핵심 요약
Character.AI는 연구용 GPU 클러스터 운영의 난제인 HPC 환경의 생산성과 Kubernetes의 운영 효율성을 동시에 달성하기 위해 개발한 'Slonk(Slurm on Kubernetes)' 아키텍처를 공개했다. 연구자들은 익숙한 SLURM 인터페이스를 통해 작업을 제출하고, 인프라 팀은 Kubernetes를 통해 자동 복구 및 자원 확장을 관리한다. Slonk는 SLURM 노드를 Kubernetes Pod로 매핑하여 운영하며, 공유 NFS 볼륨과 커스텀 오퍼레이터를 통해 대규모 학습 환경의 안정성을 확보한다. 현재 GitHub를 통해 Helm 차트와 오퍼레이터 등 핵심 구성 요소의 스냅샷이 제공되고 있다.
배경
Kubernetes 기초, SLURM 스케줄러 이해, GPU 인프라 운영 경험
대상 독자
ML 인프라 엔지니어, GPU 클러스터 관리자, 대규모 모델 학습 연구자
의미 / 영향
대규모 AI 모델 학습을 위한 인프라 구축 시 SLURM과 Kubernetes 사이에서 고민하던 기업들에게 실질적인 통합 아키텍처 레퍼런스를 제공한다. 특히 오픈소스로 공개된 Slonk는 유사한 인프라 문제를 겪는 조직의 개발 속도를 높일 것으로 기대된다.
섹션별 상세
이미지 분석
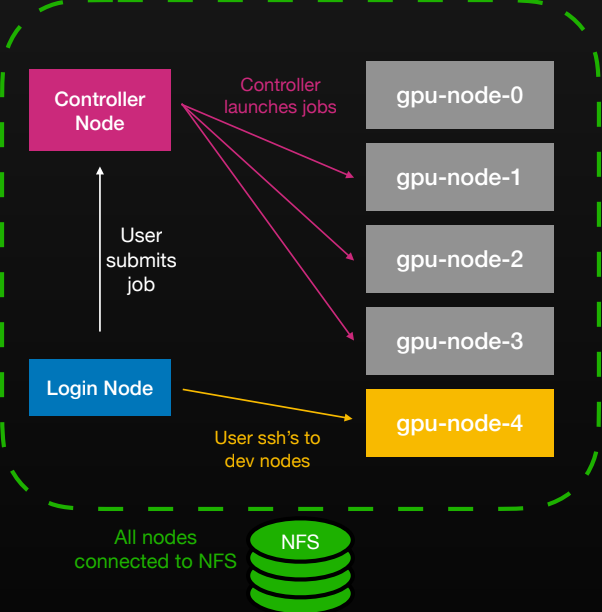
사용자가 로그인 노드를 통해 작업을 제출하면 컨트롤러 노드가 GPU 노드들에 작업을 할당하고, 모든 노드가 NFS에 연결된 구조를 보여준다. 연구자의 워크플로우와 인프라 구성 요소 간의 상호작용을 시각화한다.
Slonk의 전체적인 작업 제출 및 노드 연결 구조도.
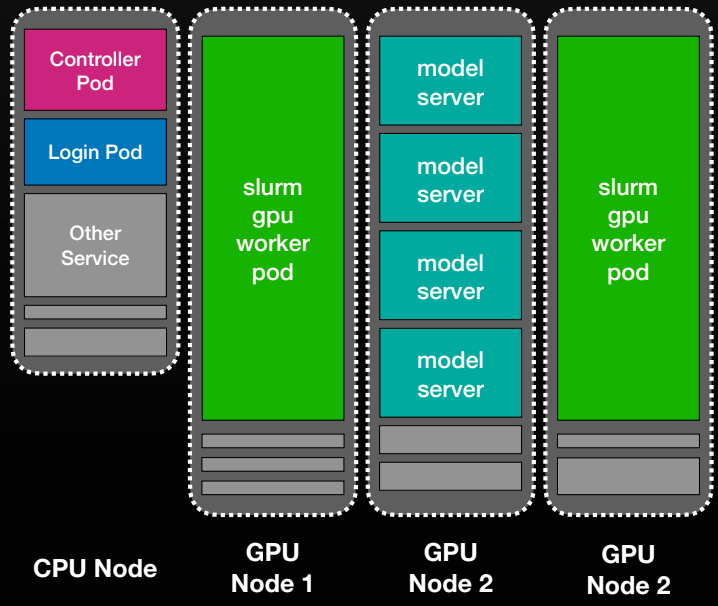
CPU 노드와 GPU 노드 내에서 SLURM 관련 Pod(컨트롤러, 로그인, 워커)와 일반 모델 서버 Pod가 어떻게 공존하는지 보여준다. Kubernetes를 활용한 자원 격리 및 혼합 워크로드 운영 방식을 설명한다.
Kubernetes 노드 내의 Pod 배치 및 모델 서버와의 공존 구조.
실무 Takeaway
- SLURM의 사용자 경험과 Kubernetes의 운영 자동화를 결합하여 연구 생산성과 인프라 안정성을 동시에 확보했다.
- 커스텀 오퍼레이터와 헬스 체크 시스템을 통해 GPU 및 네트워크 장애를 자동으로 감지하고 복구하여 관리 공수를 최소화했다.
- NFS 공유 스토리지와 토폴로지 인식 스케줄링을 통해 대규모 분산 학습 환경의 성능과 데이터 접근성을 최적화했다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료