핵심 요약
대형 언어 모델(LLM)의 추론 비용과 지연 시간을 줄이기 위해 추측 디코딩이 널리 사용되지만, 드래프트 모델과 타겟 모델의 토큰이 단 하나라도 다르면 이후 토큰을 모두 폐기하는 엄격한 검증 방식이 병목으로 작용한다. AutoJudge는 최종 답변의 품질을 해치지 않는 '무해한 불일치'를 식별하여 수용하는 손실(Lossy) 추측 디코딩 기법을 제안한다. 수동 레이블링 없이 자가 학습된 소형 분류기를 통해 각 토큰의 중요도를 실시간으로 판단하며, 이를 통해 검증 주기당 수용 토큰 수를 대폭 늘려 1.5~2배의 속도 향상을 달성한다. 수학 연산이나 코딩과 같이 정확도가 중요한 태스크에서도 최소한의 성능 저하로 높은 효율을 보여주며 기존 추론 프레임워크에 쉽게 통합된다.
배경
Speculative Decoding의 기본 원리, Transformer 아키텍처 및 Hidden State 개념, LLM 추론 최적화 프레임워크(vLLM 등)에 대한 이해
대상 독자
LLM 추론 인프라 최적화 엔지니어 및 AI 서비스 개발자
의미 / 영향
LLM 추론의 고질적인 문제인 지연 시간과 비용을 정확도와의 미세한 트레이드오프를 통해 해결하는 실용적인 방법론을 제시한다. 특히 특정 도메인에서 자동화된 최적화가 가능함을 보여줌으로써 대규모 모델 서비스의 경제성을 크게 개선할 것으로 기대된다.
섹션별 상세
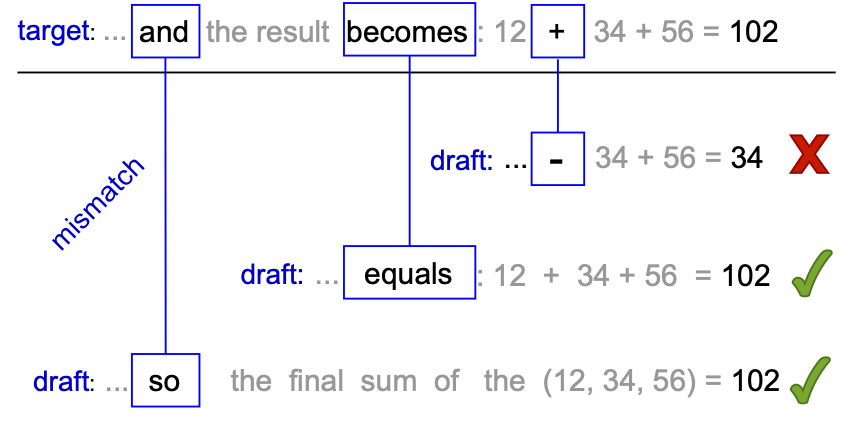
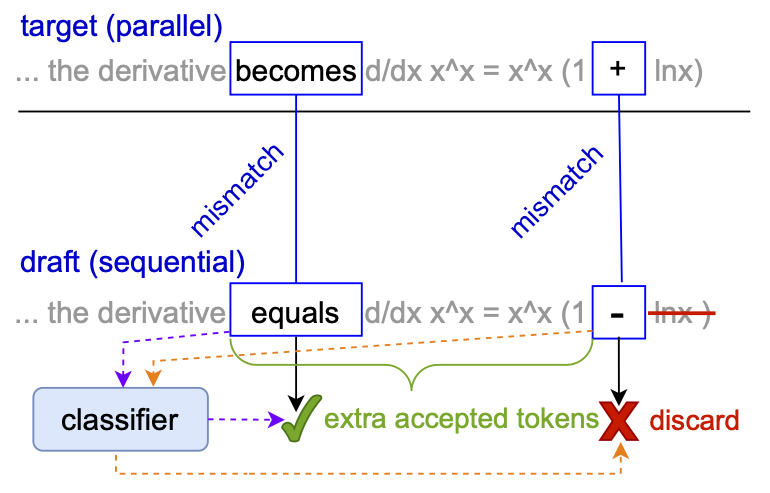

실무 Takeaway
- 최종 결과의 무결성이 중요한 RAG나 코딩 에이전트 시스템에 AutoJudge를 적용하면 정확도 저하를 1~3% 이내로 유지하면서 추론 속도를 1.5배 이상 가속할 수 있다.
- 수동 데이터 제작 없이 자가 학습 방식으로 특정 도메인에 특화된 판독기(Judge)를 구축하여 추측 디코딩의 수용률(Acceptance Rate)을 최적화할 수 있다.
- 네트워크 대역폭이 제한된 분산 추론 환경에서 AutoJudge의 높은 토큰 수용 능력을 활용하면 전체 시스템의 지연 시간을 획기적으로 단축할 수 있다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.