핵심 요약
DeepSeek V3.2는 이전 모델의 MLA(Multi-Head Latent Attention) 아키텍처를 계승하면서 DSA(DeepSeek Sparse Attention)를 도입해 추론 효율성을 극대화했다. 특히 DeepSeekMath V2에서 검증된 자가 검증(Self-Verification)과 자가 정제(Self-Refinement) 기법을 통합하여 수학 및 추론 성능을 비약적으로 향상시켰다. 학습 알고리즘인 GRPO의 안정성을 개선하고, 추론 스케일링을 위한 Speciale 모델을 통해 GPT-5 및 Gemini 3.0 Pro 수준의 성능을 목표로 한다. 최종적으로 mHC와 같은 새로운 잔차 연결 기법 연구를 통해 학습 안정성과 수렴 속도를 더욱 개선했다.
배경
Transformer 아키텍처, 강화학습(RLHF/PPO) 기초, 어텐션 메커니즘(MHA/GQA)
대상 독자
LLM 아키텍처 설계자 및 강화학습 기반 추론 모델 개발자
의미 / 영향
DeepSeek의 기술 공개는 고성능 추론 모델 개발에 필요한 아키텍처와 학습 방법론의 표준을 제시하며, 오픈 웨이트 모델의 경쟁력을 proprietary 모델 수준으로 끌어올리는 기폭제가 된다.
섹션별 상세
이미지 분석
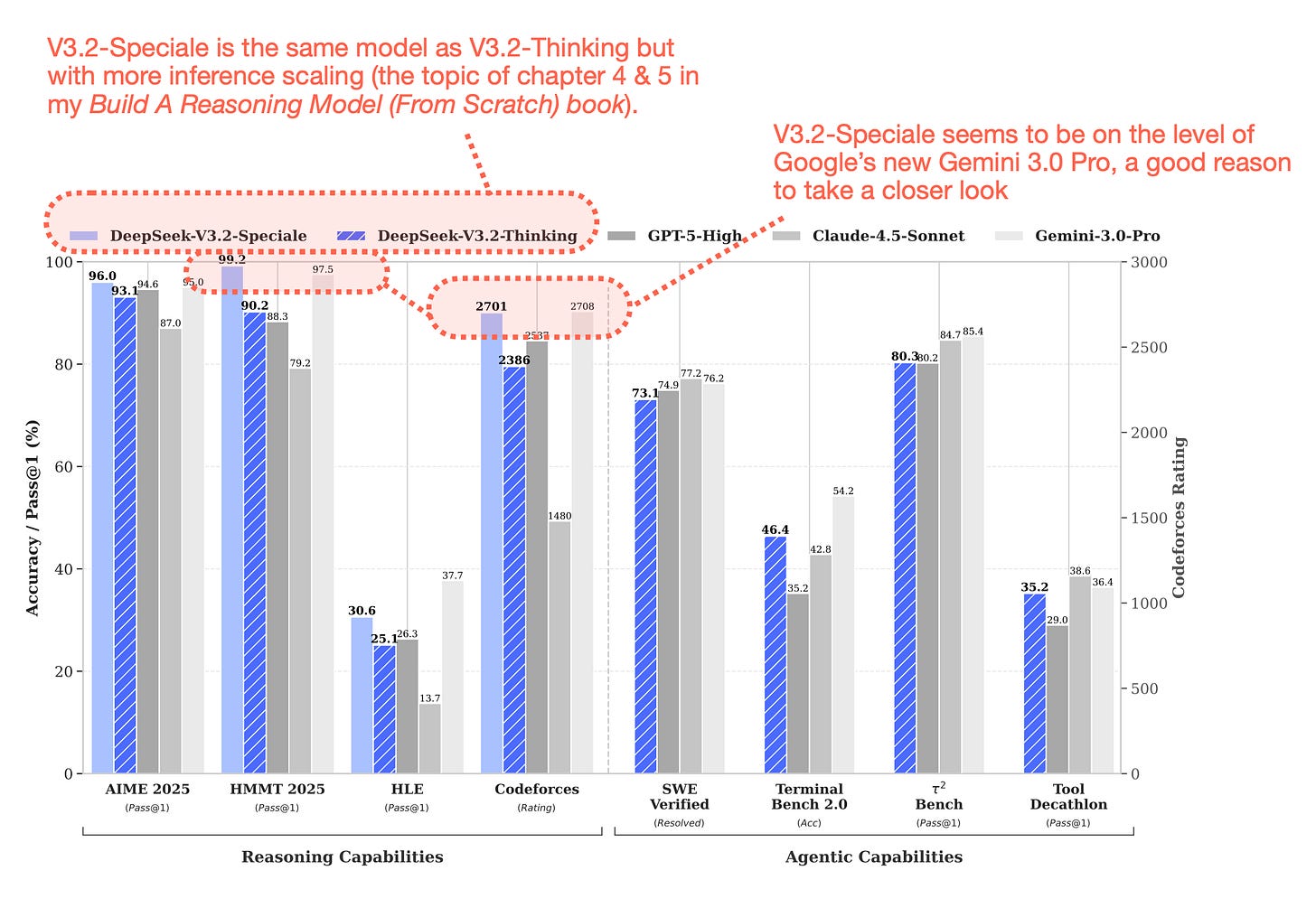
DeepSeek V3.2가 AIME 2025, HMMT 2025 등 수학 및 추론 벤치마크에서 GPT-5-High 및 Gemini-3.0-Pro와 대등하거나 능가하는 성능을 보여준다.
DeepSeek V3.2와 주요 상용 모델 간의 벤치마크 비교 차트
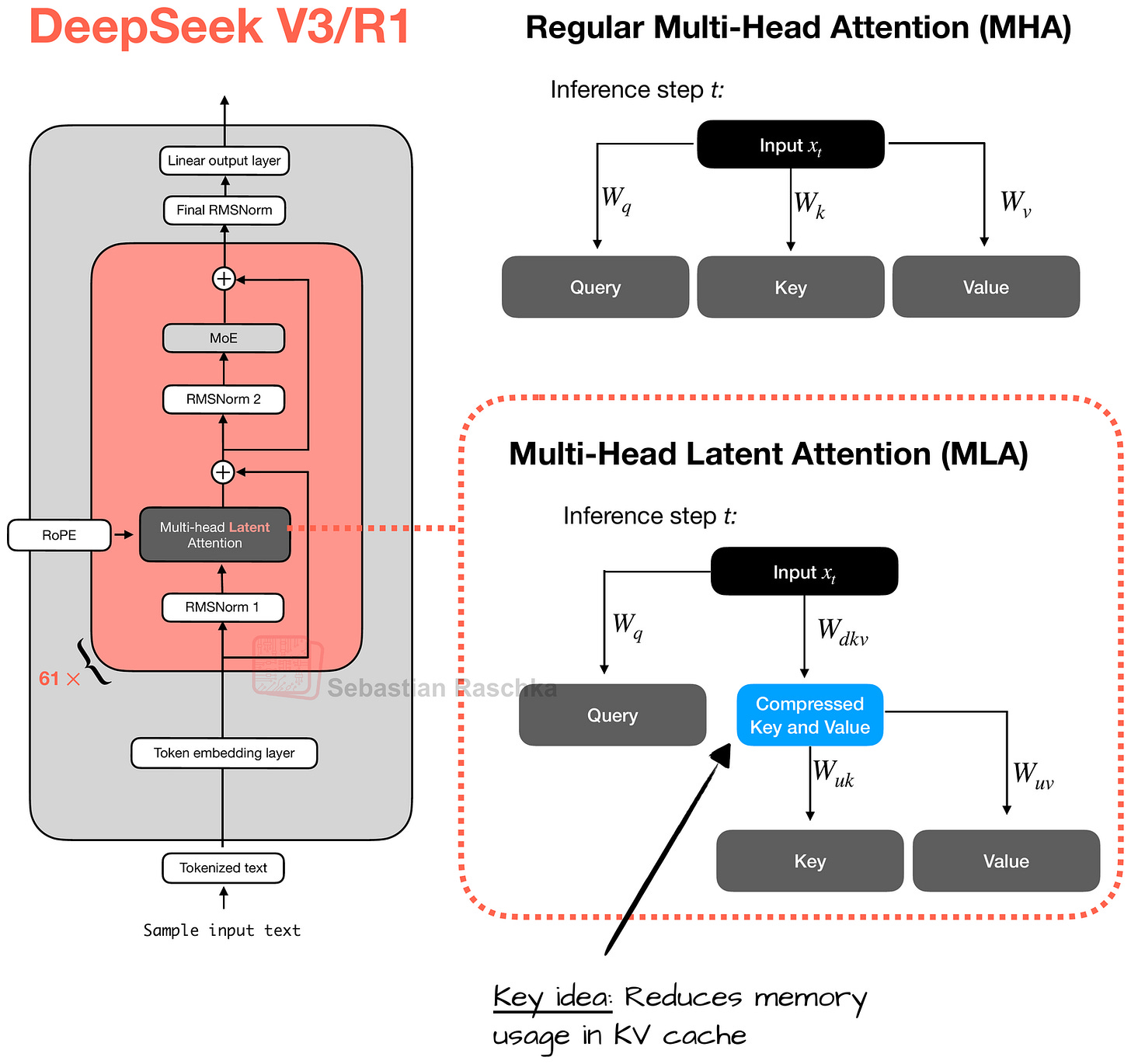
MLA와 DSA가 통합된 모델 구조를 보여주며, 671B 파라미터 중 37B만 활성화되는 MoE 구조와 128k 토큰 컨텍스트 지원을 명시한다.
