핵심 요약
2025년은 DeepSeek R1의 등장으로 '추론 모델'과 '강화학습(RLVR/GRPO)'이 LLM 개발의 중심이 된 해였다. 대규모 사전 학습뿐만 아니라 사후 학습(Post-training)에서의 효율적인 강화학습과 추론 시간 스케일링이 모델 성능 향상의 핵심으로 부상했다. 또한, 벤치마크 점수 지상주의인 '벤치맥싱(Benchmaxxing)' 현상과 도구 사용(Tool Use)의 보편화가 주요 트렌드로 나타났다. 2026년에는 RLVR의 도메인 확장과 추론 효율성 개선이 더욱 가속화될 것으로 전망된다.
배경
LLM 아키텍처 기초, 강화학습 기본 개념 (PPO, RLHF), 트랜스포머 메커니즘
대상 독자
AI 연구자, LLM 엔지니어, 기술 전략가
의미 / 영향
DeepSeek의 효율적 학습 방식은 거대 IT 기업뿐만 아니라 도메인 특화 데이터를 보유한 기업들도 자체적인 고성능 LLM을 구축할 수 있는 길을 열어주었다. 이는 AI 모델 개발의 민주화와 동시에 데이터 주권의 중요성을 더욱 강조하게 될 것이다.
섹션별 상세
이미지 분석
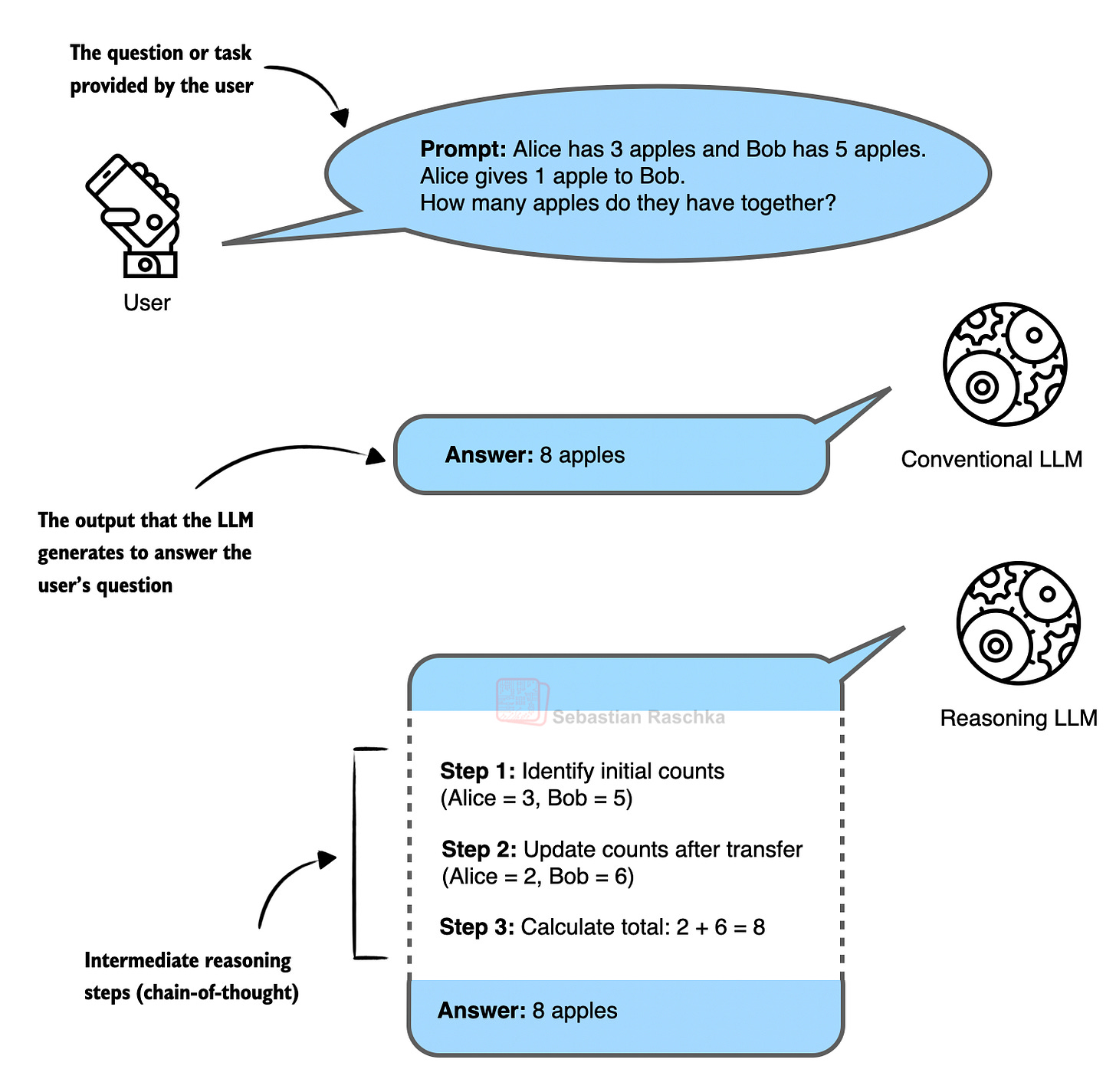
일반 모델은 정답만 출력하는 반면, 추론 모델은 사고의 중간 단계(Chain-of-Thought)를 거쳐 최종 답변에 도달하는 과정을 시각화했다. 이는 2025년의 핵심 트렌드인 추론 모델의 작동 원리를 직관적으로 설명한다.
일반 LLM과 추론 LLM의 답변 방식 차이를 보여주는 다이어그램
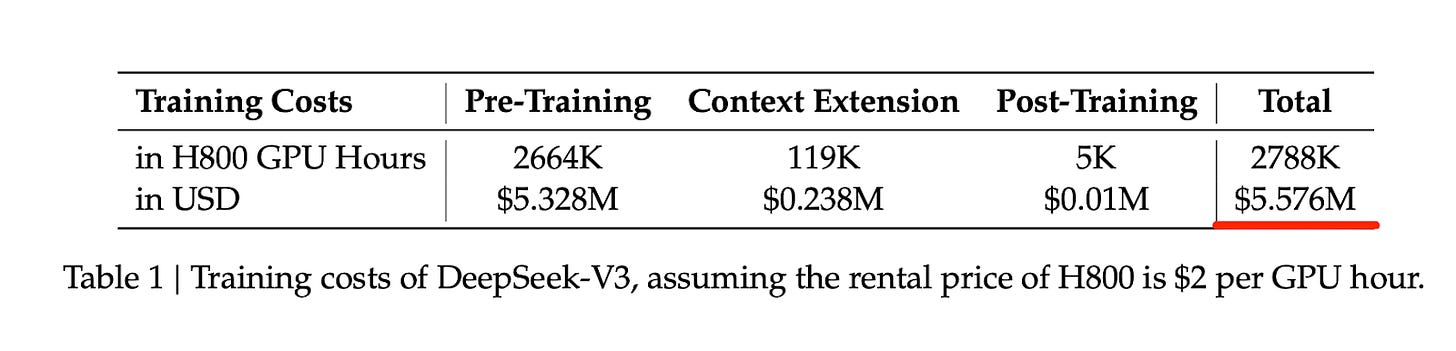
671B 파라미터 모델인 DeepSeek-V3의 총 학습 비용이 약 557만 달러임을 명시하고 있다. 이는 기존 SOTA 모델들의 학습 비용에 비해 획기적으로 낮아진 수치임을 데이터로 증명한다.
