핵심 요약
AI 에이전트의 작업 길이가 길어짐에 따라 LLM의 제한된 컨텍스트 윈도우를 관리하는 것이 핵심적인 기술적 과제로 부상했다. LangChain의 Deep Agents SDK는 파일시스템 오프로딩과 지능형 요약 기법을 결합하여 컨텍스트 부패를 방지하고 메모리 효율을 극대화한다. 대규모 도구 응답을 파일로 분리하고, 컨텍스트가 임계값에 도달하면 오래된 입력을 절단하거나 대화 이력을 구조화된 요약으로 대체하는 방식을 채택했다. 이러한 전략은 에이전트가 복잡한 장기 작업을 수행할 때 목표를 잃지 않고 필요한 세부 정보를 언제든 복구할 수 있는 환경을 제공한다.
배경
LLM 컨텍스트 윈도우 개념, LangChain 기본 사용법, AI 에이전트 및 도구 호출 이해
대상 독자
프로덕션 환경에서 복잡한 장기 작업을 수행하는 AI 에이전트를 개발하는 엔지니어
의미 / 영향
이 SDK는 에이전트의 컨텍스트 부패 문제를 해결하여 더 긴 시간 동안 일관성 있는 작업 수행을 가능하게 한다. 파일시스템을 외부 메모리로 활용하는 패턴은 향후 에이전트 아키텍처의 표준적인 최적화 기법으로 자리 잡을 가능성이 높다.
섹션별 상세
이미지 분석
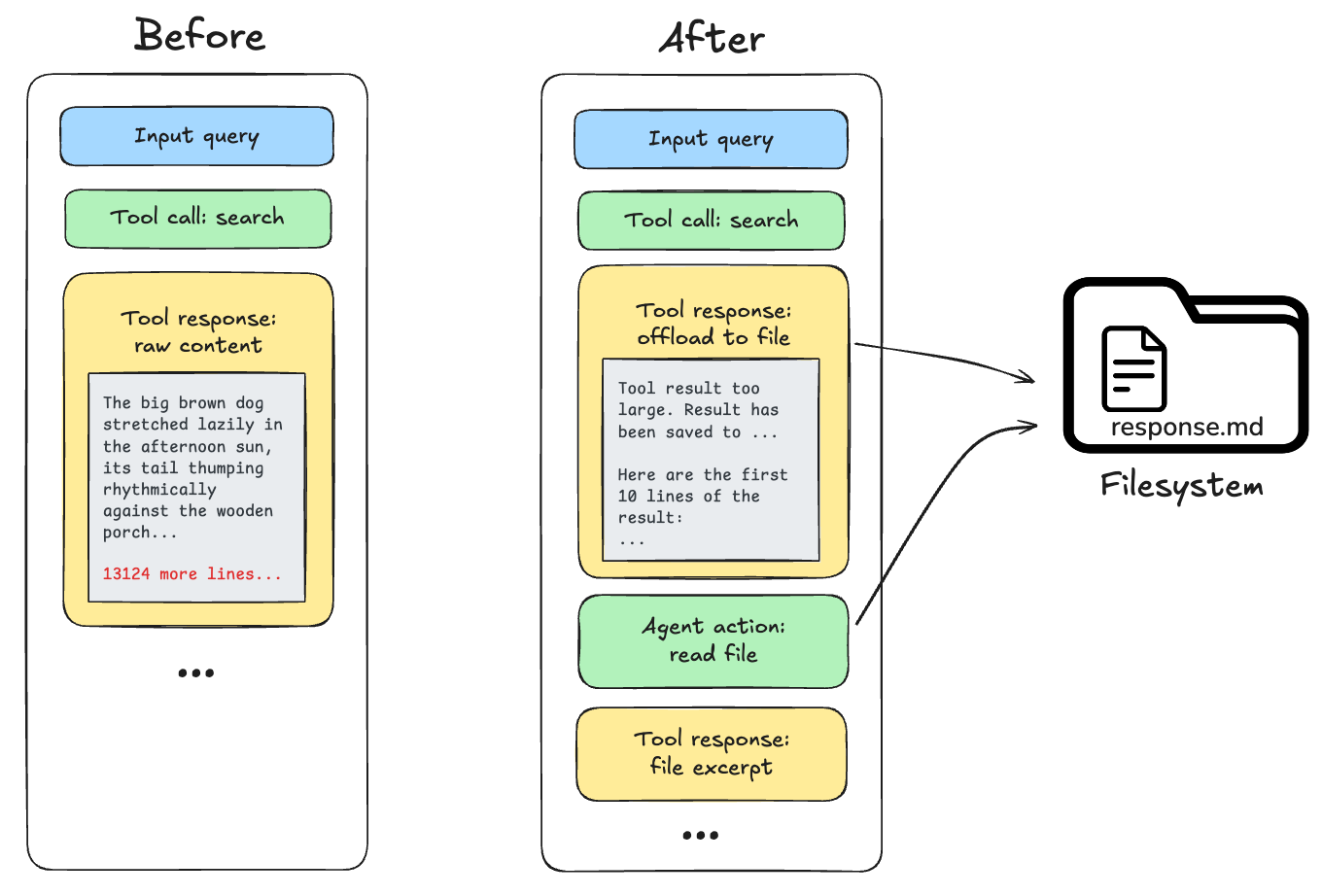
20,000 토큰 이상의 대규모 도구 응답이 발생했을 때 이를 파일시스템으로 옮기고 미리보기로 대체하는 과정을 시각화한다. 에이전트가 전체 데이터를 직접 보유하지 않고도 참조를 통해 정보를 관리하는 방식을 나타낸다.
대규모 도구 응답을 파일시스템으로 오프로딩하는 전후 비교 다이어그램이다.
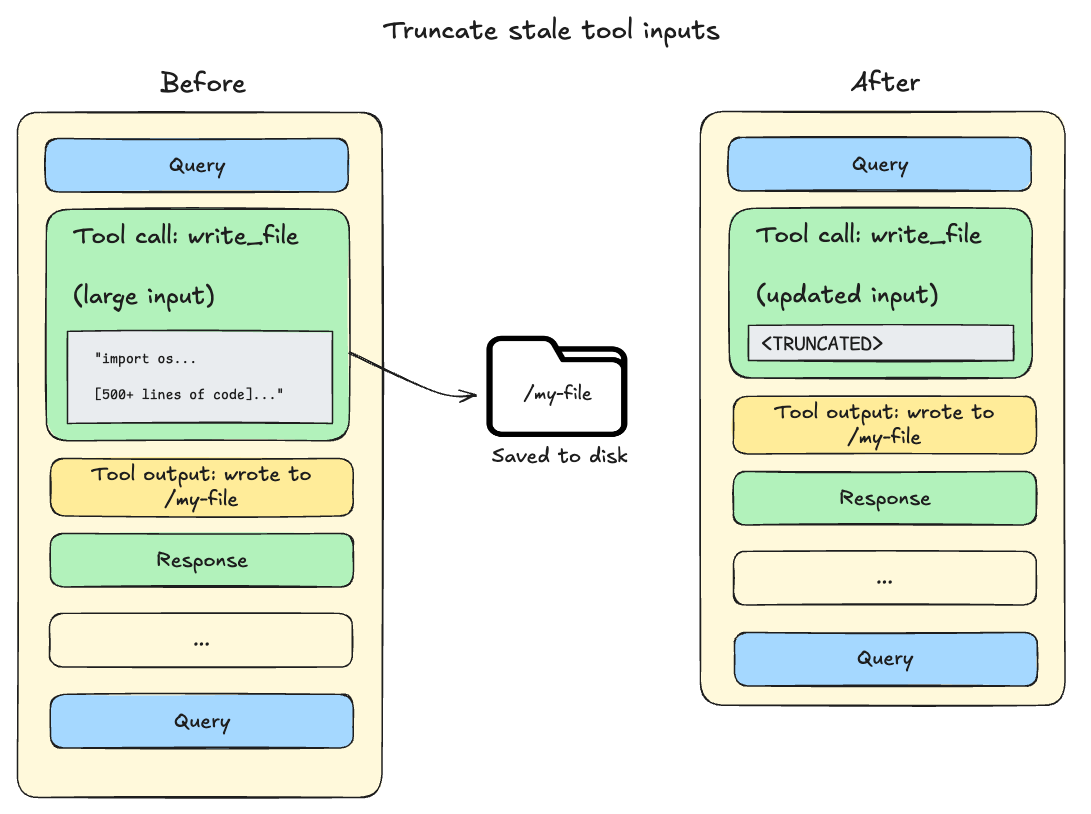
파일 쓰기 작업 등으로 인해 컨텍스트에 남은 대규모 입력 데이터를 절단하고 디스크 포인터로 대체하는 기법을 보여준다. 컨텍스트 윈도우의 85% 도달 시 중복 정보를 제거하여 효율을 높이는 과정을 설명한다.
