핵심 요약
2025년은 LLM의 성능 포화 우려를 불식시키며 추론 모델과 강화학습 기법이 비약적으로 발전한 한 해였다. DeepSeek R1의 등장은 저비용 고효율 추론 모델 학습의 가능성을 입증했으며, RLVR(Verifiable Rewards)과 GRPO 알고리즘이 새로운 표준으로 부상했다. 모델 아키텍처 면에서는 MoE와 효율적인 어텐션 메커니즘이 주류가 되었고, 단순 학습 데이터 증설을 넘어 추론 시간 스케일링(Inference-time scaling)과 도구 사용(Tool Use) 능력이 실질적인 성능 향상을 견인했다. 향후 2026년에는 이러한 기법들이 수학과 코딩을 넘어 다양한 도메인으로 확장될 것으로 전망된다.
배경
LLM 기본 아키텍처, 강화학습 기초, SFT/RLHF 개념
대상 독자
LLM 프로덕션 개발자 및 AI 연구원
의미 / 영향
LLM 개발 비용이 예상보다 낮아짐에 따라 독점적 모델의 우위가 약화되고, 기업들이 자체 보유한 도메인 특화 데이터를 활용해 고성능 맞춤형 모델을 구축하는 추세가 가속화될 것이다.
섹션별 상세
이미지 분석
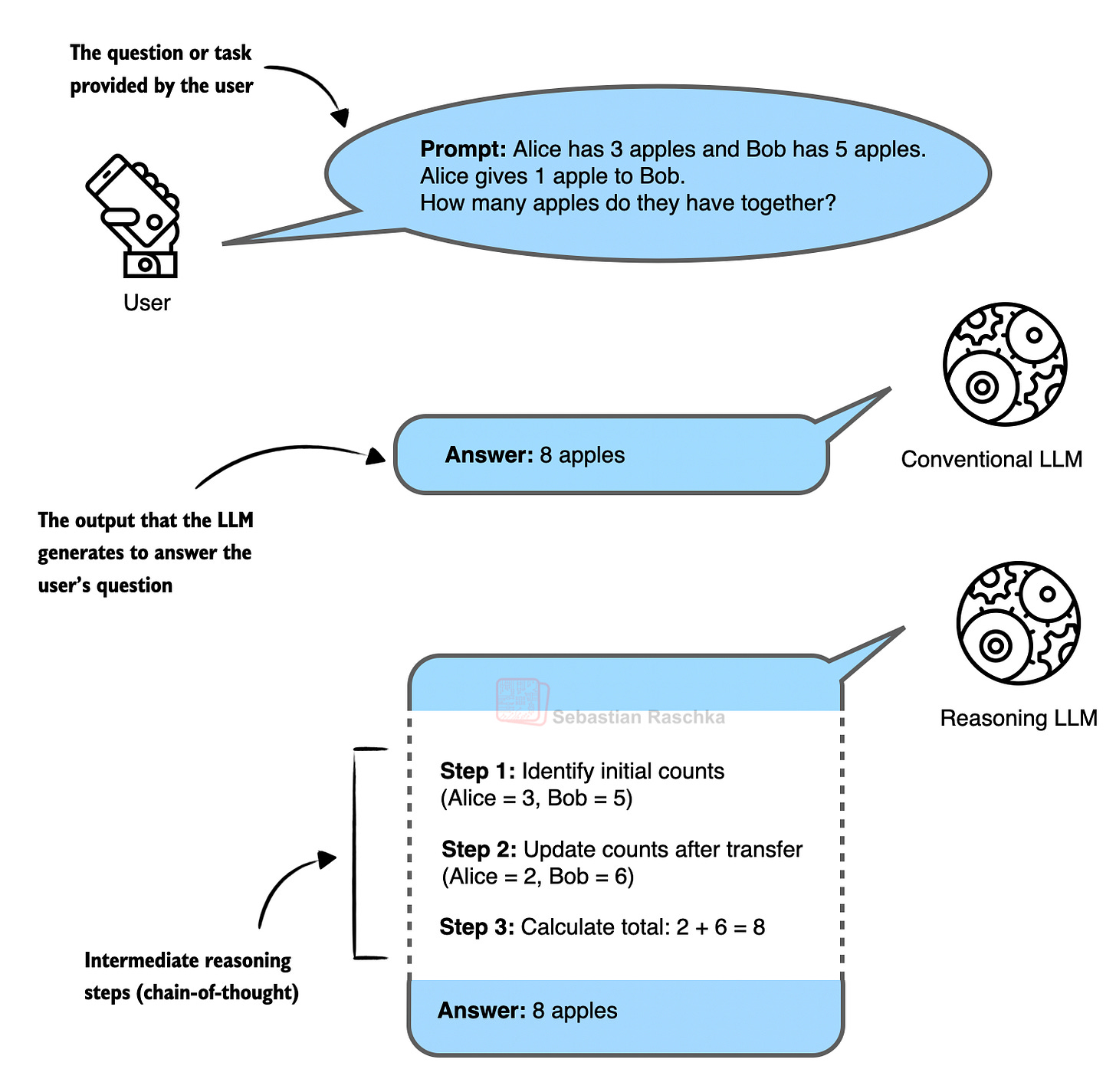
일반 모델은 정답만 출력하는 반면, 추론 모델은 중간 사고 과정(Chain-of-Thought)을 거쳐 정답을 도출함을 보여준다. 이러한 중간 단계가 답변의 정확도를 높이는 핵심 요소임을 시각화한다.