DeepSeek-V3 모델의 학습 비용 추정표
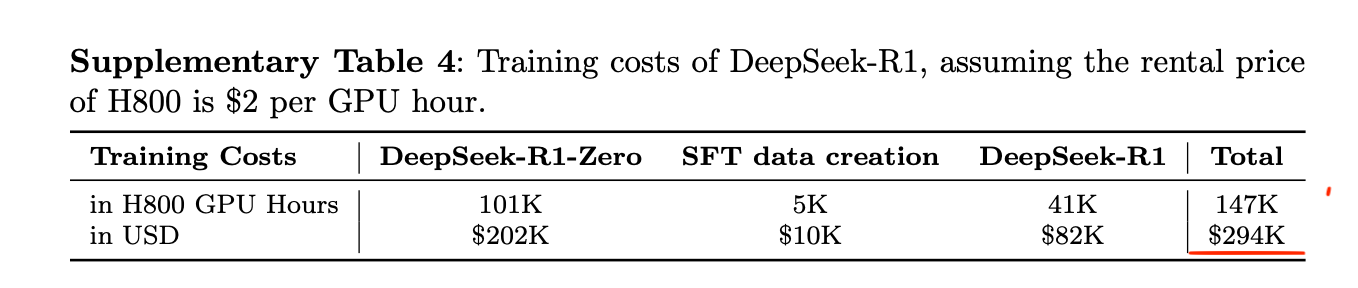
DeepSeek-V3 기반 위에 R1 모델을 구축하는 데 드는 추가 비용이 약 29만 4천 달러에 불과함을 보여준다. 사후 학습을 통한 성능 향상이 매우 경제적일 수 있음을 시사한다.
DeepSeek-R1 모델의 추가 학습 비용 추정표
