핵심 요약
LLM의 성능 향상을 위해 모델 학습뿐만 아니라 추론 단계에서 더 많은 자원을 사용하는 추론 시점 스케일링이 주목받고 있다. 이 기법은 모델 가중치를 수정하지 않고도 답변의 품질을 개선할 수 있는 방법론들을 포괄한다. 본 아티클은 Chain-of-Thought, Self-Consistency, Best-of-N 랭킹 등 다양한 추론 전략을 체계적으로 분류한다. 특히 OpenAI의 o1 모델 이후 중요해진 추론 연산량과 성능 간의 상관관계를 확인하며 실무적인 적용 가능성을 확인한다.
배경
LLM 추론 기본 원리, 프롬프트 엔지니어링 기초
대상 독자
LLM 애플리케이션 개발자 및 AI 연구원
의미 / 영향
추론 시점 스케일링은 고정된 모델 성능의 한계를 극복하게 해주며, 특히 추론 비용과 정확도 사이의 균형을 사용자가 직접 조절할 수 있는 유연성을 제공한다. 이는 향후 추론 전용 모델 시장의 성장을 가속화할 전망이다.
섹션별 상세
이미지 분석

파운데이션 모델 구축 이후 추론 모델로 발전하는 과정에서 Inference-time scaling이 핵심적인 역할을 함을 시각화한다. 이 아티클이 다루는 범위가 추론 모델 전문화의 하위 단계임을 명확히 나타낸다.
LLM 구축부터 전문화까지의 단계를 보여주는 로드맵 다이어그램.
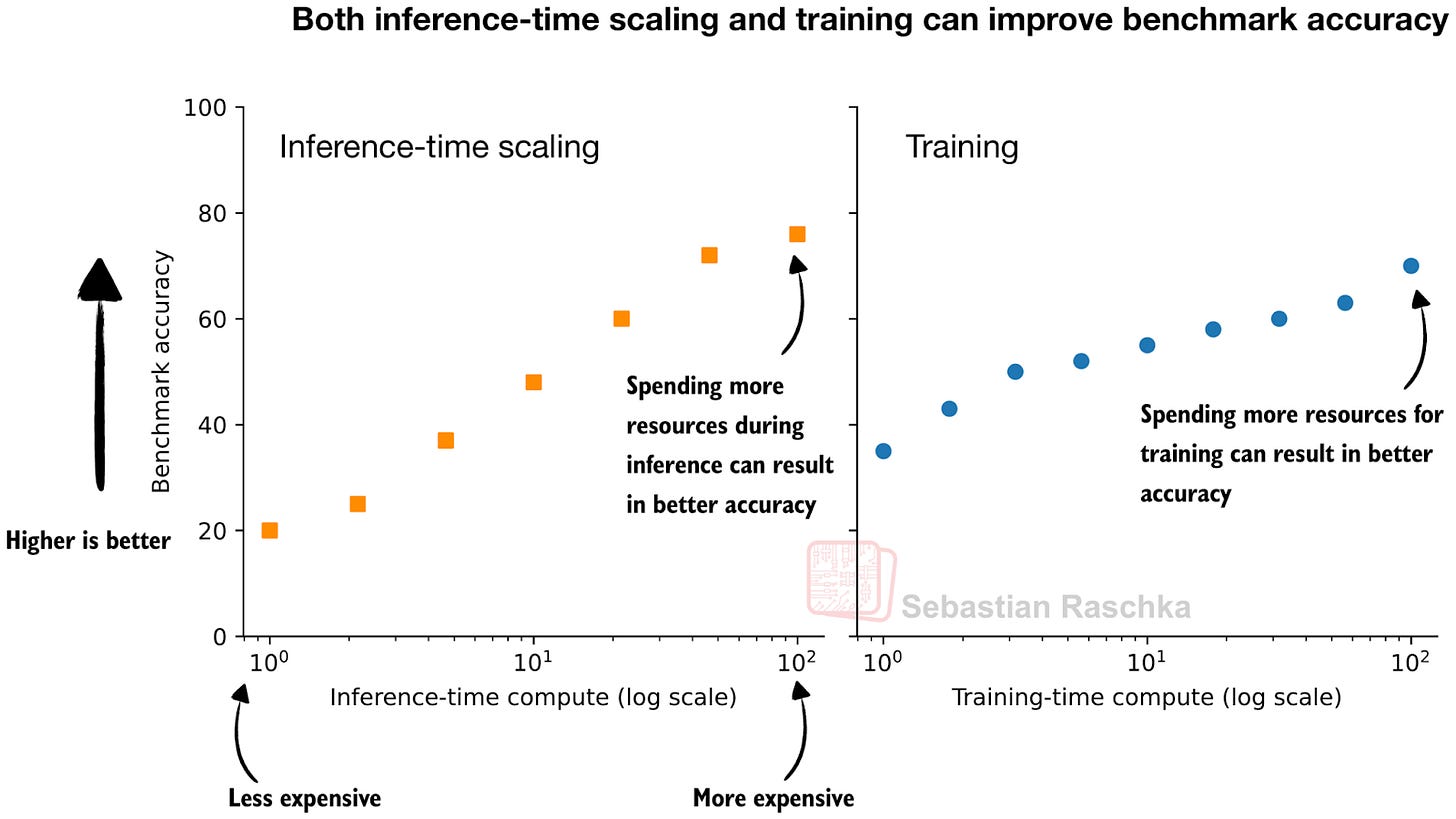
추론 시점의 컴퓨팅 자원을 늘리는 것이 학습 자원을 늘리는 것과 마찬가지로 모델의 정확도를 우상향시킨다는 점을 입증한다. 로그 스케일 상에서 연산량 투입 대비 성능 향상 폭을 직관적으로 비교할 수 있게 돕는다.
추론 시간 연산량과 학습 시간 연산량에 따른 벤치마크 정확도 변화 그래프.
실무 Takeaway
- 모델 학습 비용이 부담스러운 상황에서 추론 시점의 연산량을 늘리는 것만으로도 벤치마크 성능을 개선할 수 있다.
- 단순한 프롬프팅을 넘어 Self-Consistency나 Verifier 기반의 랭킹 시스템을 도입하면 답변의 신뢰도를 실무 수준으로 확보할 수 있다.
- 복잡한 추론이 필요한 태스크일수록 단순 생성보다는 탐색과 자기 수정 메커니즘을 결합한 아키텍처가 유리하다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료