TL;DR
머신러닝 모델이 현실 세계를 예측할 때 발생하는 불확실성은 단순한 오류가 아니라 모델이 반드시 관리해야 할 핵심 요소이다. 불확실성은 확률을 통해 정량화되며, 데이터의 무작위성인 노이즈와 지식의 부족에서 기인한다. 본 아티클은 불확실성을 데이터 자체의 한계인 Aleatoric과 모델 지식의 한계인 Epistemic으로 구분하여 설명한다. 이를 관리하기 위해 확률론적 모델, 앙상블 기법, 데이터 정제 등의 전략을 활용하여 더 견고하고 신뢰할 수 있는 AI 시스템을 구축하는 방법을 제시한다.
배경
기초 확률 및 통계 지식, 머신러닝 모델 학습 및 평가 프로세스에 대한 이해
대상 독자
머신러닝 모델의 신뢰성과 견고함을 개선하고자 하는 데이터 과학자 및 엔지니어
의미 / 영향
불확실성을 단순히 제거해야 할 대상으로 보지 않고 정량화하여 관리함으로써, 자율주행이나 의료 진단과 같이 안전이 중요한 분야에서 AI의 신뢰도를 획기적으로 높일 수 있다.
섹션별 상세
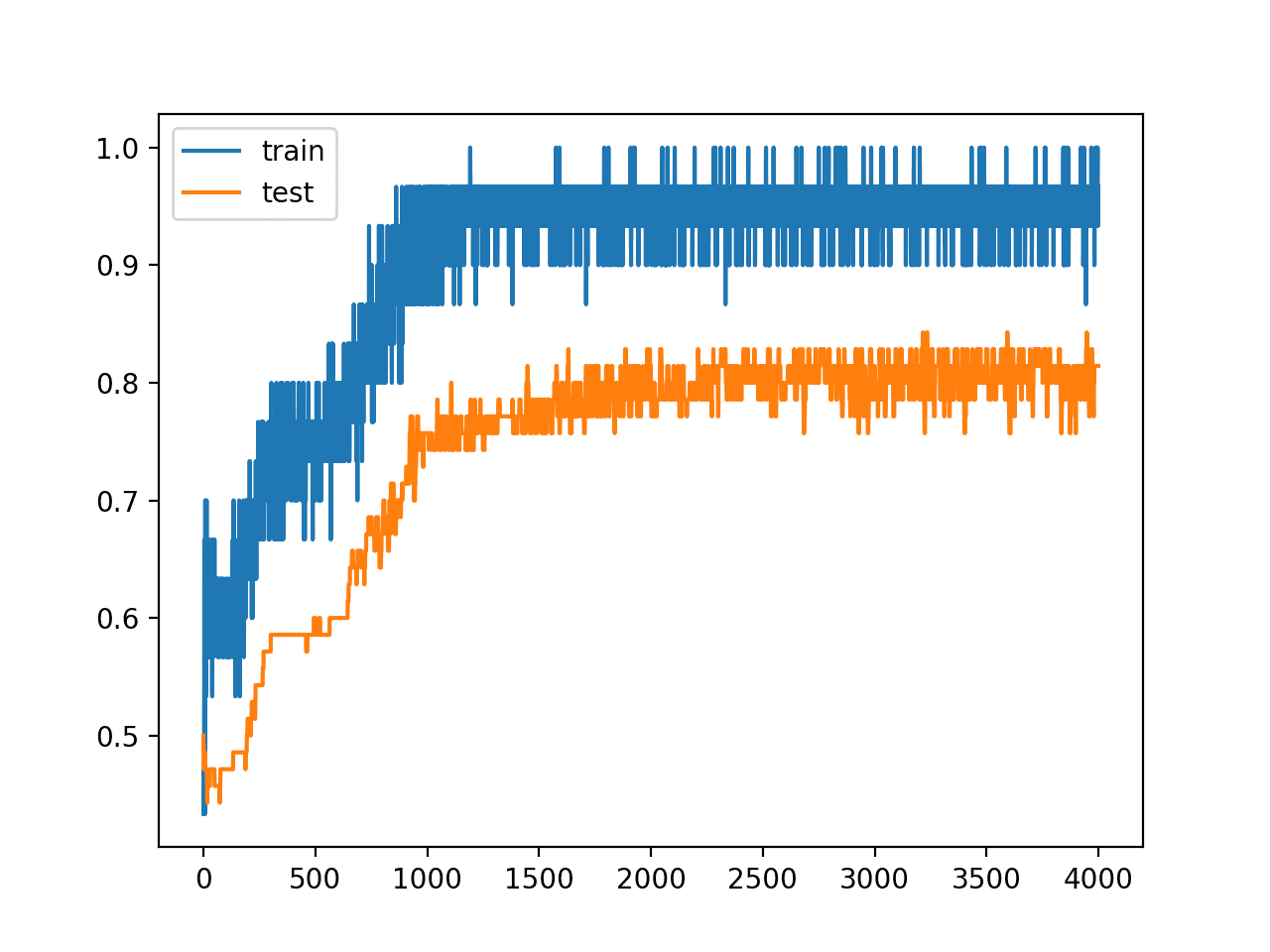
이미지 분석
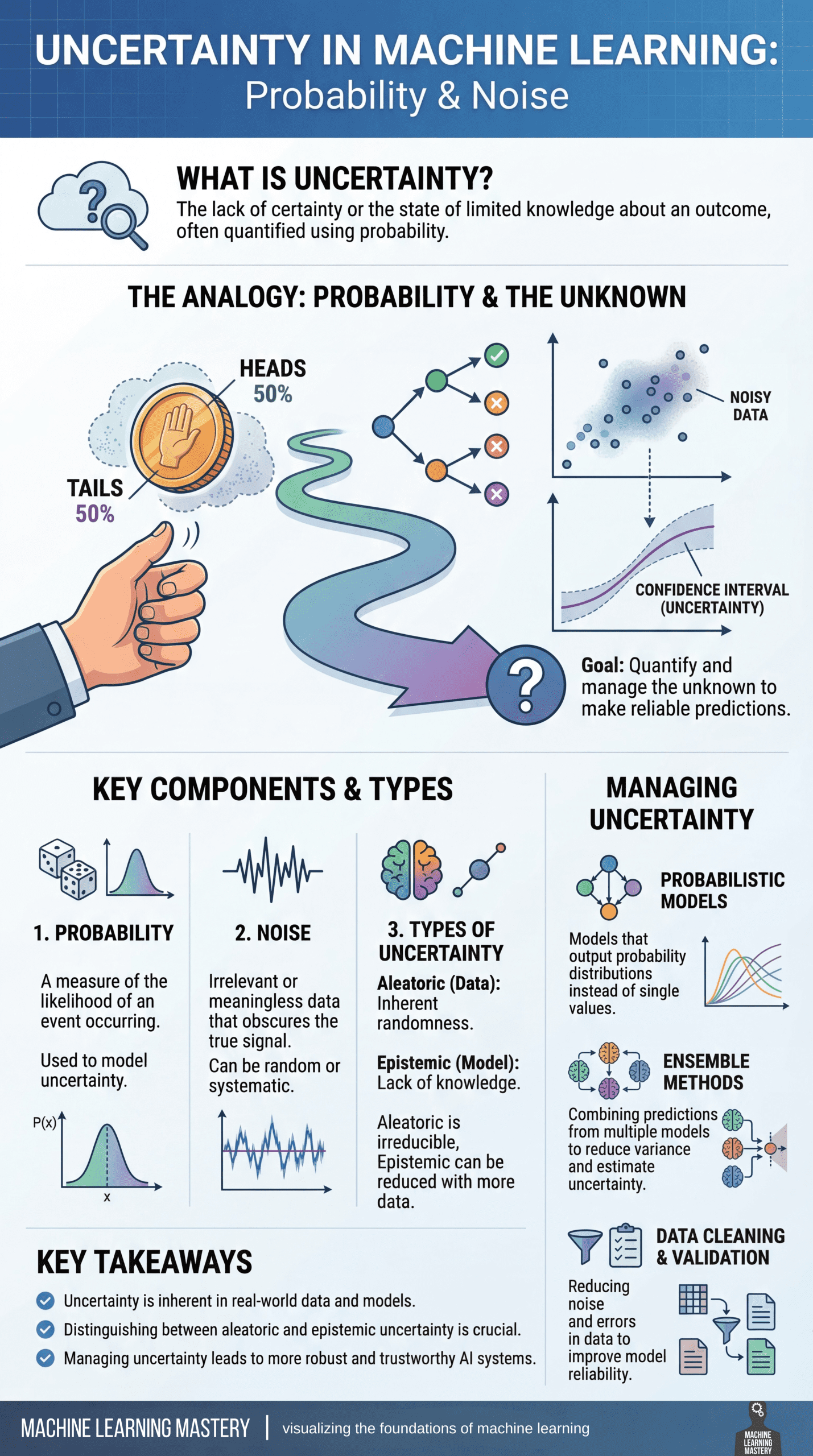
불확실성의 정의부터 Aleatoric과 Epistemic의 차이, 그리고 이를 관리하기 위한 확률론적 모델 및 앙상블 기법을 시각적으로 요약하여 보여준다. 아티클의 핵심 내용을 한눈에 파악할 수 있는 종합적인 자료이다.
