핵심 요약
코딩 에이전트의 성능은 모델 자체의 지능뿐만 아니라 이를 둘러싼 시스템인 하네스(Harness) 설계에 크게 의존한다. LangChain 팀은 GPT-5.2-Codex 모델을 고정한 채 시스템 프롬프트, 도구, 미들웨어를 최적화하는 하네스 엔지니어링을 통해 Terminal Bench 2.0 리더보드 5위에 올랐다. 주요 전략으로는 LangSmith 트레이스 분석을 통한 에러 패턴 파악, 자가 검증(Self-Verification) 루프 도입, 그리고 추론 비용을 효율적으로 배분하는 리즈닝 샌드위치(Reasoning Sandwich) 기법이 사용되었다. 이러한 접근법은 모델의 한계를 시스템적으로 보완하여 자율적인 문제 해결 능력을 극대화하는 데 중점을 둔다.
배경
LLM Agent 기본 개념, LangChain/LangSmith 사용 경험, 소프트웨어 테스트 및 CI/CD 이해
대상 독자
자율 코딩 에이전트 또는 복잡한 에이전트 워크플로우를 설계하는 AI 엔지니어
의미 / 영향
이 연구는 고성능 모델을 단순히 사용하는 것을 넘어, 모델의 출력을 제어하고 검증하는 시스템적 설계가 에이전트의 실질적 성능을 결정짓는 핵심 요소임을 시사한다. 특히 오픈소스 도구인 LangChain과 LangSmith를 활용한 체계적인 개선 프로세스를 제시함으로써 에이전트 개발 방법론의 표준을 제안한다.
섹션별 상세
이미지 분석
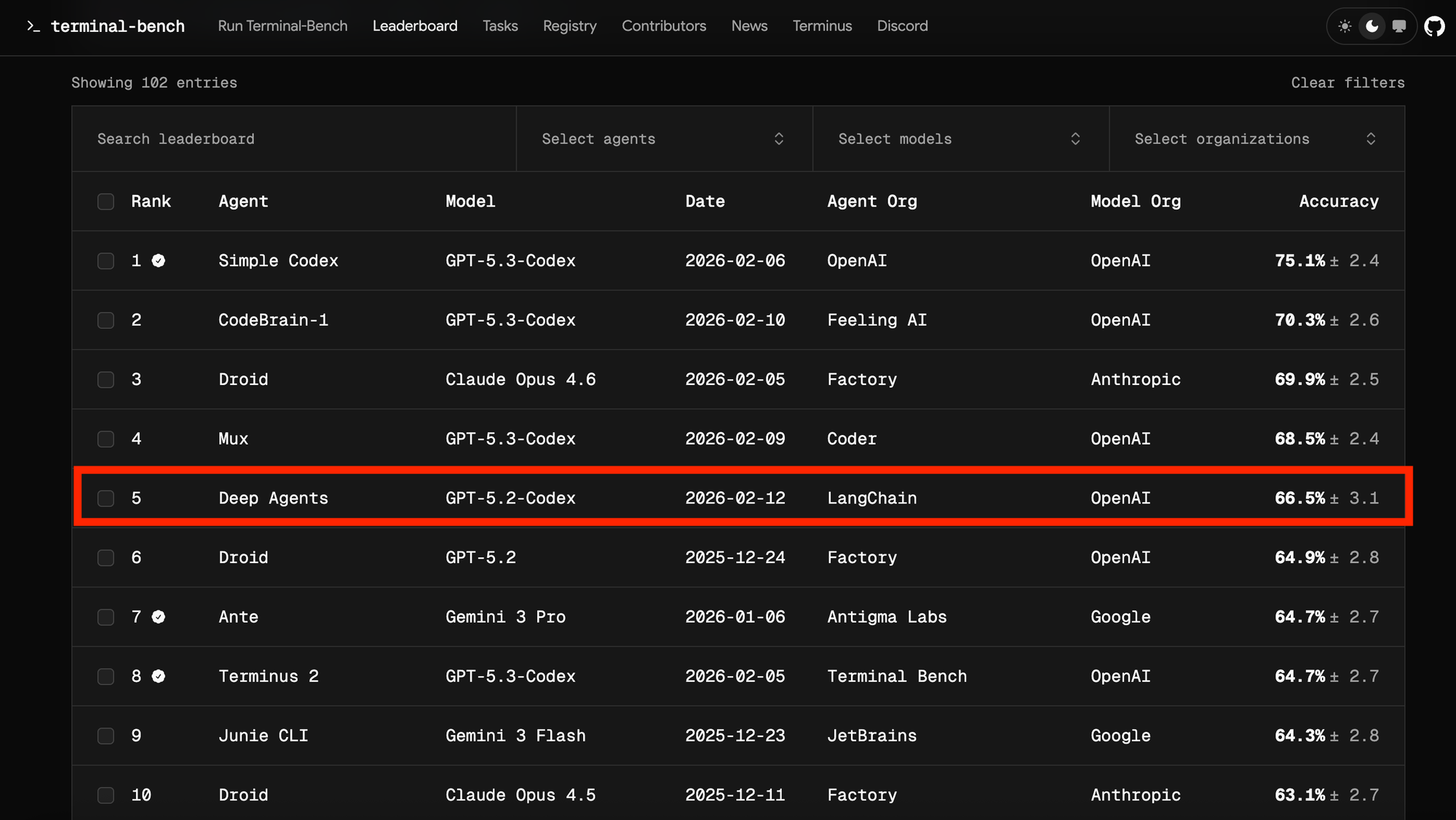
LangChain의 Deep Agents가 GPT-5.2-Codex 모델을 사용하여 66.5%의 정확도로 리더보드 상위권에 진입했음을 시각적으로 증명한다. 이는 하네스 엔지니어링의 실질적인 성과를 보여주는 지표이다.
