핵심 요약
Monday.com은 자사의 AI Native ESM 플랫폼인 'monday Service'를 구축하며 평가를 개발 초기 단계부터 도입했다. LangGraph 기반의 ReAct 에이전트가 가진 불확실성을 해결하기 위해 오프라인과 온라인의 이중 레이어 평가 전략을 수립했다. 특히 Vitest와 LangSmith를 통합하여 평가 속도를 8.7배 향상시켰으며, 모든 평가 로직을 코드로 관리하는 Evaluations as Code(EaC) 체계를 구축하여 안정적인 프로덕션 운영을 실현했다. 이 프레임워크는 수백 개의 사례를 몇 분 만에 테스트하고 실시간으로 멀티턴 대화의 품질을 모니터링할 수 있게 한다.
배경
LangChain 및 LangGraph 프레임워크에 대한 이해, LLM-as-a-judge 개념 및 평가 방법론, Vitest 등 JavaScript/TypeScript 테스트 프레임워크 사용 경험, CI/CD 및 GitOps 워크플로우 지식
대상 독자
프로덕션 환경에서 LLM 에이전트를 구축하고 평가 체계를 자동화하려는 엔지니어 및 팀장
의미 / 영향
이 사례는 LLM 에이전트의 신뢰성을 확보하기 위해 소프트웨어 공학의 테스트 원칙을 AI 개발에 어떻게 이식해야 하는지 보여준다. 특히 평가 속도 개선과 코드 기반 관리 방식은 대규모 엔터프라이즈 환경에서 AI 서비스를 안정적으로 운영하기 위한 표준 모델이 될 것으로 예상된다.
섹션별 상세
이미지 분석
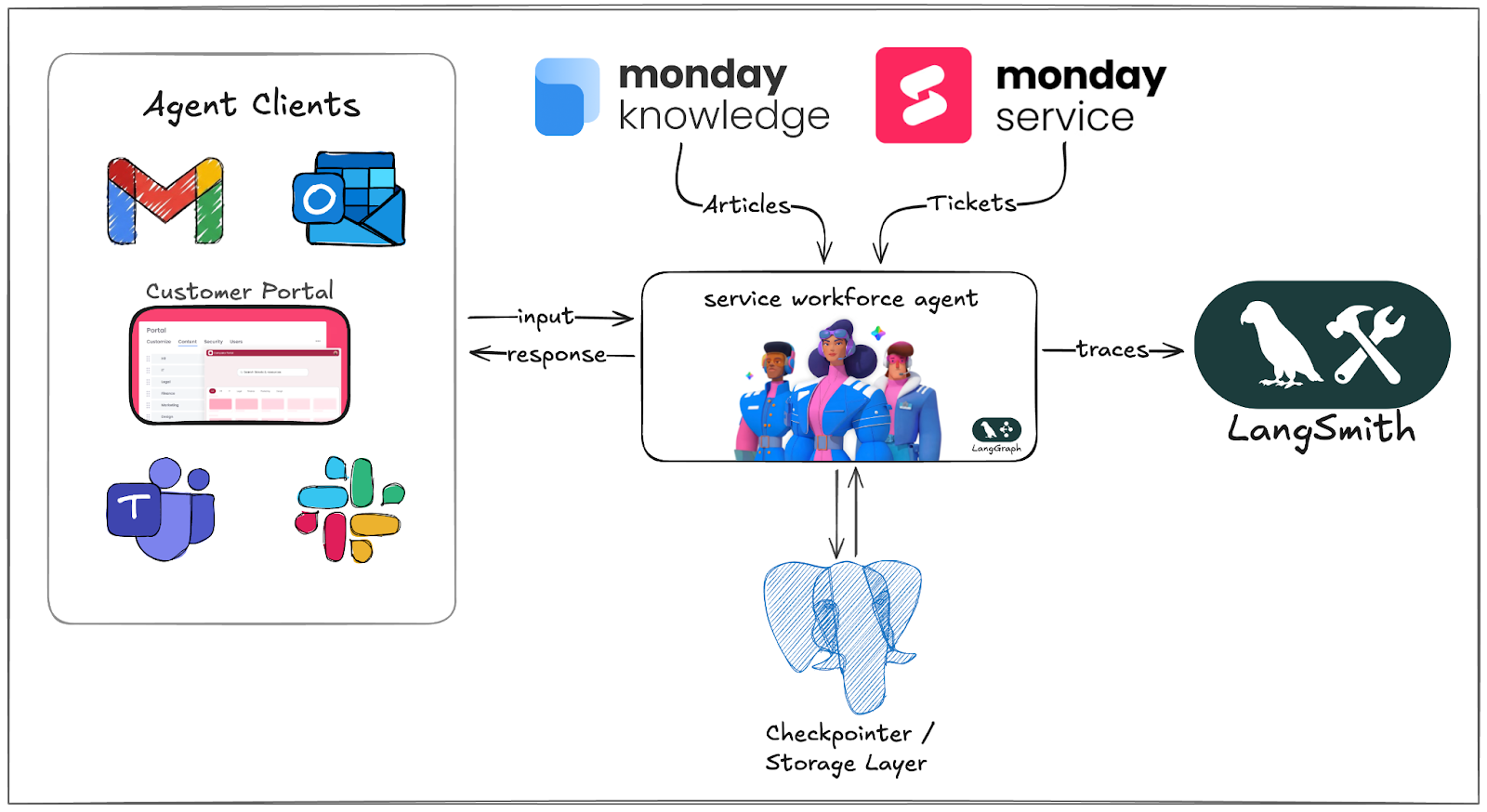
에이전트 클라이언트(이메일, 슬랙 등)로부터 입력을 받아 LangGraph 기반 에이전트가 지식 베이스와 티켓 시스템을 활용해 응답하는 구조를 보여준다. 모든 트레이스는 LangSmith로 전송되어 모니터링되며, 체크포인터 레이어를 통해 대화 상태가 유지됨을 명시한다.