일반 LLM과 추론 LLM의 응답 방식 차이 비교
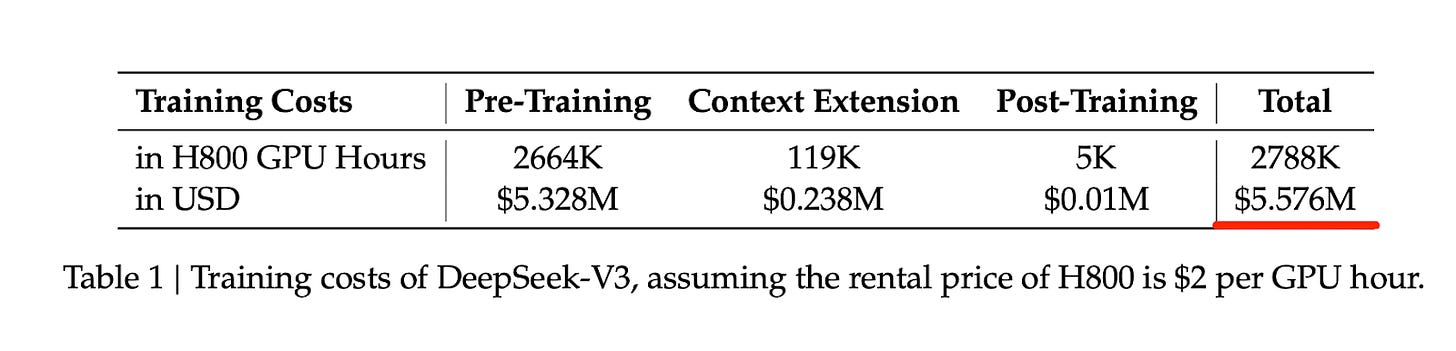
671B 파라미터 모델의 사전 학습 및 사후 학습 비용이 약 557만 달러임을 명시한다. 이는 최첨단 모델 학습 비용이 기존 수억 달러 예상치보다 훨씬 낮을 수 있음을 입증하는 근거 데이터다.
DeepSeek-V3 모델의 학습 비용 상세 내역
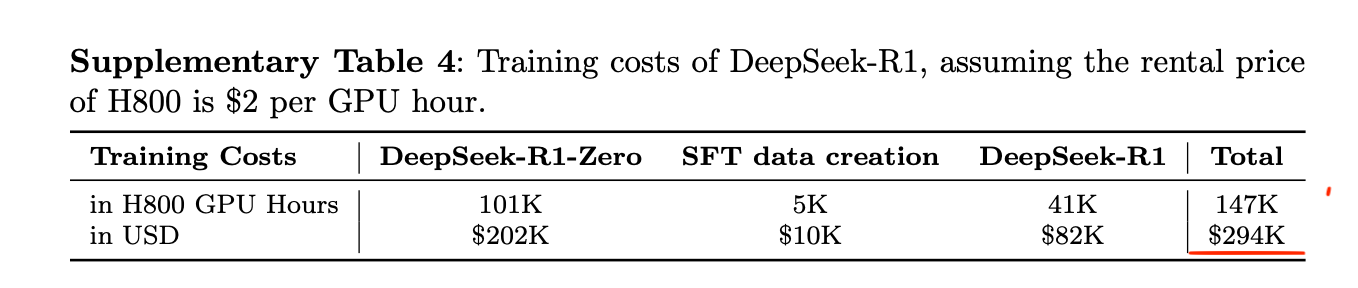
V3 모델 위에 R1 추론 능력을 추가하는 데 드는 비용이 약 29만 달러에 불과함을 보여준다. 효율적인 강화학습 기법이 모델 고도화 비용을 얼마나 절감할 수 있는지 구체적 수치로 제시한다.