Terminal Bench 2.0 리더보드에서 5위를 기록한 Deep Agents의 순위표 스크린샷이다.

베이스라인(52.8%)에서 커스텀 프롬프트 및 미들웨어 추가(63.6%), 그리고 적응형 추론 적용(66.5%)으로 이어지는 단계별 성능 개선 과정을 수치로 명확히 보여준다.
하네스 변경 사항에 따른 성능 향상 수치를 정리한 비교표이다.
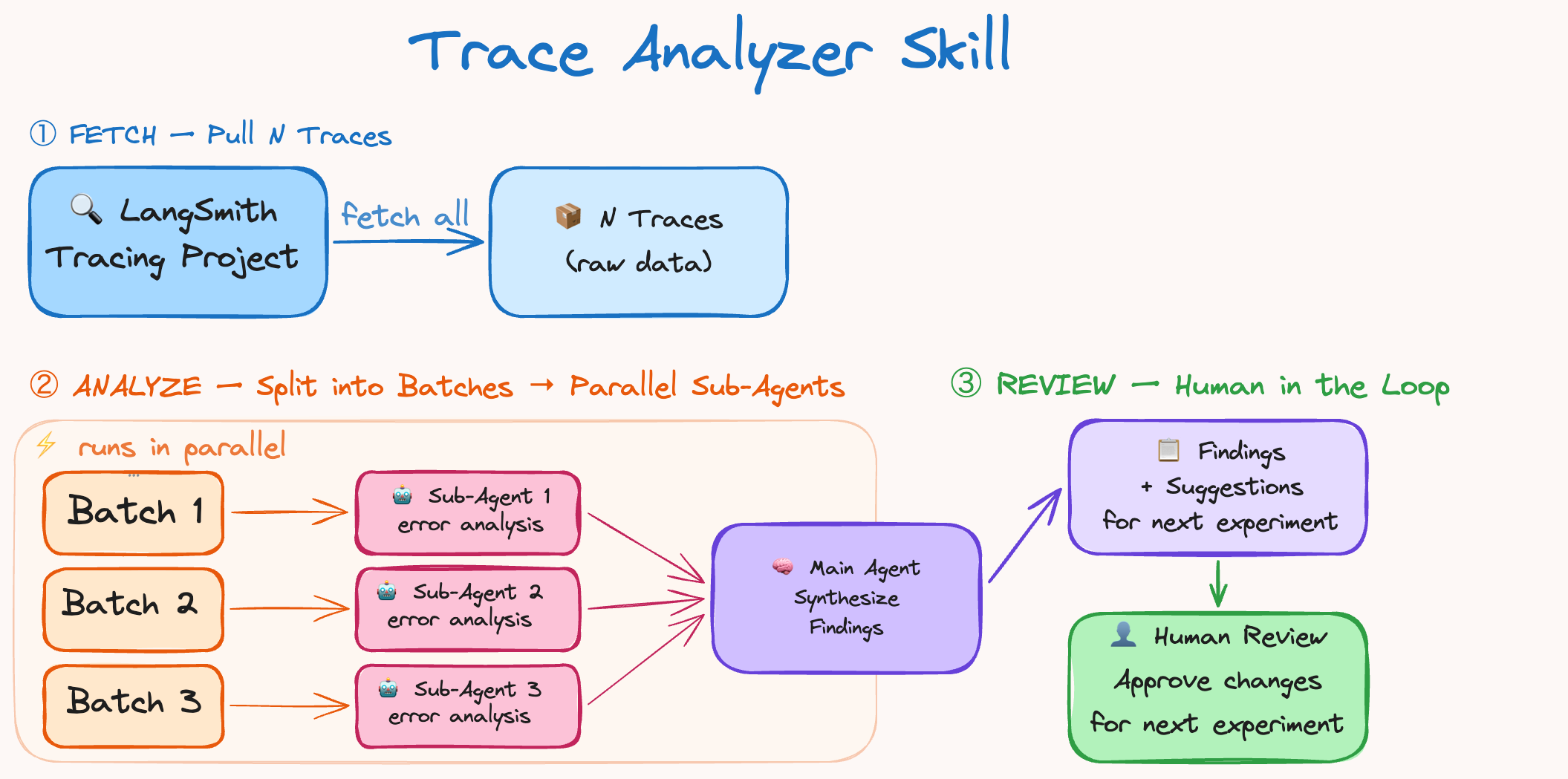
트레이스 수집, 병렬 서브 에이전트를 통한 에러 분석, 메인 에이전트의 결과 종합, 그리고 인간의 검토로 이어지는 자동화된 피드백 루프를 설명한다.
