핵심 요약
SWE-bench 리더보드가 2026년 2월 최신 모델들을 대상으로 업데이트되었다. 이번 평가는 연구소의 자체 보고가 아닌 공식적인 전체 실행 결과로, 실제 오픈소스 프로젝트의 코딩 문제를 해결하는 능력을 측정했다. Claude 4.5 Opus가 76.8%로 1위를 기록했으며, Gemini 3 Flash와 중국의 MiniMax M2.5가 그 뒤를 이었다. 특히 상위 10개 모델 중 다수가 중국계 모델이며, OpenAI의 GPT-5.2는 6위에 머무르는 등 모델 간 경쟁 구도의 변화가 확인되었다.
배경
SWE-bench 벤치마크에 대한 기본 이해, LLM 성능 지표 해석 능력
대상 독자
AI 모델 성능을 추적하는 개발자 및 코딩 에이전트 연구자
의미 / 영향
이번 결과는 코딩 보조 도구 시장에서 Anthropic의 우위를 확인시켜 주는 동시에, 중국 모델들의 급격한 성장을 경고하고 있다. 또한 브라우저 기반 AI 에이전트가 단순 정보 검색을 넘어 웹 인터페이스를 능동적으로 수정하는 실무 도구로 진화하고 있음을 보여준다.
섹션별 상세
이미지 분석
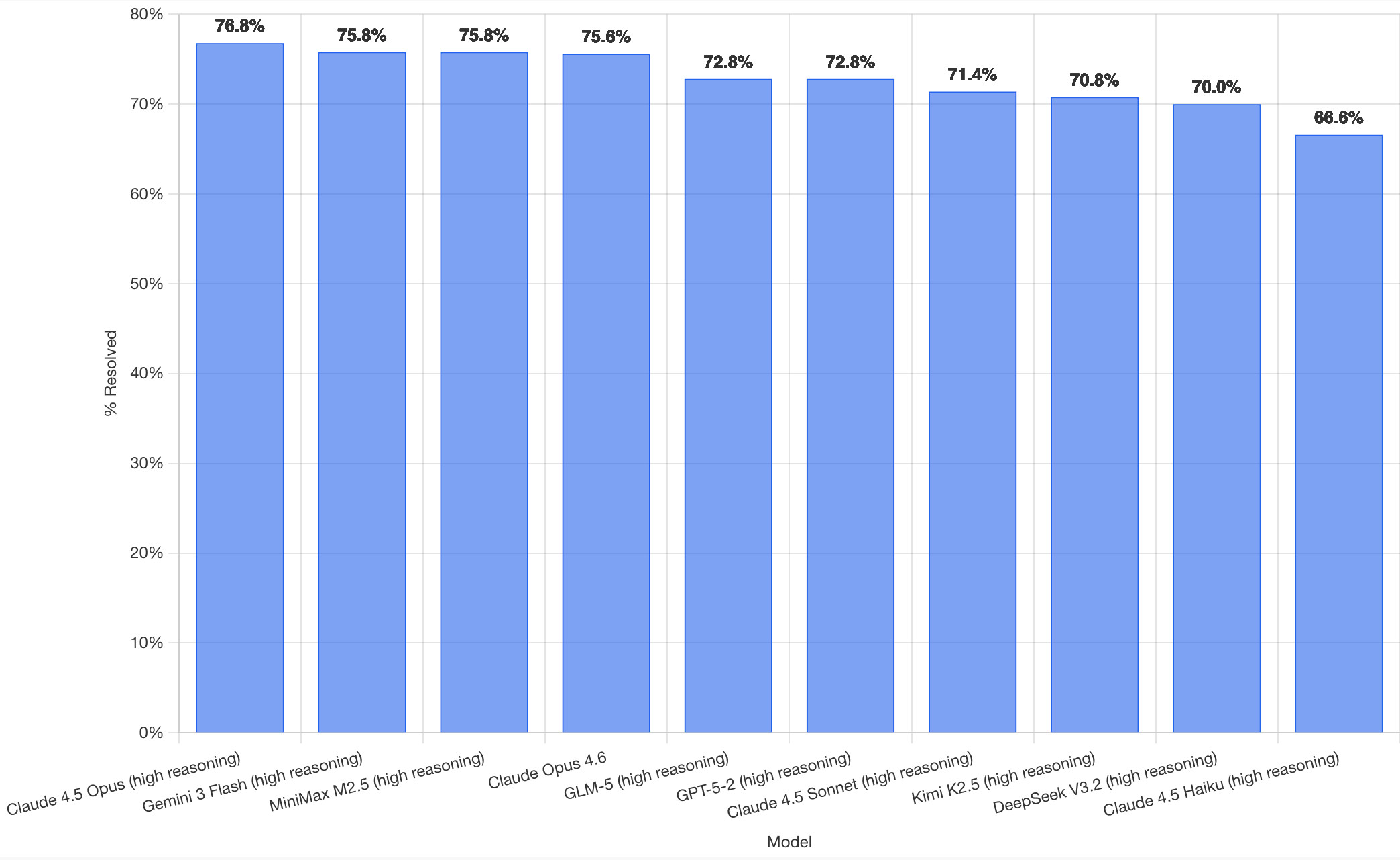
Claude 4.5 Opus가 76.8%로 1위이며, Gemini 3 Flash와 MiniMax M2.5가 뒤를 잇고 있음을 시각적으로 보여준다. 기사에서 언급된 수치 라벨이 Claude를 통해 추가된 결과물이다.
2026년 2월 SWE-bench Verified 리더보드 상위 모델들의 해결률을 보여주는 막대 그래프.

Claude가 차트의 캔버스 컨텍스트에 접근하여 수치 라벨을 그리는 JS 코드를 생성하고 실행하는 과정을 보여준다. 브라우저 에이전트의 실질적인 활용 능력을 증명하는 증거다.
Claude for Chrome을 사용하여 웹 페이지에 자바스크립트를 주입하는 과정을 담은 스크린샷.
실무 Takeaway
- Claude 4.5 Opus가 현재 가용한 API 모델 중 가장 강력한 코딩 문제 해결 능력을 보유하고 있다.
- MiniMax, DeepSeek 등 중국계 LLM들이 코딩 벤치마크 상위권을 점령하며 기술 격차를 좁히고 있다.
- 브라우저 에이전트를 활용하면 웹 페이지의 DOM을 조작하거나 JS를 주입하여 필요한 데이터를 즉시 추출 및 시각화할 수 있다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료