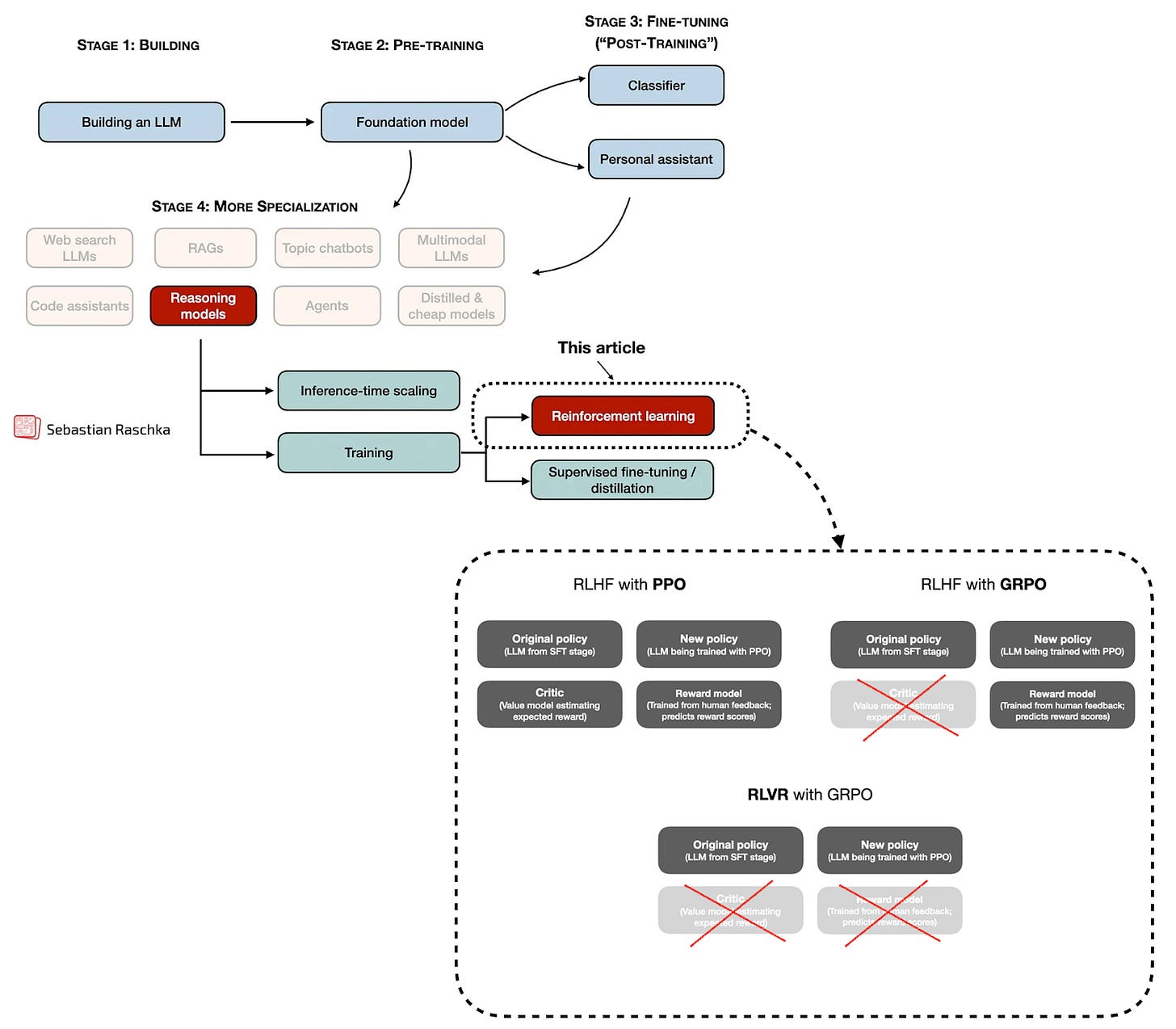
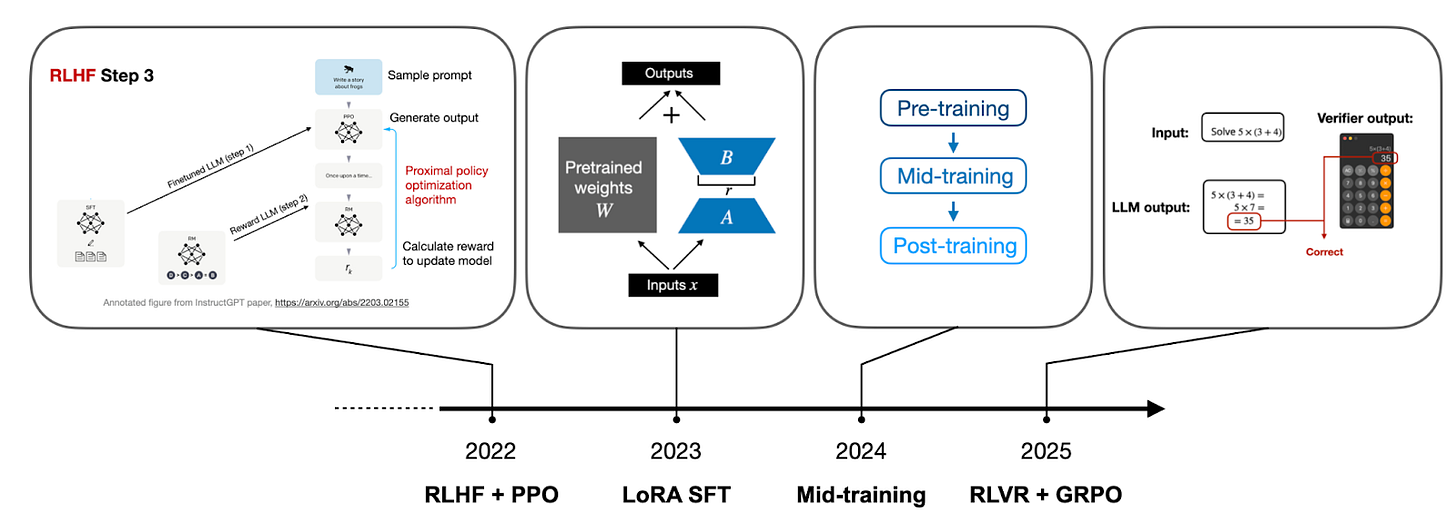
사전 학습, 미드 트레이닝, 사후 학습 단계 중 추론 모델 개발을 위한 강화학습(RLVR, GRPO)이 적용되는 위치를 설명한다. PPO와 GRPO의 구조적 차이점도 함께 도식화되어 있다.
