핵심 요약
Character.AI는 대규모 사용자 기반을 지원하기 위해 AMD Instinct MI325X GPU 플랫폼에서 Qwen3-235B 모델의 추론 성능을 최적화했다. DigitalOcean 및 AMD와의 협력을 통해 AITER 커널, FP8 실행 경로, 토폴로지 인식 GPU 할당 등을 적용하여 기존 비최적화 환경 대비 처리량을 2배 향상시켰다. 특히 TP8에서 DP2/TP4/EP4 구성으로 전환함으로써 지연 시간 제약 내에서 최대의 QPS를 확보하고 운영 비용을 획기적으로 절감했다. 이러한 성과는 하드웨어와 소프트웨어의 긴밀한 공동 설계를 통해 프로덕션급 AI 인프라를 구축한 결과이다.
배경
LLM 추론 구조 및 지연 시간 지표(TTFT, TPOT), Tensor Parallelism 및 Expert Parallelism 개념, Kubernetes 기반 GPU 오케스트레이션, AMD ROCm 및 vLLM 프레임워크
대상 독자
대규모 LLM 서비스를 운영하는 인프라 엔지니어 및 MLOps 전문가
의미 / 영향
AMD GPU가 엔비디아의 강력한 대안으로 자리 잡고 있음을 입증하며, 특정 하드웨어 토폴로지에 맞춘 소프트웨어 최적화가 클라우드 비용 효율성에 결정적인 영향을 미친다는 점을 시사한다.
섹션별 상세
이미지 분석
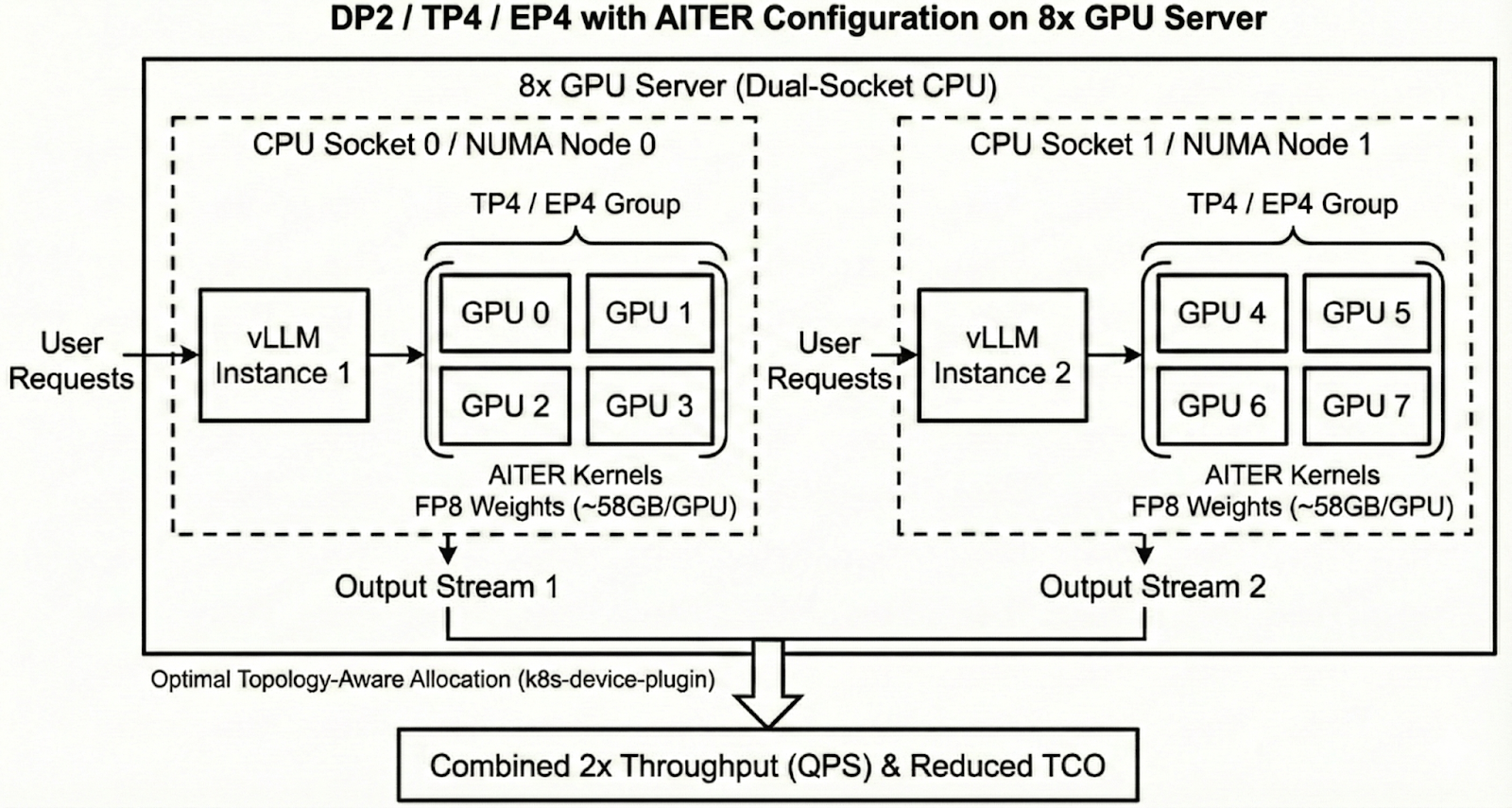
듀얼 소켓 CPU 환경에서 각 NUMA 노드에 vLLM 인스턴스와 4개의 GPU 그룹을 할당하는 최적의 토폴로지를 보여준다. 이 구조는 CPU-GPU 간 통신 지연을 최소화하여 전체 처리량을 2배로 높이는 핵심 아키텍처이다.
