이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
대형 언어 모델의 컨텍스트 길이가 길어짐에 따라 프리필 단계의 부하가 추론 성능의 병목 현상으로 작용하고 있다. Together AI는 이를 해결하기 위해 캐시 인식 프리필-디코드 분리(CPD) 아키텍처를 개발했다. CPD는 요청의 캐시 재사용 가능성을 판단하여 'Pre-Prefill' 노드와 'Prefill' 노드로 경로를 분리하고, RDMA 기반의 분산 KV 캐시 계층을 도입했다. 이를 통해 무거운 신규 프롬프트 처리가 기존 캐시를 재사용하는 빠른 요청을 방해하지 않도록 격리하여, 실무 환경에서 최대 40%의 처리량 향상과 안정적인 지연 시간을 달성했다.
배경
Transformer 아키텍처 및 Attention 메커니즘 이해, KV Caching 및 Prefill/Decode 단계에 대한 지식, 분산 시스템 및 네트워크(RDMA) 기초 지식
대상 독자
LLM 추론 인프라 최적화 및 대규모 서빙 시스템을 설계하는 엔지니어
의미 / 영향
긴 컨텍스트가 표준이 되는 AI 에이전트 시대에 모델 자체의 효율성만큼이나 시스템 레벨의 스케줄링과 캐시 전략이 중요해짐을 시사한다. CPD와 같은 아키텍처는 추론 비용 절감과 사용자 경험 개선을 동시에 달성할 수 있는 핵심 기술이 될 것이다.
섹션별 상세
기존의 프리필-디코드 분리(PD) 방식은 디코드 지연은 방지하지만, 대규모 신규 프롬프트(Cold)와 캐시 재사용이 가능한 프롬프트(Warm)가 동일한 프리필 자원을 공유하여 병목이 발생한다. CPD는 이를 해결하기 위해 요청의 캐시 히트율을 사전에 추정하여 워크로드를 물리적으로 격리한다.
CPD 아키텍처는 세 가지 역할의 노드로 구성된다. Pre-Prefill 노드는 캐시 재사용률이 낮은 Cold 요청을 처리하고 결과를 분산 캐시에 기록하며, Prefill 노드는 캐시 재사용률이 높은 Warm 요청을 우선 처리한다. Decode 노드는 프리필 간섭 없이 토큰 생성에만 집중한다.

시스템의 핵심은 GPU 메모리, 호스트 DRAM, 클러스터 전체 분산 캐시로 이어지는 3단계 KV 캐시 계층 구조이다. RDMA를 통해 연결된 분산 캐시는 수 초가 걸릴 연산을 수백 밀리초의 데이터 전송으로 대체하며, 자주 사용되는 컨텍스트는 점진적으로 GPU와 가까운 계층으로 이동한다.