LLM 학습 단계별 강화학습 적용 지점 다이어그램
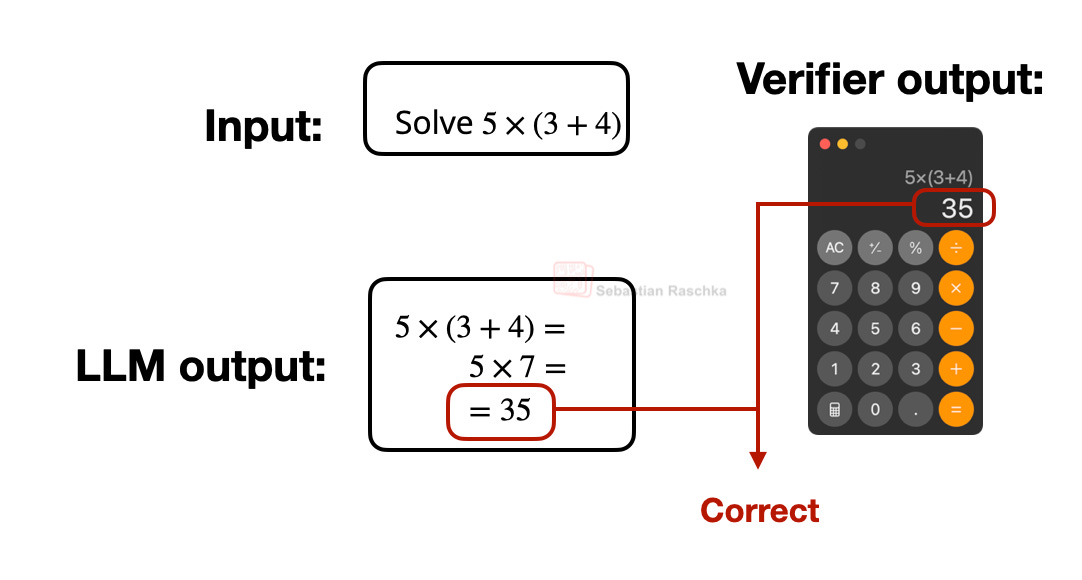
수학 문제의 정답을 계산기 API와 비교하여 모델에 보상을 주는 과정을 보여준다. RLVR의 핵심인 결정론적 검증 메커니즘을 시각적으로 설명한다.
검증 가능한 보상(Verifiable Reward)의 작동 예시
추론 단계에서 반복적인 자기 정교화(Self-refinement)를 수행할수록 IMO Shortlist 2024 점수가 상승함을 보여준다. 이는 추론 시간 스케일링의 실질적 효과를 입증하는 데이터이다.