LangSmith 트레이스를 활용한 트레이스 분석기 스킬의 작동 아키텍처 다이어그램이다.
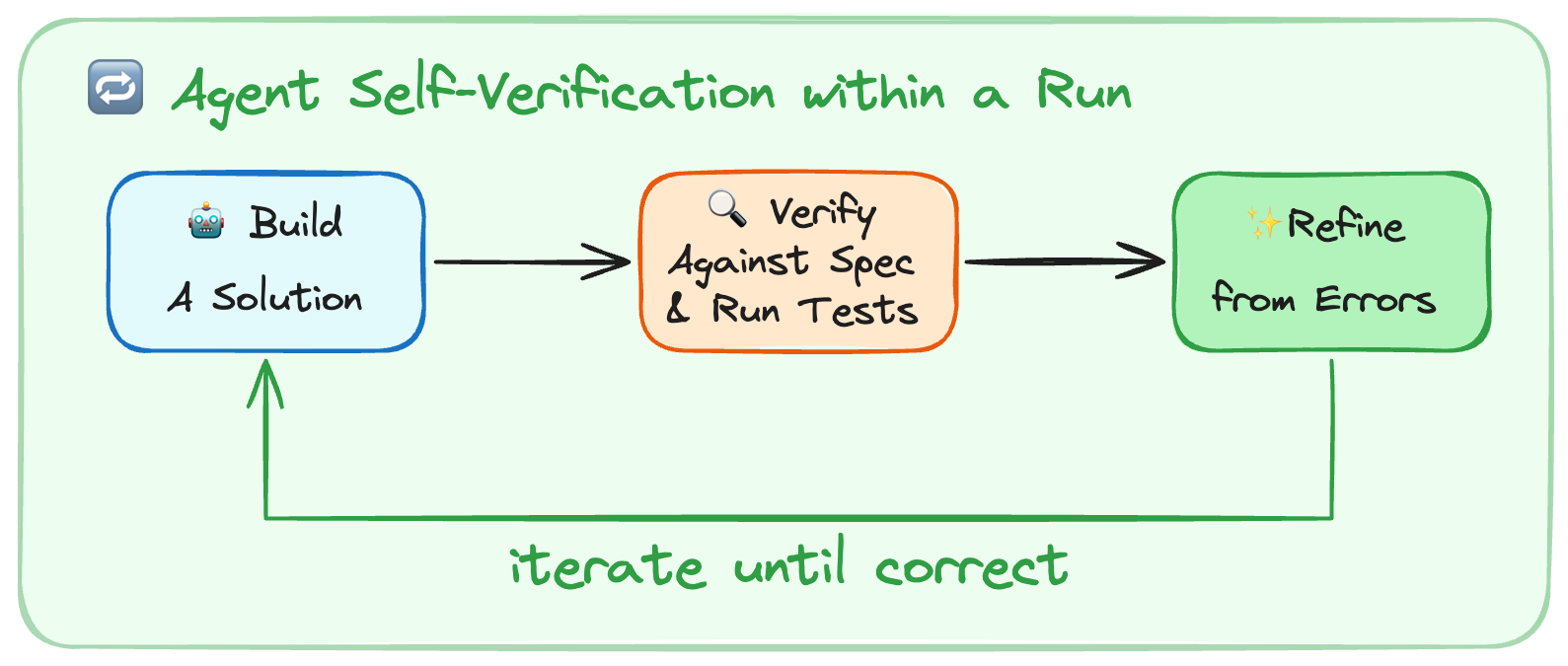
솔루션 구축, 명세서 대조 및 테스트 실행, 오류 기반 수정을 반복하여 정확한 결과에 도달할 때까지 순환하는 에이전트의 자율적 개선 메커니즘을 보여준다.