monday Service 에이전트의 전체 시스템 아키텍처 다이어그램
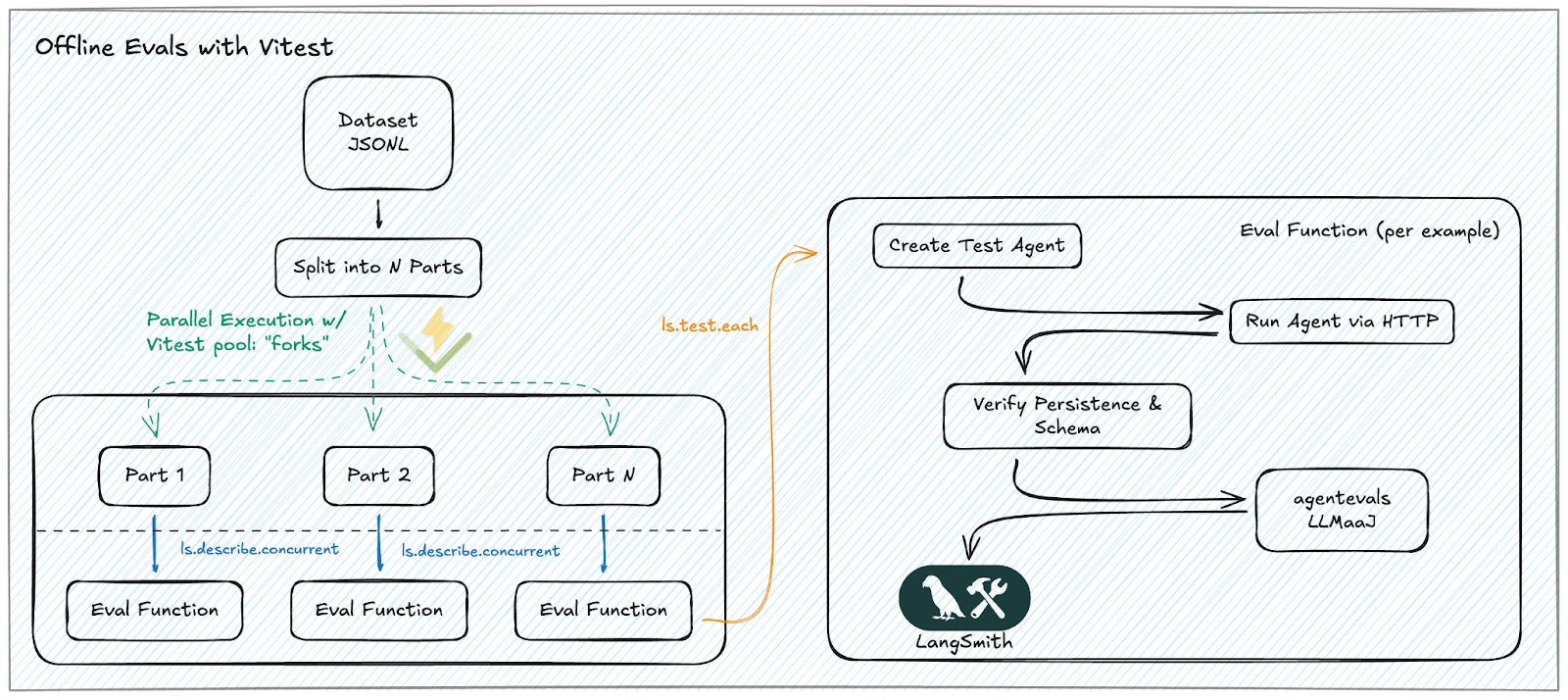
JSONL 데이터셋을 N개로 분할하여 Vitest의 병렬 풀에서 실행하고, 각 평가 함수가 에이전트를 호출한 뒤 LangSmith에 결과를 기록하는 과정을 단계별로 설명한다. 병렬 처리를 통해 평가 속도를 획기적으로 높이는 핵심 메커니즘을 시각화했다.