DeepSeek V3.2의 전체 아키텍처 다이어그램
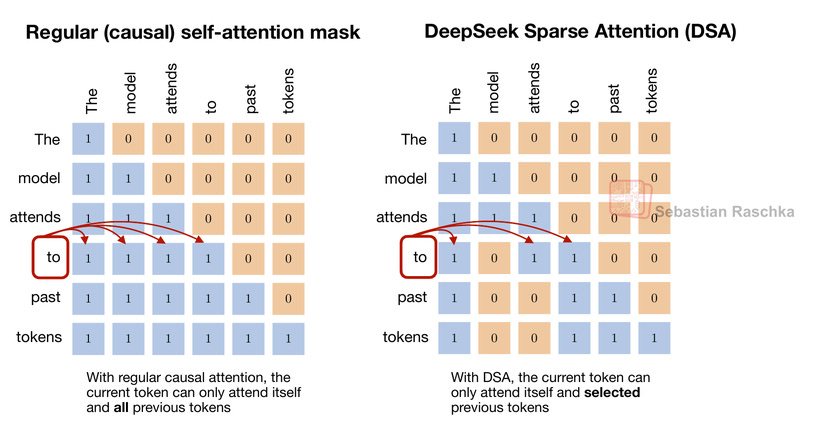
일반적인 인과적 어텐션과 달리 DSA는 현재 토큰이 이전 토큰 중 선택된 일부에만 어텐션을 수행하여 계산 효율을 높이는 방식을 시각화한다.
DeepSeek Sparse Attention(DSA)의 작동 원리 비교
실무 Takeaway
- MLA와 DSA의 결합은 긴 문맥 처리 시 발생하는 메모리 및 연산 병목 현상을 해결하는 실질적인 아키텍처 대안이다.
- 추론 성능 향상을 위해 단순한 모델 크기 확장보다 자가 검증 루프를 통한 데이터 품질 개선과 추론 시 반복 수정이 더 효과적이다.
- 강화학습 알고리즘인 GRPO의 세부적인 마스킹 및 정규화 기법은 모델의 편향을 방지하고 학습 수렴 속도를 높이는 데 필수적이다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료