머신러닝의 불확실성, 확률, 노이즈의 개념과 관리 방법을 정리한 인포그래픽이다.
용어 해설
- Aleatoric Uncertainty
- — 데이터 자체에 내재된 무작위성으로 인해 발생하는 불확실성이다. 주사위 던지기처럼 시스템의 본질적인 무작위성에서 기인하므로 더 많은 데이터를 수집하더라도 줄어들지 않는 환원 불가능한 특성을 가진다.
- Epistemic Uncertainty
- — 모델이 데이터 생성 과정이나 현상에 대해 충분한 지식을 갖지 못해 발생하는 불확실성이다. 이는 모델의 구조를 개선하거나 더 많은 학습 데이터를 확보함으로써 줄일 수 있는 환원 가능한 불확실성에 해당한다.
- Noise
- — 데이터 내에서 실제 신호를 가리는 무관하거나 무작위적인 변동이다. 측정 오류나 환경적 요인으로 발생하며, 모델이 데이터의 본질적인 패턴을 학습하는 것을 방해하여 예측의 정확도를 떨어뜨리는 주요 원인이 된다.
- Probabilistic Models
- — 단일 예측값 대신 결과의 확률 분포를 출력하는 모델이다. 예측의 확신 정도를 명시적으로 표현할 수 있어, 불확실성이 높은 상황에서 위험을 관리하고 더 신뢰할 수 있는 의사결정을 내리는 데 도움을 준다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.