Vitest를 활용한 오프라인 평가 워크플로우 상세도
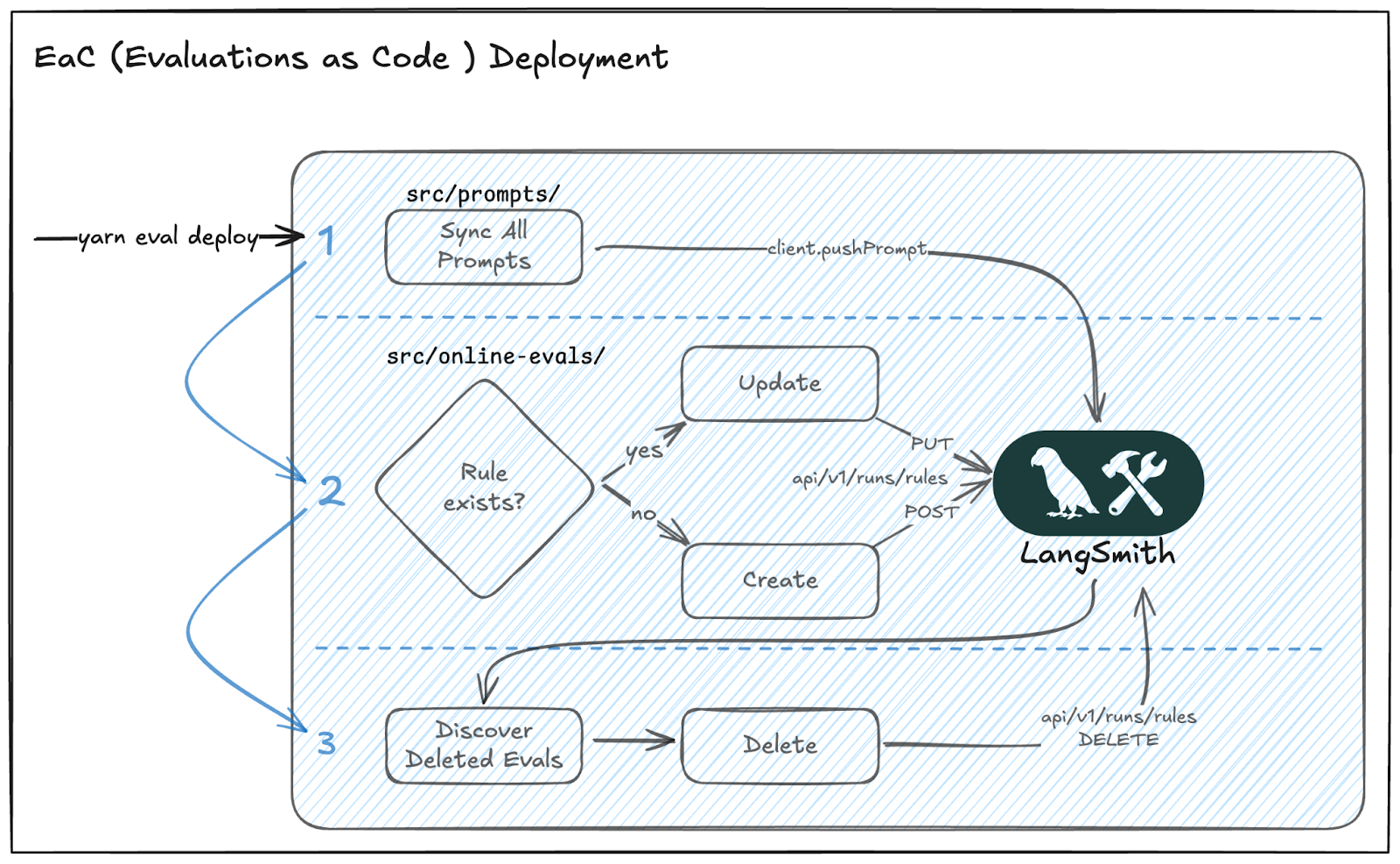
yarn eval deploy 명령어를 통해 프롬프트 동기화, 규칙 생성/업데이트, 삭제된 평가 항목 정리의 3단계 조정 루프가 수행되는 과정을 보여준다. 코드 저장소를 최종 소스 오브 트루스로 유지하는 GitOps 방식의 배포 전략을 설명한다.
Evaluations as Code(EaC) 배포 프로세스 다이어그램
실무 Takeaway
- 평가를 개발 마지막 단계가 아닌 초기 설계(Day 0)부터 포함시켜 품질 격차를 사전에 방지해야 한다.
- CPU 병렬화와 I/O 비동기 처리를 결합한 하이브리드 접근법으로 LLM 평가 지연 시간을 85% 이상 절감할 수 있다.
- 평가 로직을 코드로 관리(EaC)함으로써 인프라의 일관성을 유지하고 GitOps 워크플로우를 AI 개발에 적용할 수 있다.
- 단일 응답 평가를 넘어 전체 대화 궤적을 분석하는 멀티턴 평가가 실제 비즈니스 가치 측정에 필수적이다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료