에이전트 내부의 자가 검증 루프를 시각화한 플로우차트이다.
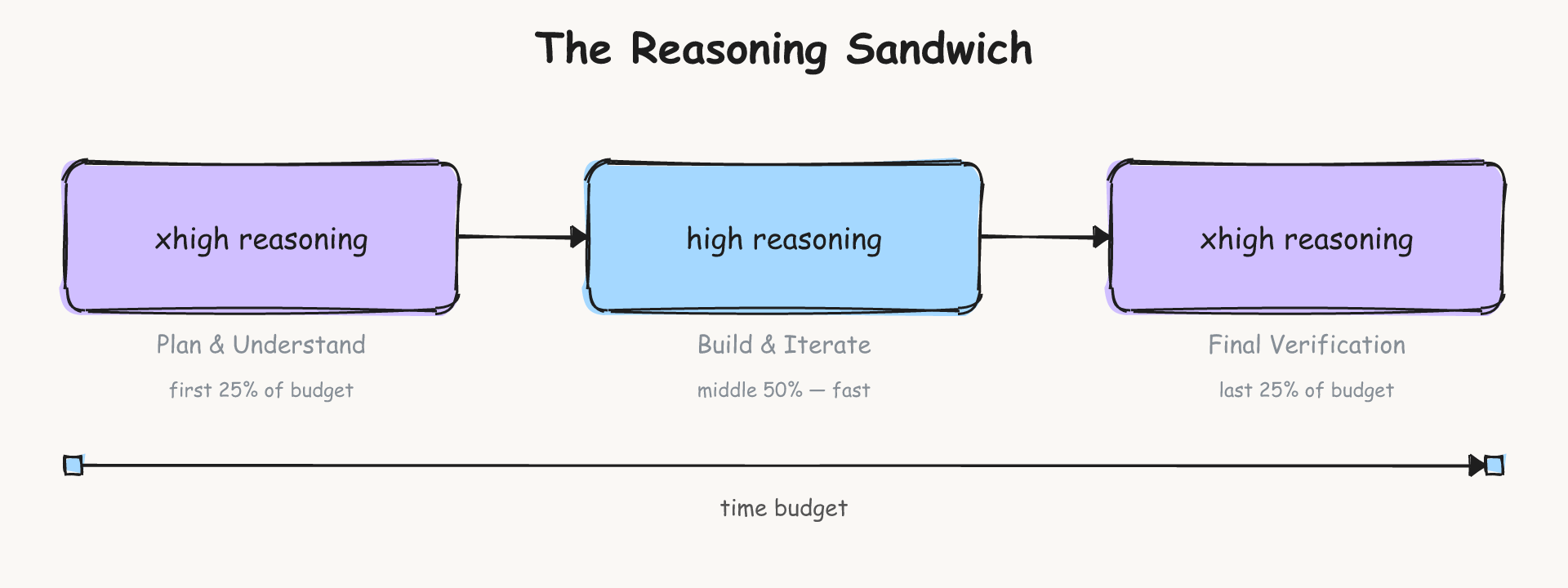
초기 계획과 최종 검증 단계에는 높은 추론(xhigh)을, 중간 구현 단계에는 일반 추론(high)을 배치하여 효율성과 정확도를 동시에 잡는 전략을 시각화했다.
시간 예산에 따른 추론 강도 배분 전략인 리즈닝 샌드위치 개념도이다.
실무 Takeaway
- 모델 성능을 높이려면 모델 교체보다 시스템 프롬프트와 미들웨어를 통한 컨텍스트 엔지니어링 및 검증 루프 구축이 더 효율적이다.
- 에이전트의 반복적인 실패 패턴을 감지하고 강제로 계획을 재수정하게 만드는 미들웨어 가드레일은 현재 모델의 한계를 극복하는 실용적인 도구이다.
- 추론 리소스를 작업 단계별로 다르게 배분하는 리즈닝 샌드위치 기법을 통해 비용 효율성과 작업 성공률을 동시에 개선한다.
- 트레이스 분석을 자동화하여 에러 패턴을 파악하고 이를 하네스 개선에 즉각 반영하는 반복적인 루프가 성능 향상의 핵심이다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료