핵심 요약
Character.ai는 대규모 사용자 기반을 지원하기 위해 저지연·고효율 추론 인프라가 필요했다. AMD 및 DigitalOcean과의 협력을 통해 AMD Instinct MI325X GPU 플랫폼에서 Qwen3-235B 모델을 최적화했다. 주요 전략으로 FP8 정밀도 활용, AITER 커널 적용, 그리고 하드웨어 토폴로지를 고려한 DP2/TP4/EP4 병렬화 구성을 도입했다. 그 결과 기존 비최적화 환경 대비 처리량(QPS)을 2배 향상시키고 토큰당 비용을 크게 절감하는 성과를 거두었다.
배경
LLM 병렬화 기법(TP, DP, EP), vLLM 서빙 엔진 구조, 쿠버네티스 인프라 운영 지식
대상 독자
대규모 LLM 서비스를 운영하며 추론 비용 및 성능 최적화가 필요한 MLOps 엔지니어 및 인프라 아키텍트
의미 / 영향
AMD MI300 시리즈 GPU가 엔비디아 위주의 LLM 추론 시장에서 실질적인 대안이 될 수 있음을 입증했다. 특히 소프트웨어 스택(vLLM, ROCm)과 하드웨어 토폴로지 최적화가 결합될 때 TCO를 절반 가까이 낮출 수 있다는 점은 시사하는 바가 크다.
섹션별 상세
이미지 분석
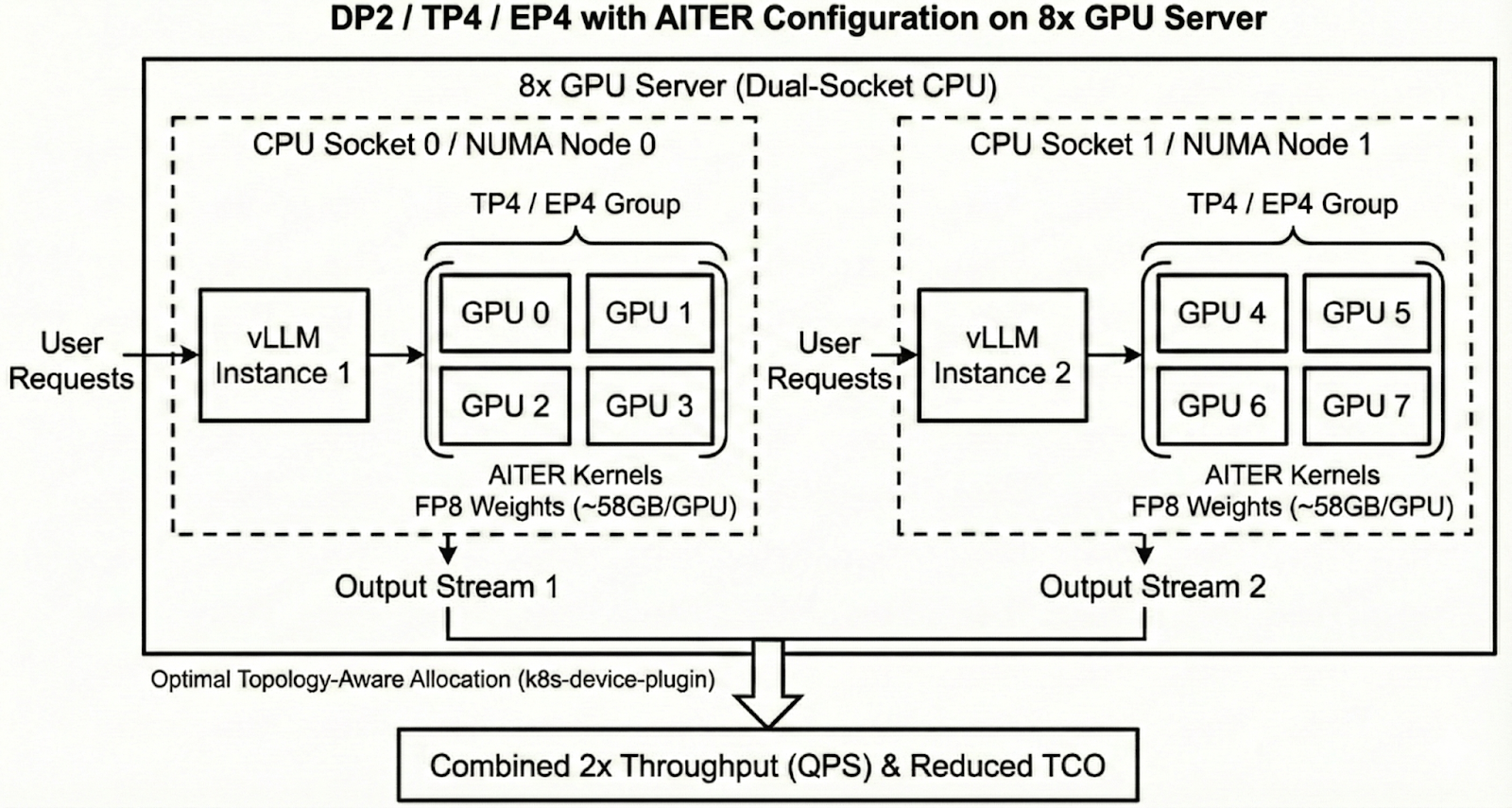
