이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
Anthropic이 Claude Opus 4.6과 Sonnet 4.6 모델의 100만 컨텍스트 윈도우를 정식 출시하며 긴 문맥 처리 성능의 새로운 기준을 제시했다. 하지만 HBM 공급 부족 등 물리적 제약으로 인해 지난 2년간 컨텍스트 확장이 정체되고 있으며, 향후 '컨텍스트 배급제'가 도입될 가능성이 제기되고 있다. 기술적으로는 MCP(Model Context Protocol)의 확산과 에이전트의 영구 메모리 구현, 그리고 Sparse Attention 최적화와 같은 추론 효율화 기법들이 주목받고 있다. 또한 사후 학습에서 강화학습 없이 가우시안 노이즈를 활용해 성능을 높이는 RandOpt와 같은 혁신적인 연구 결과가 발표되었다.
배경
LLM 컨텍스트 윈도우 및 토큰 개념, RAG(검색 증강 생성) 기본 원리, Attention Mechanism에 대한 기초 지식
대상 독자
LLM 인프라 엔지니어 및 AI 에이전트 개발자
의미 / 영향
컨텍스트 윈도우의 물리적 확장 한계가 명확해짐에 따라, 무한한 컨텍스트 경쟁보다는 메모리 계층 구조 설계와 추론 효율화 기술이 향후 AI 서비스의 핵심 차별화 요소가 될 것이다.
섹션별 상세
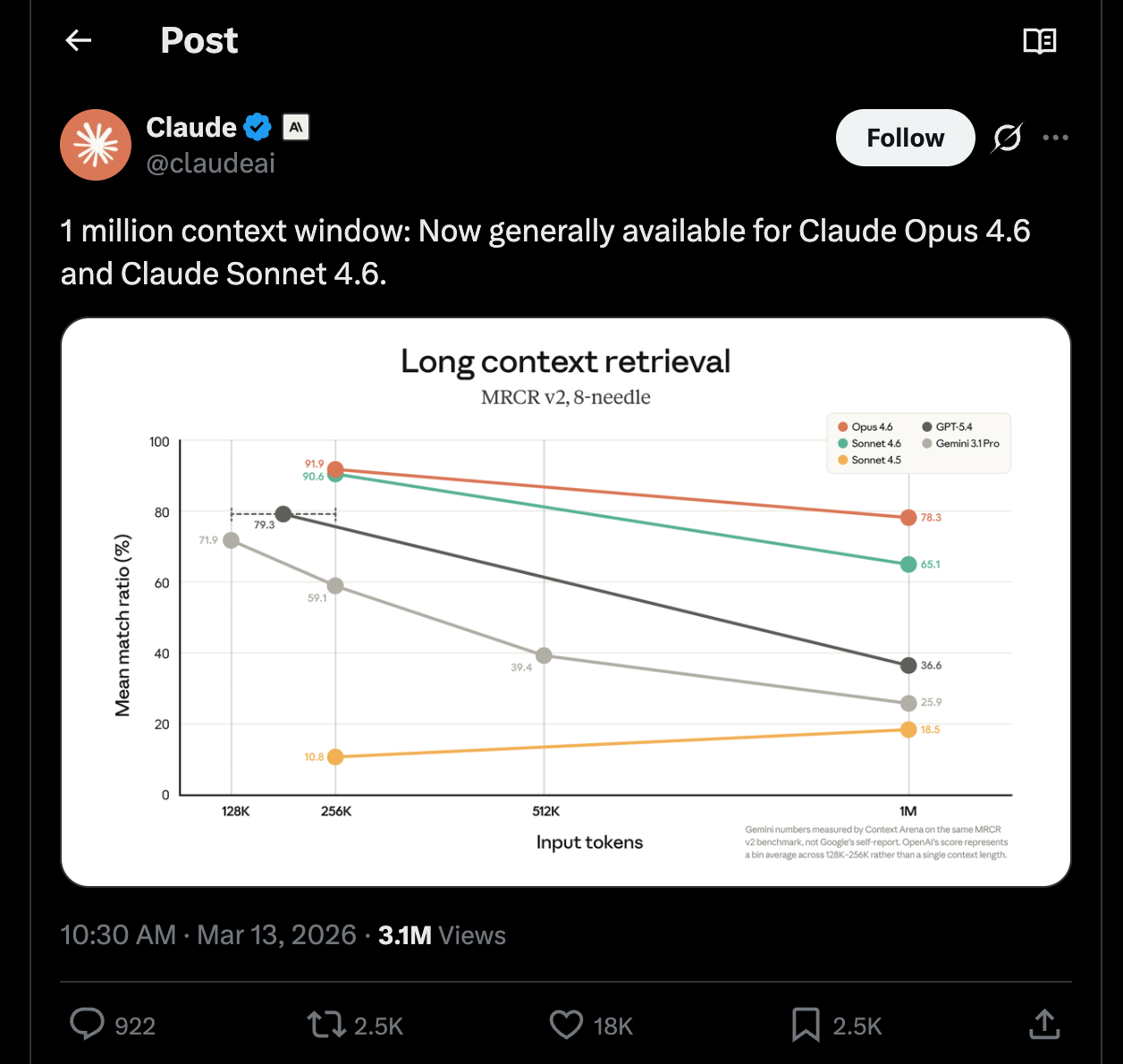
Anthropic이 Claude Opus 4.6 및 Sonnet 4.6 모델에서 100만 컨텍스트 윈도우를 정식 출시했으며, MRCR v2 벤치마크에서 78.3%의 정확도를 기록하며 업계 최고 수준의 긴 문맥 유지 능력을 입증했다.
LLM의 컨텍스트 윈도우 확장이 HBM 및 DRAM의 물리적 공급 부족으로 인해 지난 2년간 100만 수준에서 정체되어 있으며, 이는 소프트웨어 기술력이 아닌 하드웨어 생산 능력의 한계에 기인한다.