DeepSeek-R1 모델의 추가 학습 비용

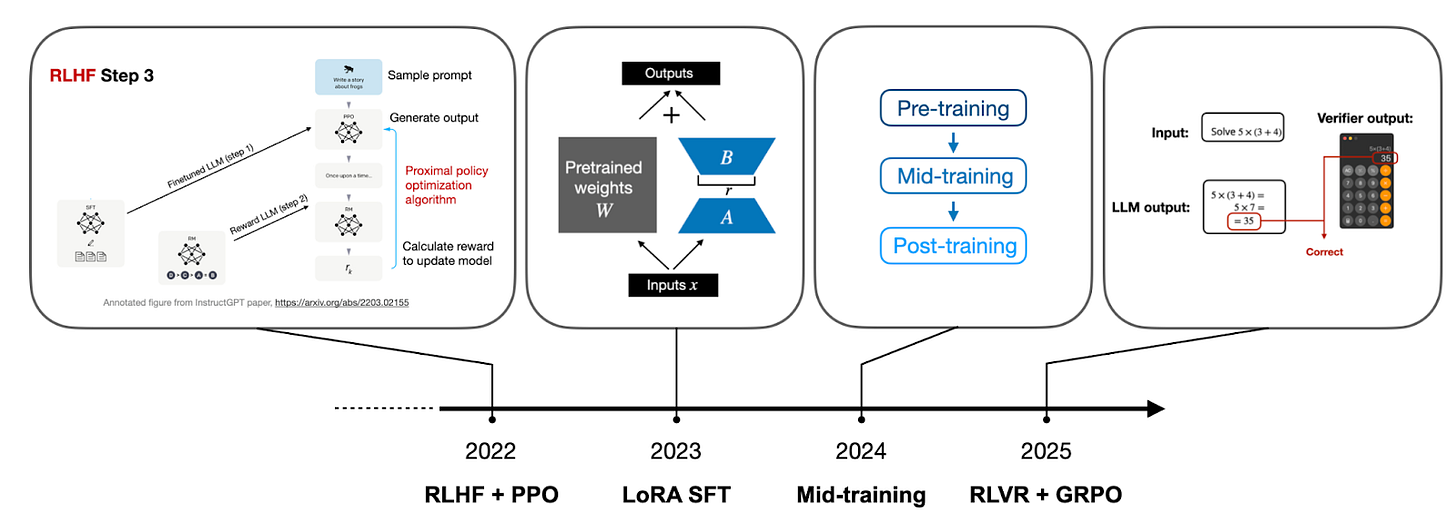
2022년부터 2025년까지 RLHF, LoRA, 미드 트레이닝, RLVR+GRPO로 이어지는 기술적 유행의 변화를 요약한다. 현재 시점에서 어떤 기술이 가장 활발하게 연구되고 있는지 한눈에 파악할 수 있게 돕는다.
연도별 LLM 개발 중점 기술 타임라인
자기 정제(Self-refinement) 반복 횟수가 늘어날수록 수학 문제 해결 정확도가 상승함을 보여준다. 학습뿐만 아니라 추론 단계에서의 연산 투입이 성능 향상의 중요한 레버임을 증명한다.
추론 시간 스케일링에 따른 정확도 향상 그래프
실무 Takeaway
- RLVR과 GRPO를 활용한 사후 학습은 수학, 코딩 등 정답 확인이 가능한 도메인에서 모델 성능을 비약적으로 향상시키는 가장 효율적인 방법이다.
- 실무에서는 단순 모델 크기 확장보다 추론 시간 스케일링과 도구 사용을 통해 특정 작업의 정확도를 높이는 것이 더 경제적일 수 있다.
- 벤치마크 점수에만 의존하지 말고, 실제 도메인 데이터와 도구 사용 시나리오를 바탕으로 모델의 실질적 문제 해결 능력을 직접 검증해야 한다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료