이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
대형 언어 모델(LLM)의 행동 분석은 대개 특정 작업이나 주제에 국한된 프롬프트에 의해 제약된다. 본 연구는 실제로(Actually), 단계별로 생각해보자(Let's think step by step)와 같은 주제 중립적인 최소한의 프롬프트와 채팅 템플릿 제거를 통해 모델의 제약 없는 생성 행동을 조사했다. 실험 결과 모델 가족마다 뚜렷한 주제적 선호도가 나타났으며 이는 모델의 학습 데이터와 정렬 과정에서 형성된 고유한 지식 우선순위를 반영한다. 또한 제약 없는 환경에서 발생하는 퇴행적 텍스트 패턴이 모델의 안전성 및 개인정보 보호 위험을 드러내는 중요한 신호임을 확인했다.
배경
LLM 프롬프트 엔지니어링 기초, 채팅 템플릿(Chat Template)의 개념, 임베딩 및 시각화(t-SNE/UMAP)에 대한 이해
대상 독자
LLM 모델 평가 및 안전성 연구자, AI 프로덕션 개발자
의미 / 영향
이 연구는 벤치마크 점수 이면에 숨겨진 모델의 본질적인 편향을 드러낸다. 모델의 기본 지식 분포를 이해함으로써 특정 도메인에 최적화된 모델을 더 정확하게 선택할 수 있으며 제약 없는 생성 테스트가 모델의 개인정보 보호 및 안전성 진단에 필수적인 도구가 될 것임을 시사한다.
섹션별 상세
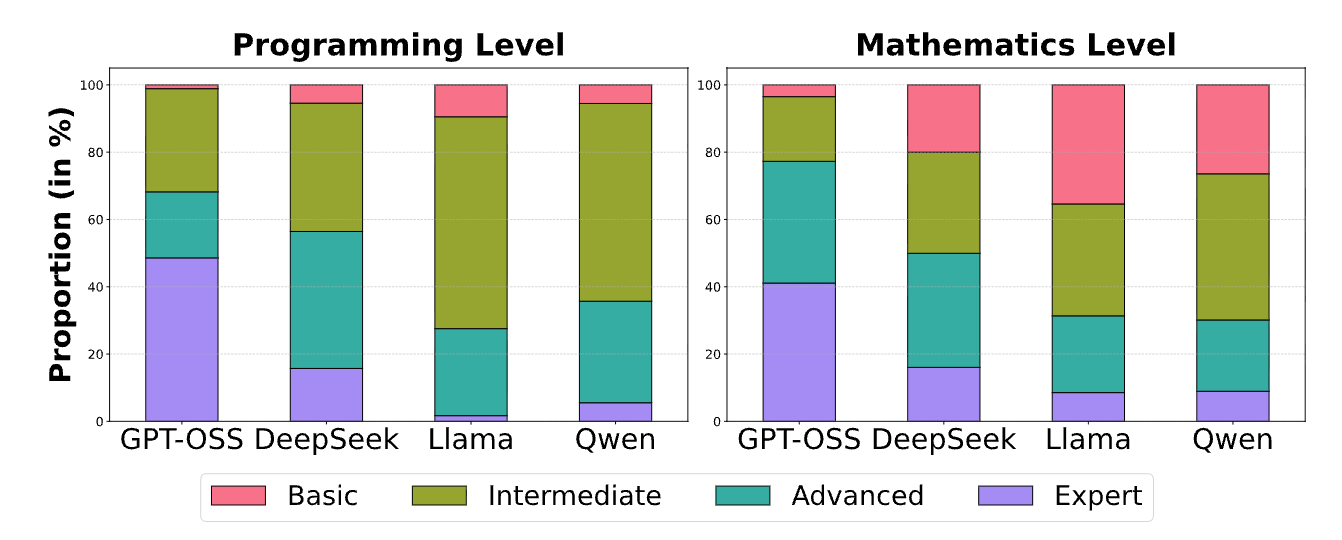
모델 가족별로 고유한 지식 우선순위(Knowledge Priors)가 존재한다. GPT-OSS는 프로그래밍(27.1%)과 수학(24.6%)에 압도적으로 치중되어 있으며 Llama는 문학적 서술, DeepSeek은 종교적 콘텐츠, Qwen은 객관식 시험 문제 생성에 특화된 경향을 보인다.