에이전트 인프라 분야에서는 MCP(Model Context Protocol)의 사용성 논쟁이 이어지는 가운데, 에이전트의 실행 궤적에서 최적의 전략을 추출하여 성능을 개선하는 영구 메모리(Persistent Memory) 기술이 대안으로 부상하고 있다.
추론 최적화를 위해 Sparse Attention의 인덱스 정보를 레이어 간에 재사용하는 IndexCache 기법이 제안되었으며, 이는 GLM-5(744B) 모델에서 품질 저하 없이 약 1.2배의 엔드투엔드 속도 향상을 달성했다.
MIT 연구진은 모델 가중치에 가우시안 노이즈를 추가하고 앙상블하는 RandOpt 기법이 PPO나 GRPO와 같은 복잡한 강화학습 과정 없이도 추론 및 코딩 작업에서 대등한 성능을 낼 수 있음을 확인했다.
생물학 분야에서는 OpenFold3 프리뷰 2가 공개되었으며, 이는 AlphaFold3와 대등한 성능을 내면서도 학습 데이터셋과 설정을 모두 공개하여 완전한 재현이 가능한 유일한 모델로 평가받는다.
실무 Takeaway
- 100만 컨텍스트를 활용하는 RAG 시스템 설계 시 MRCR v2 벤치마크의 78.3% 정확도를 기준으로 데이터 인출 신뢰도를 산정해야 한다.
- 단순히 컨텍스트 윈도우를 늘리는 방식보다 캐시 및 메모리 계층 구조를 갖춘 영구 메모리 아키텍처를 도입하는 것이 에이전트의 작업 성공률 개선에 더 효과적이다.
- 대규모 모델 운영 시 IndexCache와 같은 Sparse Attention 최적화 기법을 적용하여 추가적인 코드 변경 없이 추론 속도를 1.2~1.8배 개선할 수 있다.
언급된 리소스
GitHubOpen Deep Research v2
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 03. 14.수집 2026. 03. 14.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.