하나의 8개 GPU 서버를 두 개의 NUMA 노드와 CPU 소켓으로 나누고 각 소켓에 vLLM 인스턴스와 4개의 GPU 그룹(TP4/EP4)을 할당한 구조를 보여준다. 이러한 토폴로지 인식 할당을 통해 소켓 간 통신 오버헤드를 줄이고 전체 처리량을 2배로 높이는 메커니즘을 설명한다.
8개 GPU 서버 내 DP2/TP4/EP4 구성의 하드웨어 및 소프트웨어 토폴로지 다이어그램이다.
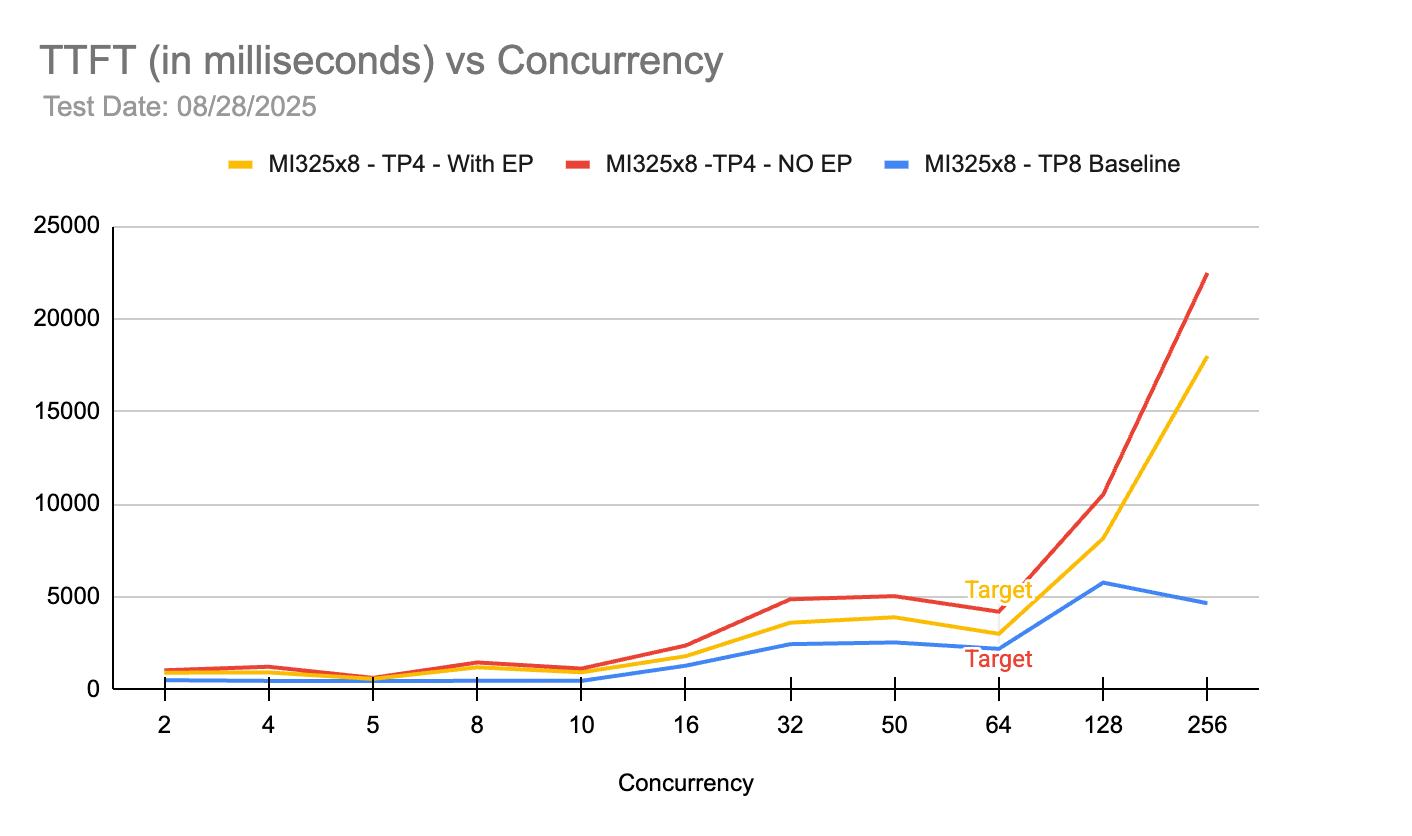
MI325X 환경에서 TP8 베이스라인이 가장 낮은 지연 시간을 유지하지만 TP4 구성(EP 포함 및 미포함)도 목표 동시성인 64까지는 허용 범위 내의 성능을 보여줌을 입증한다. 동시성이 128 이상으로 급증할 때 TP4 구성의 지연 시간이 가파르게 상승하는 특성을 확인할 수 있다.