캐시 인식 라우터는 각 요청의 프롬프트가 캐시에서 얼마나 제공될 수 있는지 추정하여 최적의 노드로 라우팅한다. 이를 통해 무거운 Cold 프롬프트가 공유 용량을 독점하는 것을 방지하고, Warm 요청을 위한 '빠른 경로'를 상시 유지하여 시스템의 확장성을 높인다.
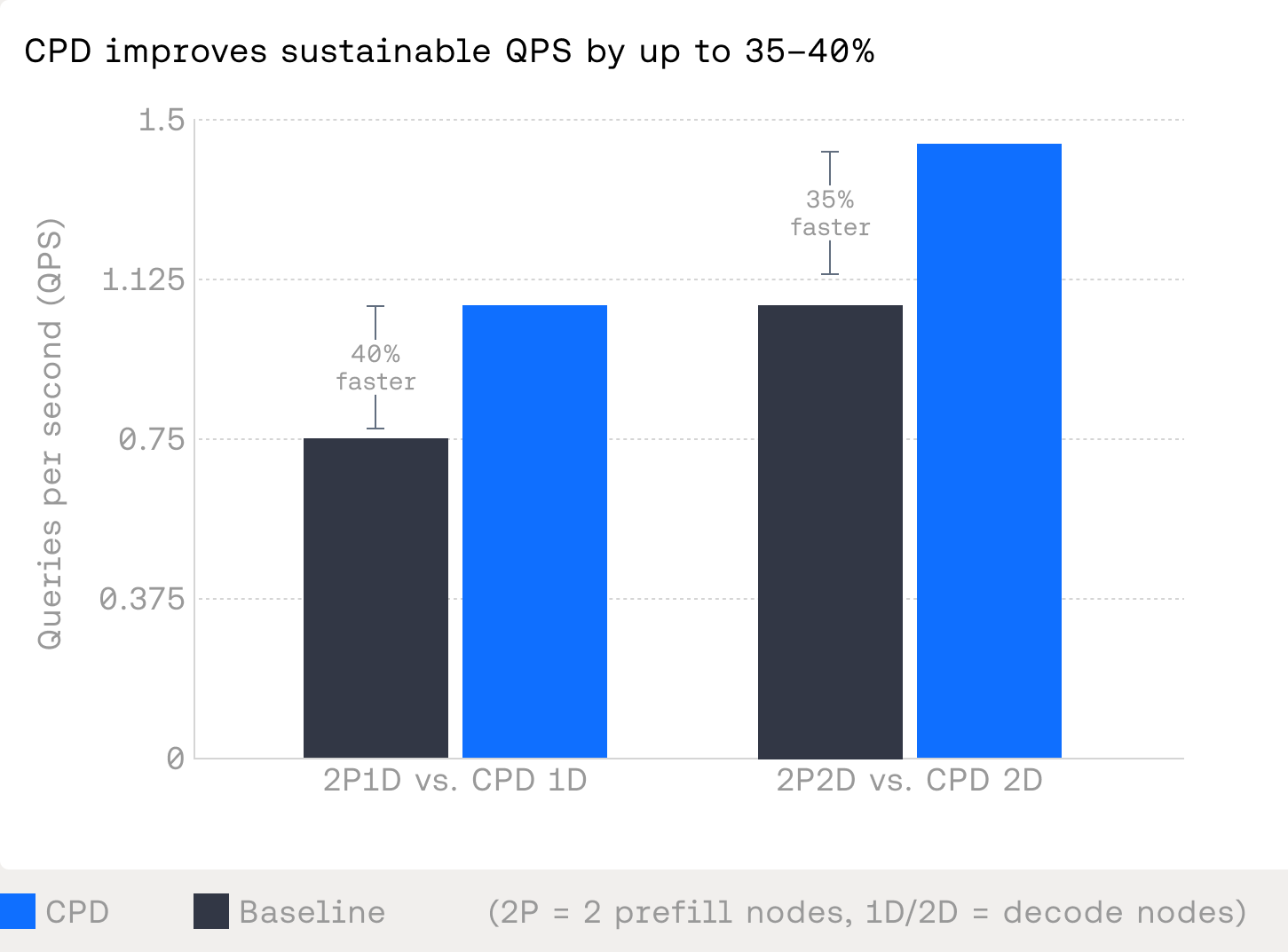
NVIDIA B200 GPU 환경에서 실시한 벤치마크 결과, CPD는 기존 PD 방식 대비 지속 가능한 초당 쿼리 수(QPS)를 35-40% 향상시켰다. 특히 부하가 높은 상황에서도 중간값 TTFT를 1초 미만으로 유지하며 꼬리 지연 시간(p90)을 효과적으로 제어하는 성능을 보였다.

실무 Takeaway
- 시스템 프롬프트나 대화 기록 재사용이 많은 RAG 및 에이전트 서비스에 CPD 아키텍처를 적용하면 동일 자원 대비 처리량을 최대 40% 늘릴 수 있다.
- 무거운 신규 입력(Cold)과 캐시 재사용 입력(Warm)을 물리적으로 격리함으로써, 특정 사용자의 대량 입력이 다른 사용자의 응답 속도를 저하시키는 간섭 현상을 방지할 수 있다.
- RDMA 기반의 분산 KV 캐시 계층을 구축하면 연산 집약적인 프리필 과정을 고대역폭 데이터 전송으로 대체하여 TTFT를 획기적으로 단축할 수 있다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 02. 11.수집 2026. 02. 21.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.