8개 GPU 서버에서의 DP2 / TP4 / EP4 및 AITER 구성 다이어그램
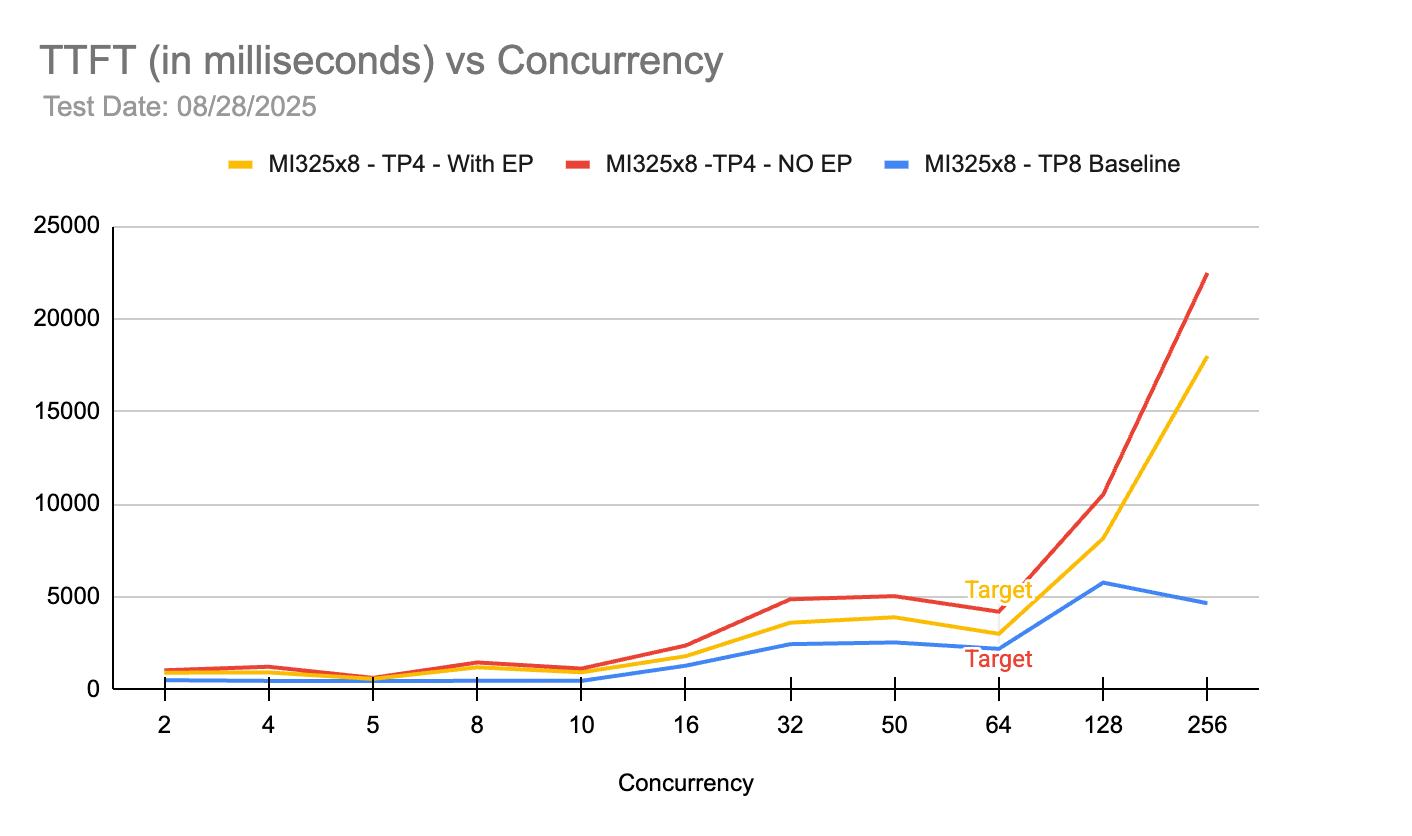
MI325X 기반의 TP4(EP 포함/미포함)와 TP8 베이스라인의 TTFT 성능을 비교한다. 동시성이 증가함에 따라 TP8이 가장 낮은 지연 시간을 유지하지만, TP4 구성도 목표 동시성인 64까지는 허용 범위 내의 성능을 보여준다.