동시성 수준에 따른 첫 번째 토큰 생성 시간(TTFT) 변화를 비교한 차트이다.
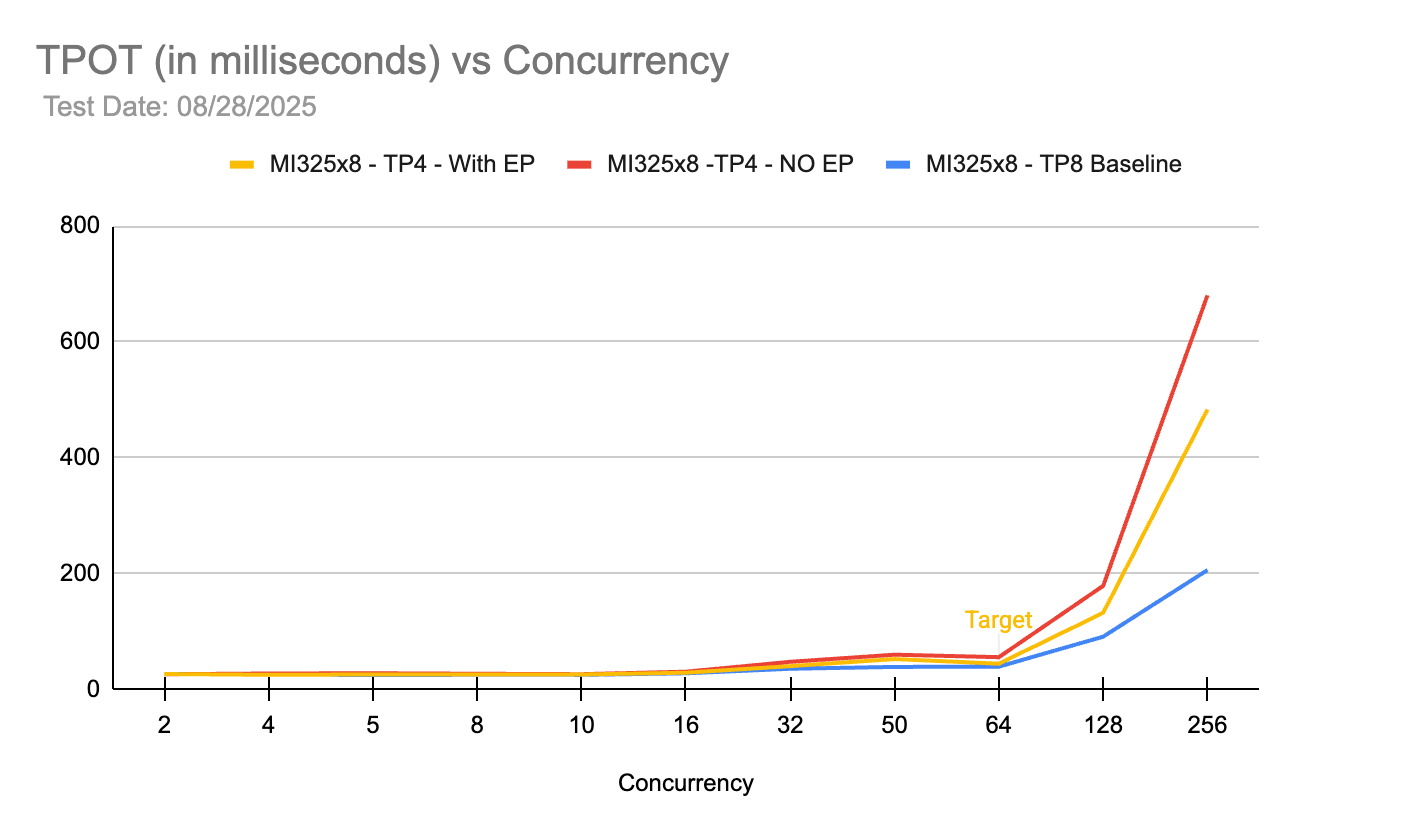
TP8 베이스라인이 가장 안정적인 디코드 성능을 보이며 TP4 구성 중에서는 Expert Parallel(EP)을 적용한 경우가 적용하지 않은 경우보다 높은 동시성에서 더 나은 지연 시간을 유지함을 보여준다. 이는 MoE 모델에서 EP가 통신 효율성을 높여 디코드 속도 저하를 완화함을 시사한다.
동시성 수준에 따른 출력 토큰당 생성 시간(TPOT) 변화를 비교한 차트이다.