오래된 도구 입력 데이터를 절단하여 컨텍스트를 확보하는 과정을 보여주는 이미지이다.
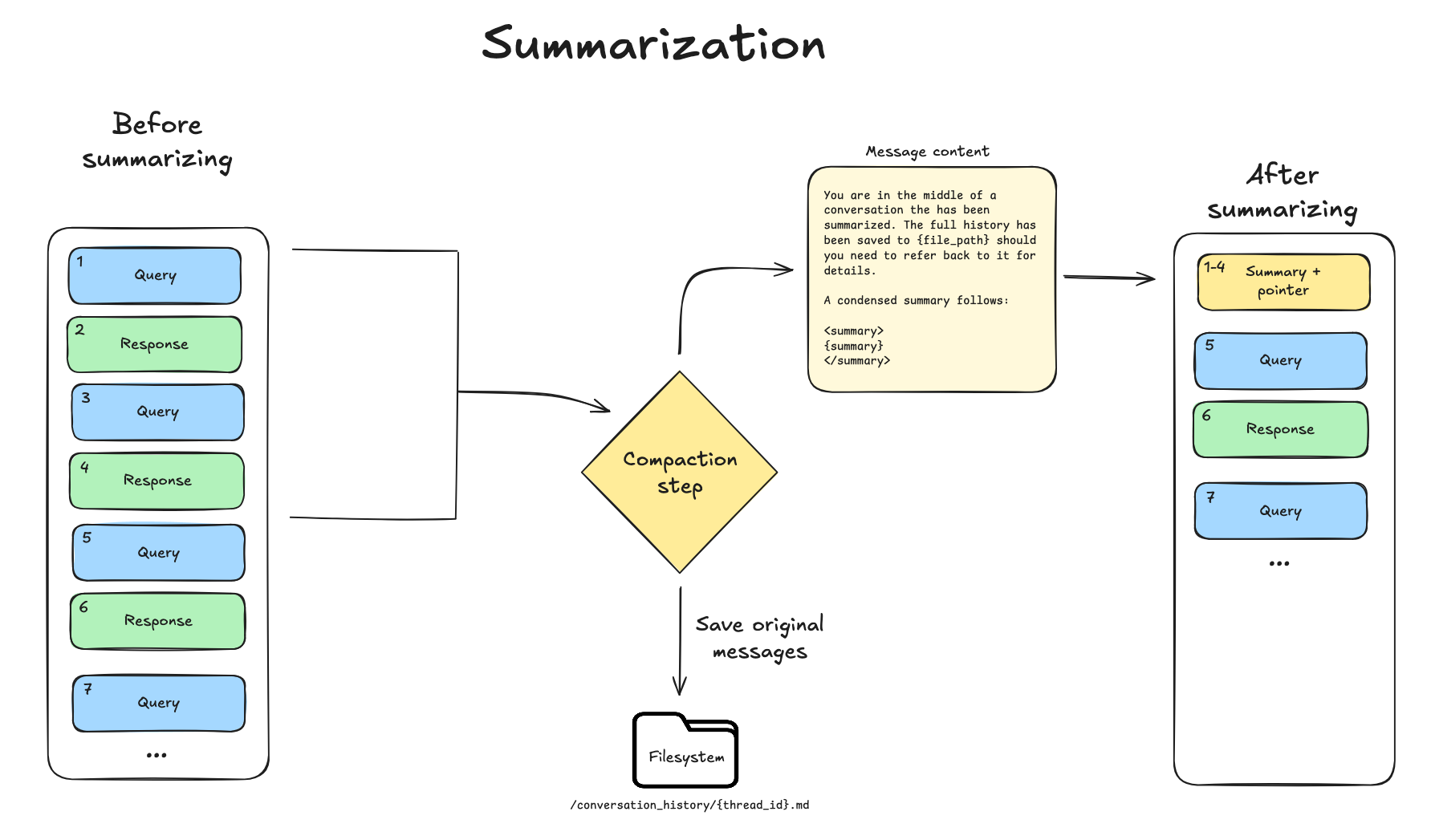
대화 이력을 요약하고 원본 메시지를 파일시스템에 저장하는 이중 구조를 다이어그램으로 표현한다. 요약본은 에이전트의 작업 메모리에 남고 원본은 검색 가능한 기록으로 보존되는 메커니즘을 명확히 한다.
