핵심 요약
대규모 AI 모델 학습을 위해 연구자들은 Slurm의 작업 스케줄링 방식을 선호하는 반면, 인프라 팀은 Kubernetes의 복원력과 자동화 기능을 필요로 한다. Character.ai는 이 두 세계를 연결하기 위해 Slurm 노드를 Kubernetes 포드(Pod)로 실행하는 Slonk(Slurm on Kubernetes) 아키텍처를 개발했다. 이 시스템은 NFS 공유 홈 디렉토리와 익숙한 Slurm 명령어를 제공하면서도, 백그라운드에서는 Kubernetes가 노드 상태 관리와 자동 복구를 담당한다. 이를 통해 연구 생산성을 유지하면서도 클라우드 간 이식성과 운영 안정성을 동시에 확보했다.
배경
Kubernetes, Slurm, GPU Infrastructure, HPC
대상 독자
대규모 GPU 클러스터를 운영하는 ML 인프라 엔지니어 및 플랫폼 개발자
의미 / 영향
HPC와 클라우드 네이티브 기술의 결합 모델을 제시함으로써, 기존 Slurm 기반 연구 환경을 현대적인 Kubernetes 생태계로 마이그레이션하려는 기업들에게 실질적인 참조 아키텍처를 제공한다.
섹션별 상세
이미지 분석
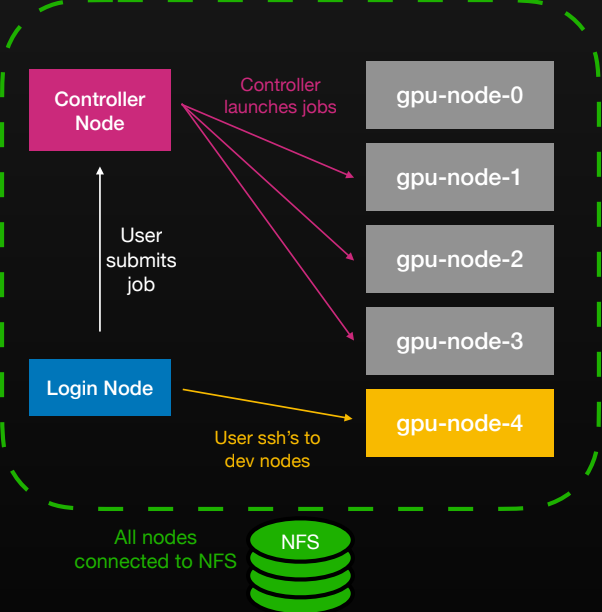
사용자가 Login 노드에 접속하여 작업을 제출하면 Controller 노드가 이를 GPU 노드들에 할당하고, 모든 노드가 NFS에 연결된 구조를 보여준다. Slurm의 전통적인 HPC 워크플로우가 어떻게 구성되는지 시각화한다.
Slonk 시스템의 논리적 작업 흐름 다이어그램
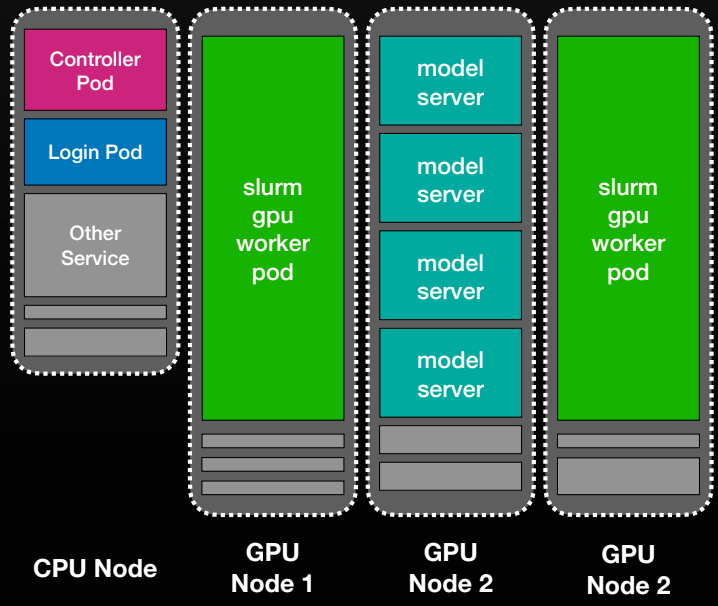
CPU 노드에는 제어 및 로그인 포드가, GPU 노드에는 Slurm 워커 포드와 모델 서버 포드가 공존하는 모습을 보여준다. Slurm 노드가 Kubernetes 포드로 구현되는 방식과 자원 공유 방식을 설명한다.
Kubernetes 노드 내의 Slurm 및 모델 서버 포드 배치 구조
실무 Takeaway
- 연구자용 Slurm 인터페이스와 운영용 Kubernetes 제어 평면을 결합하여 연구 생산성과 인프라 안정성을 동시에 확보할 수 있다.
- GPU 및 네트워크 결함을 자동으로 감지하고 복구하는 Kubernetes 오퍼레이터를 통해 대규모 학습 클러스터의 가동 시간을 극대화한다.
- StatefulSet 복제본 조절과 Kubernetes PriorityClass를 활용하여 학습과 추론 간에 GPU 자원을 유연하게 전환할 수 있다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료