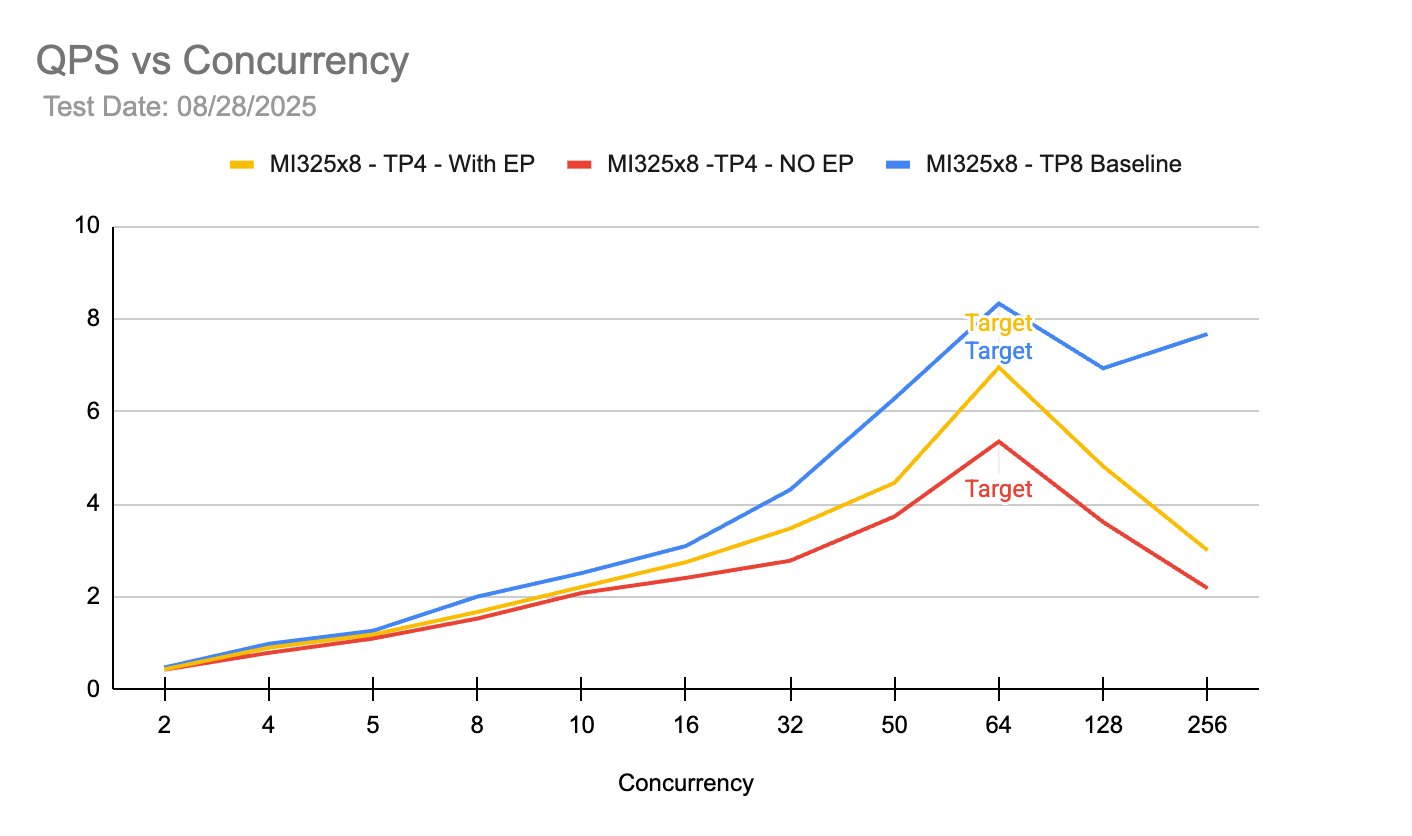
목표 동시성인 64에서 TP4(With EP) 구성이 TP8 베이스라인에 근접하는 높은 처리량을 보여주며 단일 서버 내에서 두 개의 TP4 그룹을 운영할 경우(DP2) 전체 QPS가 TP8 단일 그룹보다 훨씬 높음을 뒷받침한다. 64 동시성 이후에는 모든 구성에서 처리량이 포화되거나 하락하는 양상을 보인다.
동시성 수준에 따른 초당 요청 수(QPS) 변화를 비교한 차트이다.
실무 Takeaway
- MoE 모델 추론 시 단순 TP8보다 하드웨어 토폴로지를 고려한 DP2/TP4/EP4 구성이 처리량(QPS) 면에서 훨씬 유리할 수 있다.
- VRAM 절약과 하드웨어 가속 성능 극대화를 위해 모델 가중치와 KV 캐시 모두에 FP8 정밀도를 적용하는 것이 필수적이다.
- vLLM의 max_num_batched_tokens와 max-model-len을 워크로드 특성에 맞춰 조정함으로써 TTFT와 VRAM 사용량 사이의 최적의 균형점을 찾을 수 있다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료