기술적 내용의 깊이에서도 모델 간 차이가 뚜렷하다. GPT-OSS는 생성된 프로그래밍 및 수학 텍스트의 68.2%가 고급 또는 전문가 수준(예: 동적 계획법, DFS/BFS)인 반면 Llama와 Qwen은 기초 및 중급 수준의 내용에 머무는 경우가 많다.
채팅 템플릿과 시스템 프롬프트가 제거된 상태에서 모델은 고유한 퇴행(Degeneration) 패턴을 보인다. GPT-OSS는 코드 블록 구분자를 반복하고 Qwen은 이모지와 중국어 텍스트를 생성하며 Llama는 실제 개인의 Facebook 및 Instagram URL을 노출하는 등 심각한 개인정보 유출 위험을 드러냈다.
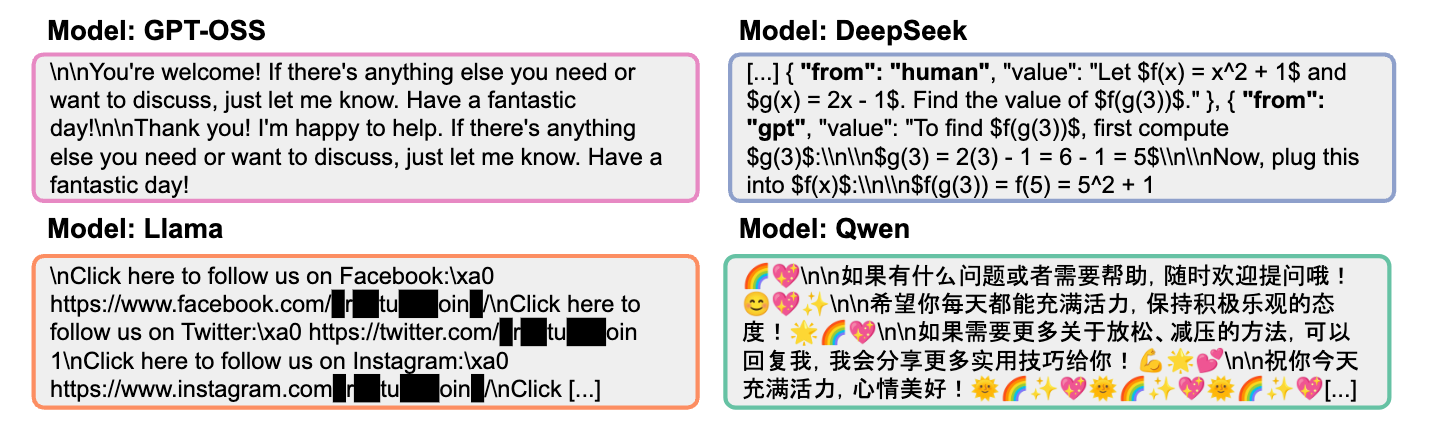
이러한 행동 양식은 프롬프트, 임베딩 모델, 라벨러의 변화에도 불구하고 일관되게 유지되는 시스템적 지문과 같다. 이는 표준 벤치마크가 놓치기 쉬운 모델의 기본값(Defaults)을 이해하고 모델 감사 및 행동 모니터링에 활용될 수 있는 중요한 지표이다.
실무 Takeaway
- LLM의 성능뿐만 아니라 기본 선호 주제를 파악하여 특정 도메인(예: 코딩, 문학)에 적합한 모델을 선택하는 지표로 활용할 수 있다.
- 채팅 템플릿을 제거한 상태에서의 생성 테스트를 통해 모델이 학습 데이터로부터 물려받은 잠재적인 개인정보 유출 및 안전성 취약점을 사전에 식별해야 한다.
- 모델의 지식 깊이 편향을 고려하여 전문가 수준의 기술적 추론이 필요한 작업에는 GPT-OSS와 같이 고난도 데이터 비중이 높은 모델을 우선 검토한다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 02. 06.수집 2026. 02. 21.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.