동시성 수준에 따른 TTFT(첫 번째 토큰 생성 시간) 비교 차트
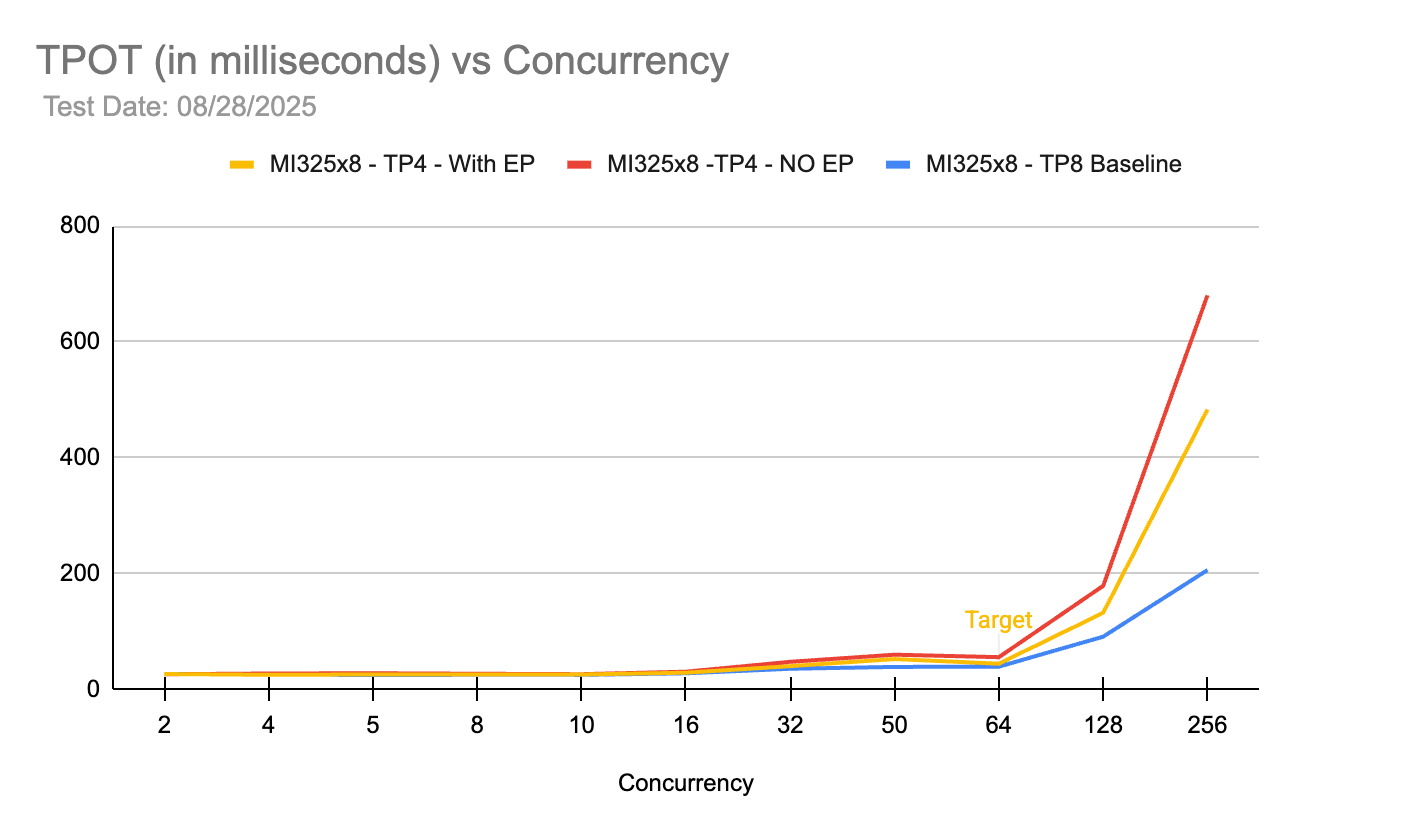
동시성 증가에 따른 디코드 성능 변화를 나타낸다. TP8이 가장 안정적이지만, EP를 적용한 TP4 구성이 EP가 없는 경우보다 훨씬 우수한 성능을 보이며 고부하 환경에서도 효율적임을 입증한다.
