핵심 요약
Together AI는 차세대 GPU 하드웨어와 최적화된 커널, Speculative Decoding 기법을 결합하여 오픈소스 LLM 추론 속도를 대폭 향상시켰다. Artificial Analysis 벤치마크 결과, GPT-OSS-20B와 Qwen3-235B 등 주요 모델에서 타사 대비 최대 2.75배 빠른 성능을 보이며 업계 1위를 차지했다. 이러한 성과는 NVIDIA Blackwell 아키텍처에 최적화된 엔진과 고성능 Draft Model 학습 파이프라인 구축을 통해 가능해졌다. 향후 하이브리드 양자화 및 새로운 생성 전략을 통해 성능 격차를 더욱 벌릴 계획이다.
배경
LLM 추론 메커니즘 (Token generation), 양자화 (Quantization) 개념 (FP8, FP4), Speculative Decoding의 기본 원리
대상 독자
실시간 응답 속도가 중요한 LLM 서비스를 운영하는 개발자 및 인프라 엔지니어
의미 / 영향
Together AI가 오픈소스 모델 추론 시장에서 압도적인 속도 우위를 점함에 따라, 기업들이 폐쇄형 모델 대신 고성능 오픈소스 모델을 선택할 유인이 더 커졌다. 특히 Blackwell 하드웨어의 잠재력을 풀스택 최적화로 끌어올린 사례는 향후 AI 인프라 경쟁의 기준점을 높이는 계기가 될 것이다.
섹션별 상세
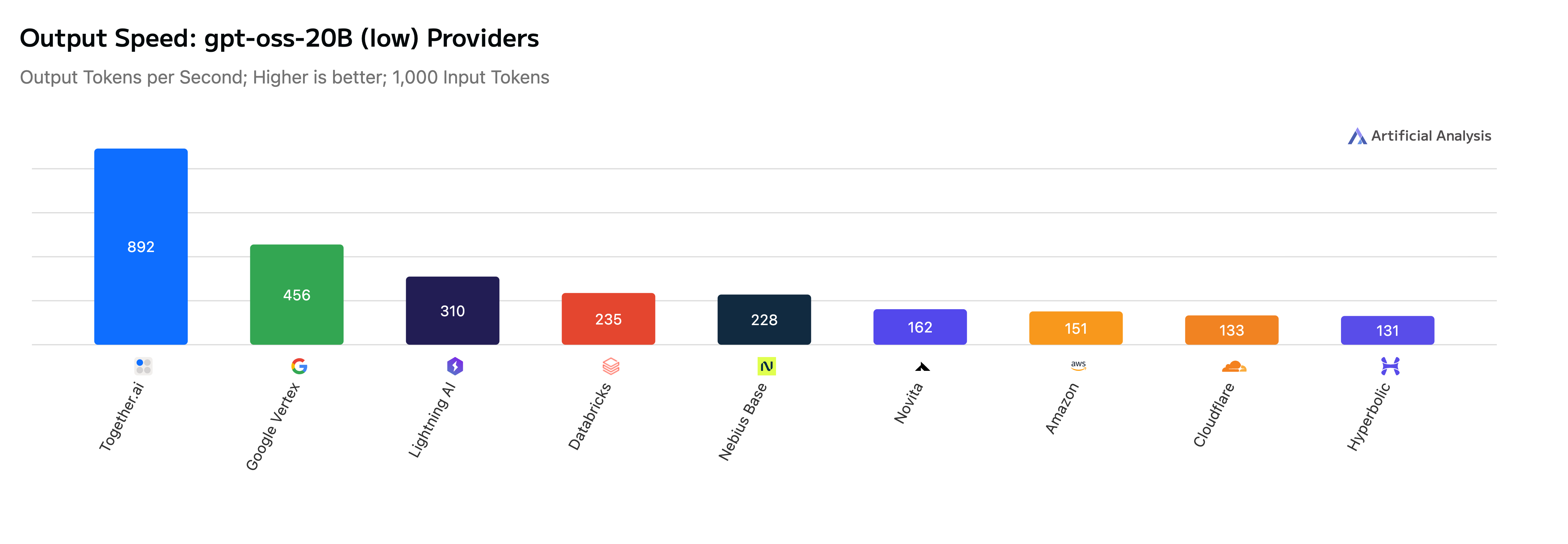

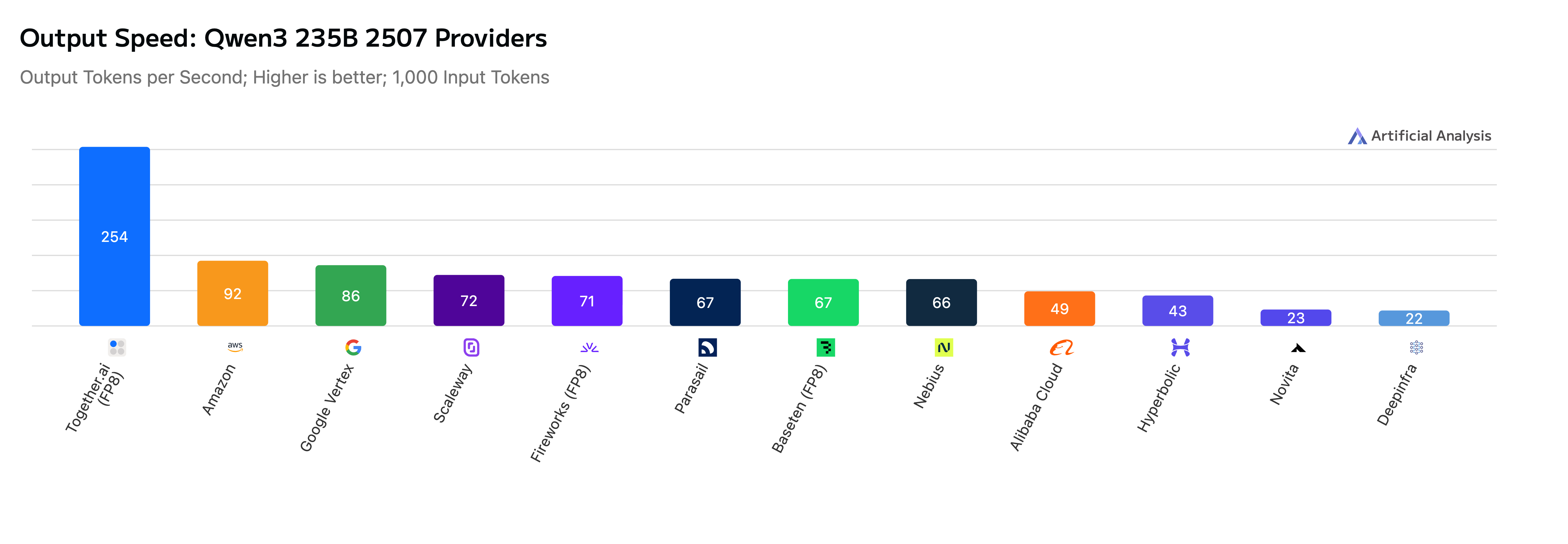

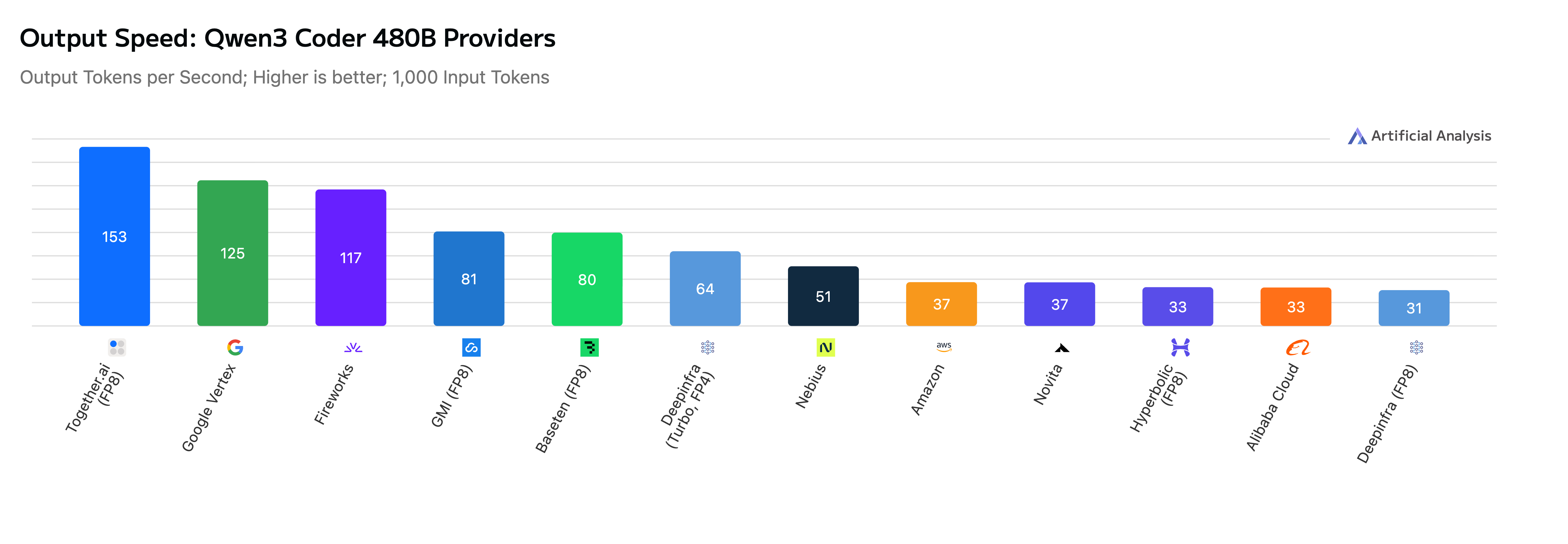
실무 Takeaway
- NVIDIA Blackwell 하드웨어에 최적화된 전용 커널과 FP4 양자화를 적용하면 대규모 모델의 추론 처리량을 획기적으로 높일 수 있다.
- 고성능 Draft Model을 활용한 Speculative Decoding은 Qwen3와 같은 대형 모델의 실시간 출력 속도를 최대 2.75배까지 가속화하는 핵심 기술이다.
- Together AI의 서버리스 인프라를 활용하면 DeepSeek-V3.1이나 R1 같은 최신 모델을 업계에서 가장 빠른 속도로 서비스에 도입할 수 있다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.