핵심 요약
의료 및 고객 서비스와 같은 특정 도메인에서 범용 ASR 모델의 정확도를 높이기 위해 NVIDIA Nemotron Speech 모델인 Parakeet-TDT-0.6b-V2를 파인튜닝하는 방법을 다룬다. LLM과 TTS를 결합한 합성 데이터 생성 파이프라인을 통해 의료 전문 용어와 다양한 소음 환경을 학습 데이터로 구축했다. Amazon EC2 P4d 인스턴스와 DeepSpeed를 사용하여 64개의 GPU에서 분산 학습을 수행하며, 최종 모델은 Amazon EKS와 FSx for Lustre를 통해 고성능 추론 환경에 배포된다. 이 아키텍처는 데이터 합성부터 분산 학습, 탄력적 추론 및 관측성 확보까지의 전 과정을 포괄한다.
배경
NVIDIA NeMo 프레임워크에 대한 기본 지식, PyTorch 기반 분산 학습 및 DeepSpeed 개념, Amazon EKS 및 Kubernetes 운영 경험, Docker 및 컨테이너화 기술
대상 독자
도메인 특화 ASR 시스템을 구축하려는 ML 엔지니어 및 클라우드 아키텍트
의미 / 영향
범용 모델이 해결하기 어려운 전문 도메인(의료, 법률 등)의 음성 인식 문제를 합성 데이터와 클라우드 기반 분산 학습으로 해결할 수 있음을 입증했다. 특히 오픈소스 프레임워크(NeMo, DeepSpeed)와 관리형 서비스(EKS, FSx)의 결합은 기업이 독자적인 고성능 AI 서비스를 구축하는 표준 아키텍처가 될 것이다.
섹션별 상세
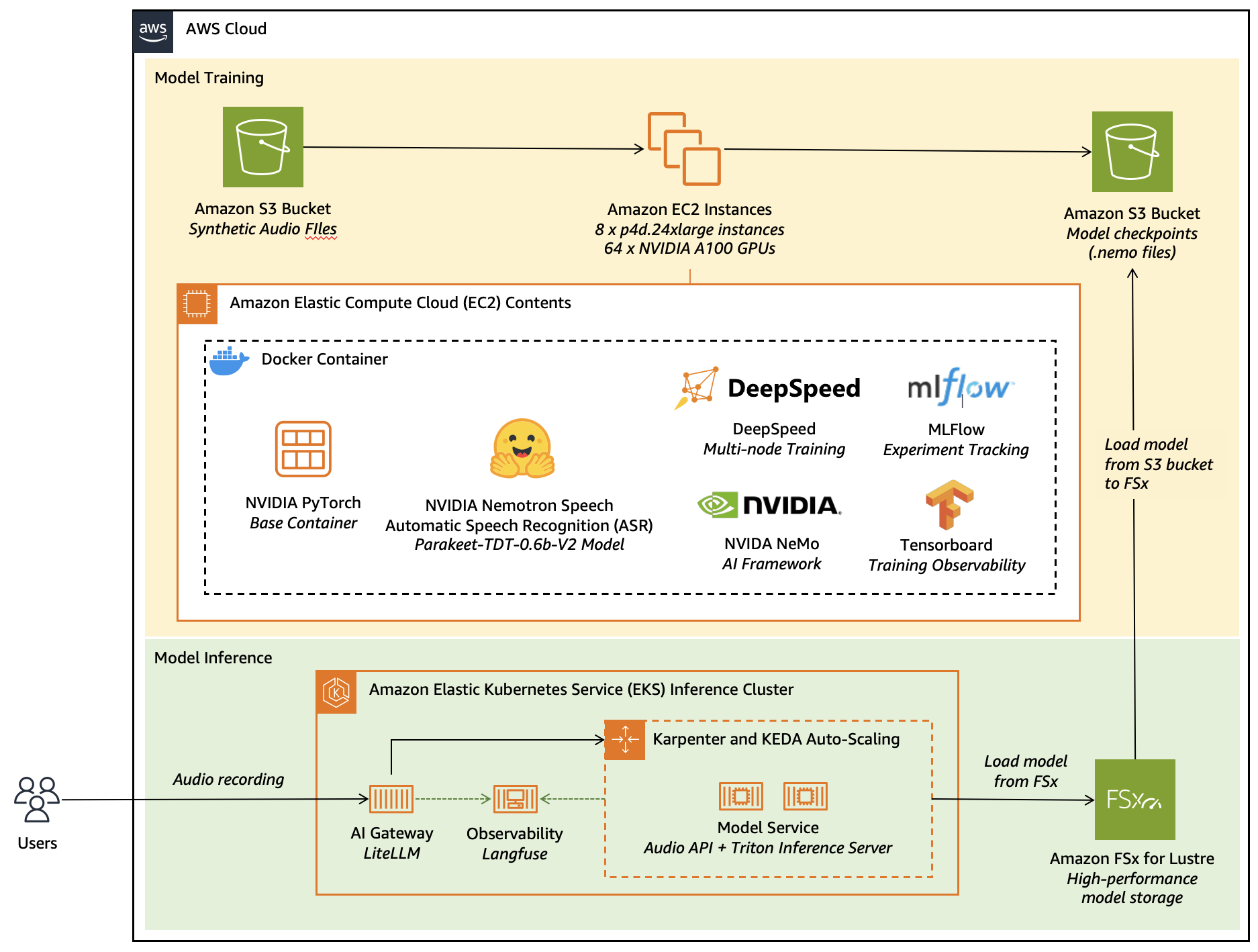
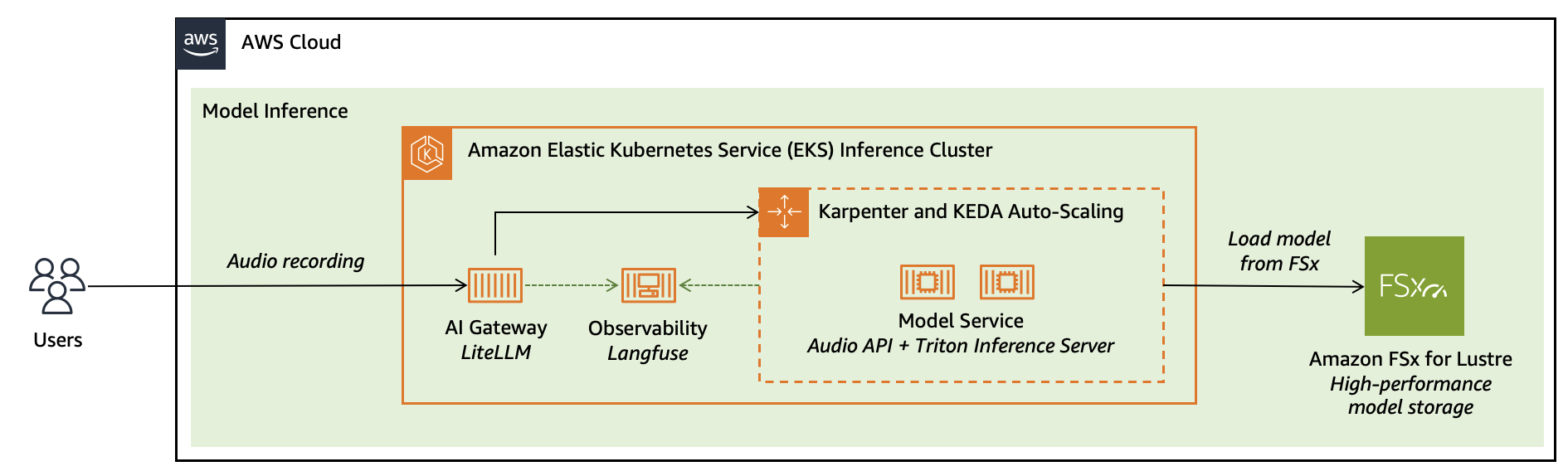

실무 Takeaway
- 의료 전문 용어와 같이 데이터가 부족한 도메인은 LLM과 TTS를 활용한 합성 데이터 생성 파이프라인을 통해 개인정보 노출 없이 학습 데이터를 확장할 수 있다.
- DeepSpeed Stage 2와 EC2 P4d 인스턴스를 조합하면 600M 규모의 ASR 모델을 64개 GPU에서 효율적으로 분산 학습하여 실험 주기를 며칠에서 몇 시간 단위로 단축 가능하다.
- EKS 배포 시 FSx for Lustre를 공유 스토리지로 활용하면 대용량 모델 가중치 로딩 속도를 최적화하고 컨테이너 관리 효율성을 높일 수 있다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.