자기 정교화 반복 횟수에 따른 수학 벤치마크 성능 향상 그래프
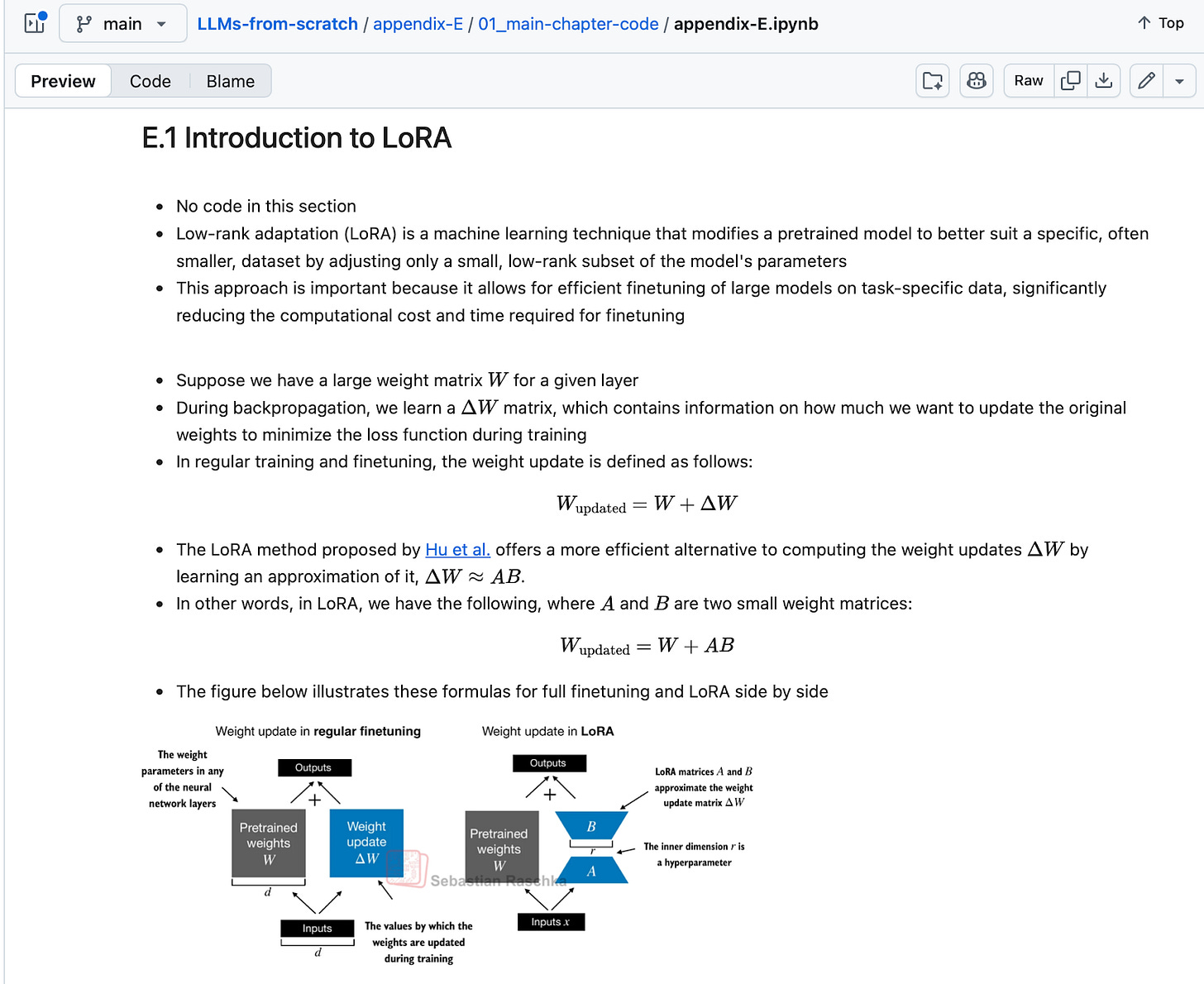
가중치 업데이트를 저차원 행렬 A, B의 곱으로 근사하는 LoRA의 핵심 원리를 설명한다. 2023년의 핵심 트렌드였던 파라미터 효율적 미세 조정 기법을 기술적으로 요약한다.
LoRA 기법의 수식과 아키텍처를 설명하는 GitHub 문서 캡처
실무 Takeaway
- RLVR과 GRPO를 활용한 사후 학습은 특정 도메인에서 모델의 논리적 추론 능력을 강화하는 가장 효율적인 방법이다.
- 단순 모델 크기 확장보다는 데이터 믹스 최적화, 미드 트레이닝, 그리고 추론 단계에서의 연산량 조절이 가성비 높은 성능 향상을 이끈다.
- 벤치마크 점수에 매몰되지 말고 도구 사용과 실제 워크플로우 적용 가능성을 기준으로 모델을 평가해야 한다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료