 기반 AI 에이전트 개발자 및 글로벌 커뮤니케이션 솔루션 설계자
의미 / 영향
음성 모델이 텍스트를 거치지 않고 직접 오디오를 이해하고 생성하는 네이티브 방식이 주류가 됨에 따라, 지연 시간은 줄고 상호작용의 질은 비약적으로 높아질 것이다. 이는 고객 센터 자동화뿐만 아니라 실시간 언어 장벽 해소에 결정적인 역할을 할 것으로 보인다.
섹션별 상세
이미지 분석
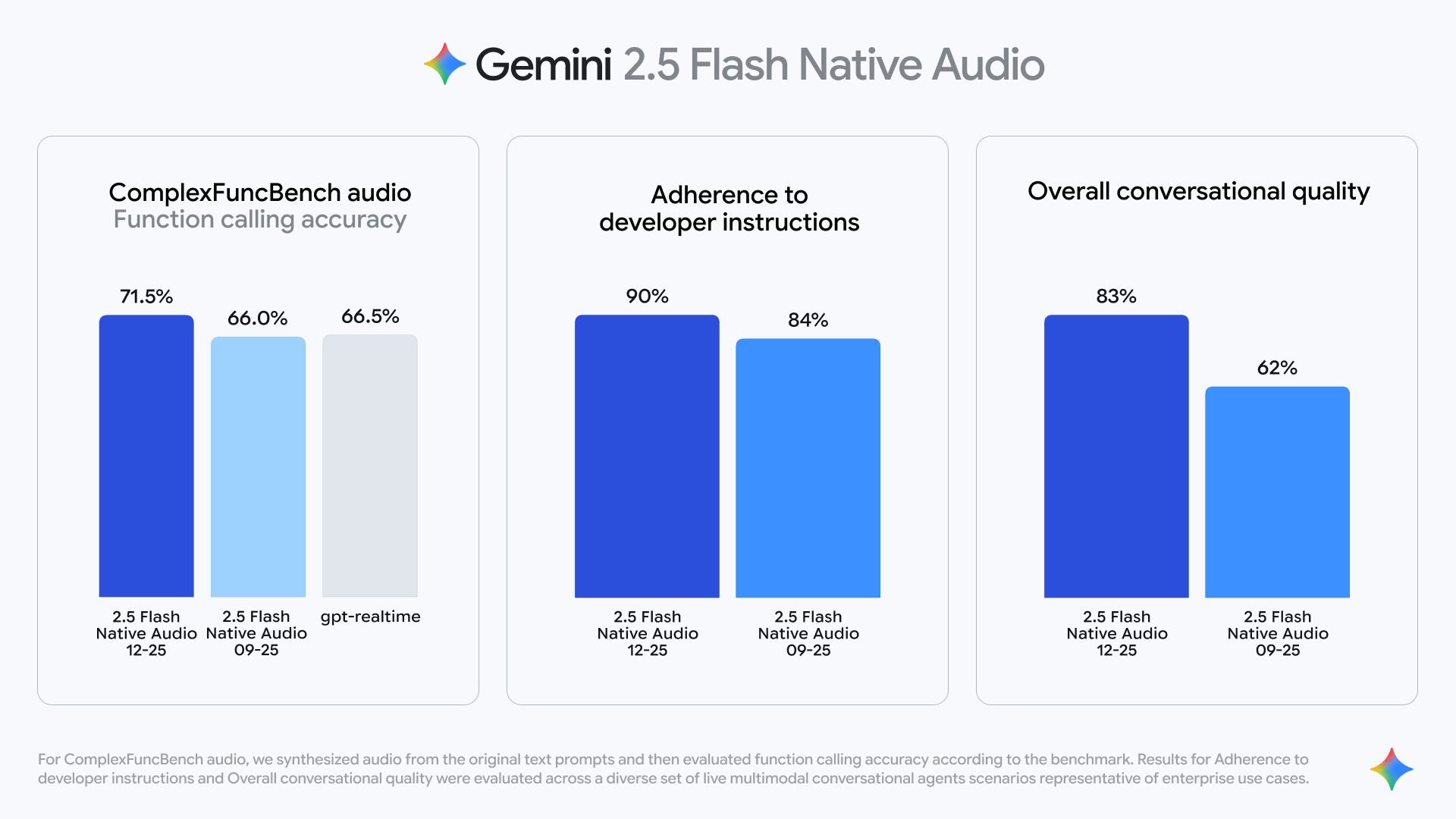
ComplexFuncBench Audio 평가에서 Gemini 2.5 Native Audio가 71.5%의 점수를 기록하며 다른 모델들보다 우수한 기능 호출 성능을 보임을 시각적으로 증명한다. 이는 모델의 기술적 우위를 뒷받침하는 핵심 데이터이다.
Gemini 2.5 Flash Native Audio의 성능을 이전 버전 및 경쟁사와 비교한 벤치마크 차트이다.
실무 Takeaway
- Gemini 2.5 Flash Native Audio를 활용하면 별도의 STT/TTS 단계 없이 음성을 직접 처리하여 지연 시간을 줄이고 감정 표현이 풍부한 에이전트를 구축할 수 있다.
- ComplexFuncBench에서 71.5%를 기록한 기능 호출 성능을 통해 실시간 데이터 조회가 필요한 복잡한 음성 워크플로우를 자동화할 수 있다.
- 구글 번역 앱의 베타 기능을 통해 70개국 이상의 언어에 대해 화자의 음성 특성을 유지하는 실시간 통역 서비스를 즉시 테스트해 볼 수 있다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료