동시성 수준에 따른 TPOT(출력 토큰당 시간) 비교 차트
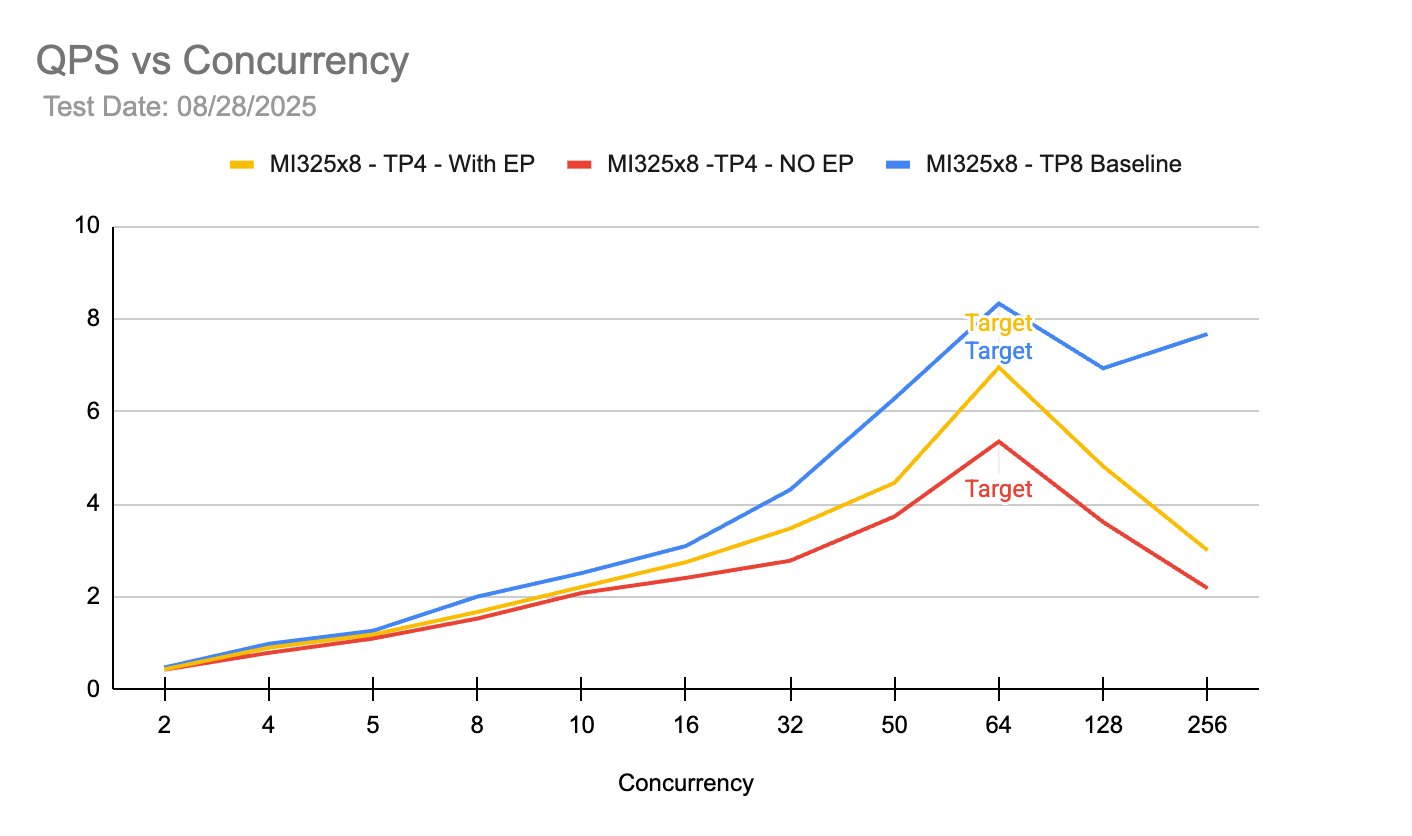
동시성 64 지점에서 TP4 구성이 TP8 베이스라인에 근접하는 QPS를 기록함을 보여준다. 서버당 두 개의 TP4 그룹을 운영할 경우 단일 TP8 그룹보다 훨씬 높은 총 처리량을 달성할 수 있다는 근거를 제시한다.
동시성 수준에 따른 QPS(초당 요청 수) 비교 차트
실무 Takeaway
- FP8 가중치와 FP8 KV 캐시를 함께 사용하면 AMD MI325X의 하드웨어 가속 경로를 유지하여 VRAM 효율과 처리량을 동시에 잡을 수 있다.
- 모델 크기가 허용한다면 TP8보다 DP2/TP4 구성이 통신 오버헤드 감소 덕분에 실제 프로덕션 환경에서 더 높은 QPS를 제공한다.
- 대규모 추론 시스템에서는 NUMA 노드와 xGMI 링크를 고려한 토폴로지 최적화가 지연 시간 안정성에 필수적이다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료