대화 이력 요약 및 원본 메시지 보존 프로세스를 나타낸 플로우차트이다.
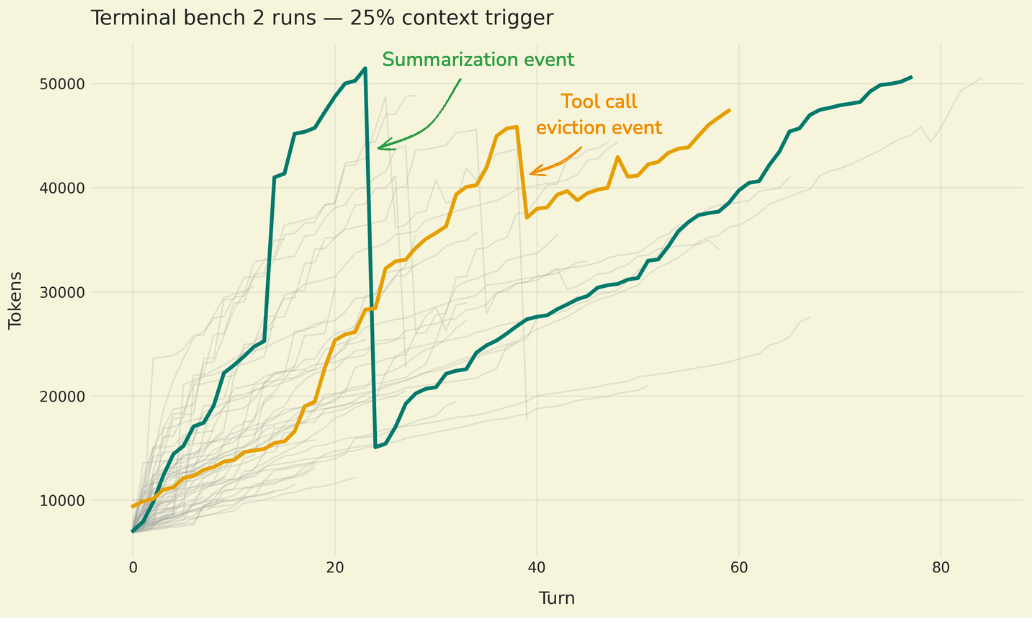
시간에 따른 토큰 사용량 변화를 그래프로 나타내며 요약 이벤트와 도구 호출 제거 이벤트 시점의 급격한 토큰 감소를 시각적으로 증명한다. 25% 임계값 설정을 통해 압축 기법의 효과를 벤치마크 상에서 확인한 결과이다.
벤치마크 테스트 중 시간에 따른 토큰 사용량 변화를 나타낸 그래프이다.
실무 Takeaway
- 20,000 토큰 이상의 대규모 데이터는 컨텍스트에 직접 주입하지 말고 파일시스템 오프로딩과 미리보기 방식을 조합하여 관리해야 한다.
- 컨텍스트 윈도우의 85% 지점을 임계값으로 설정하여 중복된 도구 입력값을 제거함으로써 추론 효율을 높이고 비용을 절감할 수 있다.
- 요약 시에는 단순 텍스트 요약뿐만 아니라 세션의 의도와 다음 단계를 명시적으로 포함해야 에이전트의 목표 이탈과 작업 중단을 방지할 수 있다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료