핵심 요약
DeepSeek V3.2는 이전 모델의 강점을 계승하면서도 효율성과 성능을 극대화한 최신 오픈 가중치 모델이다. 핵심은 MLA와 결합된 새로운 희소 어텐션(DSA) 메커니즘을 통해 긴 컨텍스트 처리 효율을 높이고, DeepSeekMath V2에서 검증된 자가 검증 및 정제 기법을 도입하여 추론 능력을 강화한 것이다. 또한 GRPO 알고리즘의 안정성을 개선하여 수학 및 에이전트 작업에서 독보적인 성능을 보여준다. 이 글은 V3부터 V3.2까지의 기술적 변천사를 아키텍처와 학습 파이프라인 관점에서 심도 있게 다룬다.
배경
Transformer Architecture, Reinforcement Learning (PPO/GRPO), Mixture of Experts (MoE), Attention Mechanisms (MLA, Sparse Attention)
대상 독자
LLM 아키텍처 설계자, 강화학습 연구원 및 AI 프로덕션 개발자
의미 / 영향
DeepSeek V3.2는 효율적인 아키텍처와 정교한 강화학습만으로 오픈소스 모델이 폐쇄형 플래그십 모델과 대등하게 경쟁할 수 있음을 증명했다. 특히 DSA와 RLVR의 진화는 향후 추론 특화 모델 개발의 표준이 될 가능성이 높으며, 추론 시간 스케일링의 실질적인 구현 방법을 제시했다.
섹션별 상세
이미지 분석
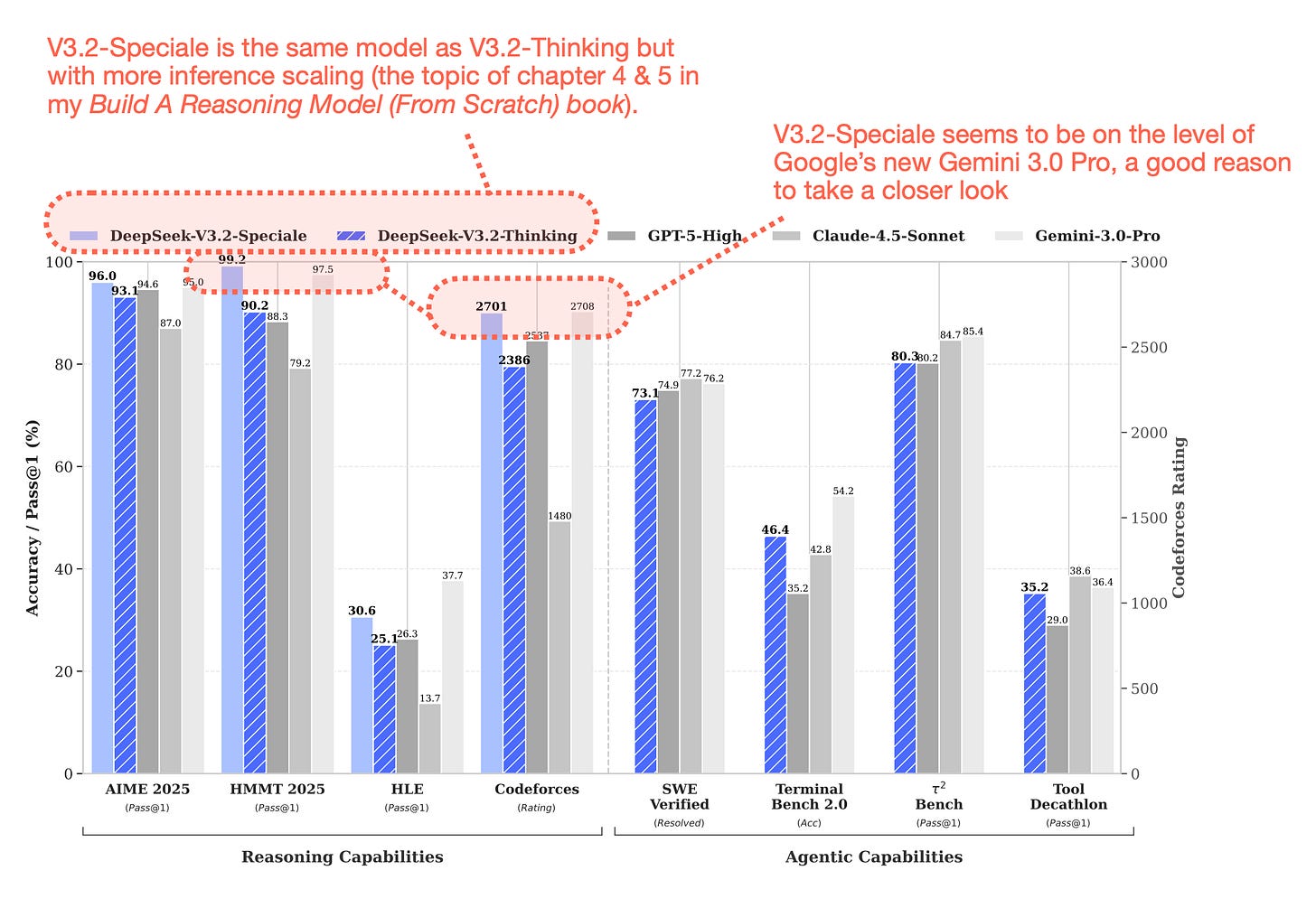
DeepSeek V3.2가 AIME 2025, HMMT 2025 등 수학 및 추론 벤치마크에서 GPT-5-High 및 Gemini 3.0 Pro와 대등하거나 우수한 성능을 보임을 나타낸다. 특히 추론 능력과 에이전트 능력 두 가지 측면에서 모델의 경쟁력을 시각화했다.
DeepSeek V3.2와 주요 상용 모델 간의 벤치마크 성능 비교 차트
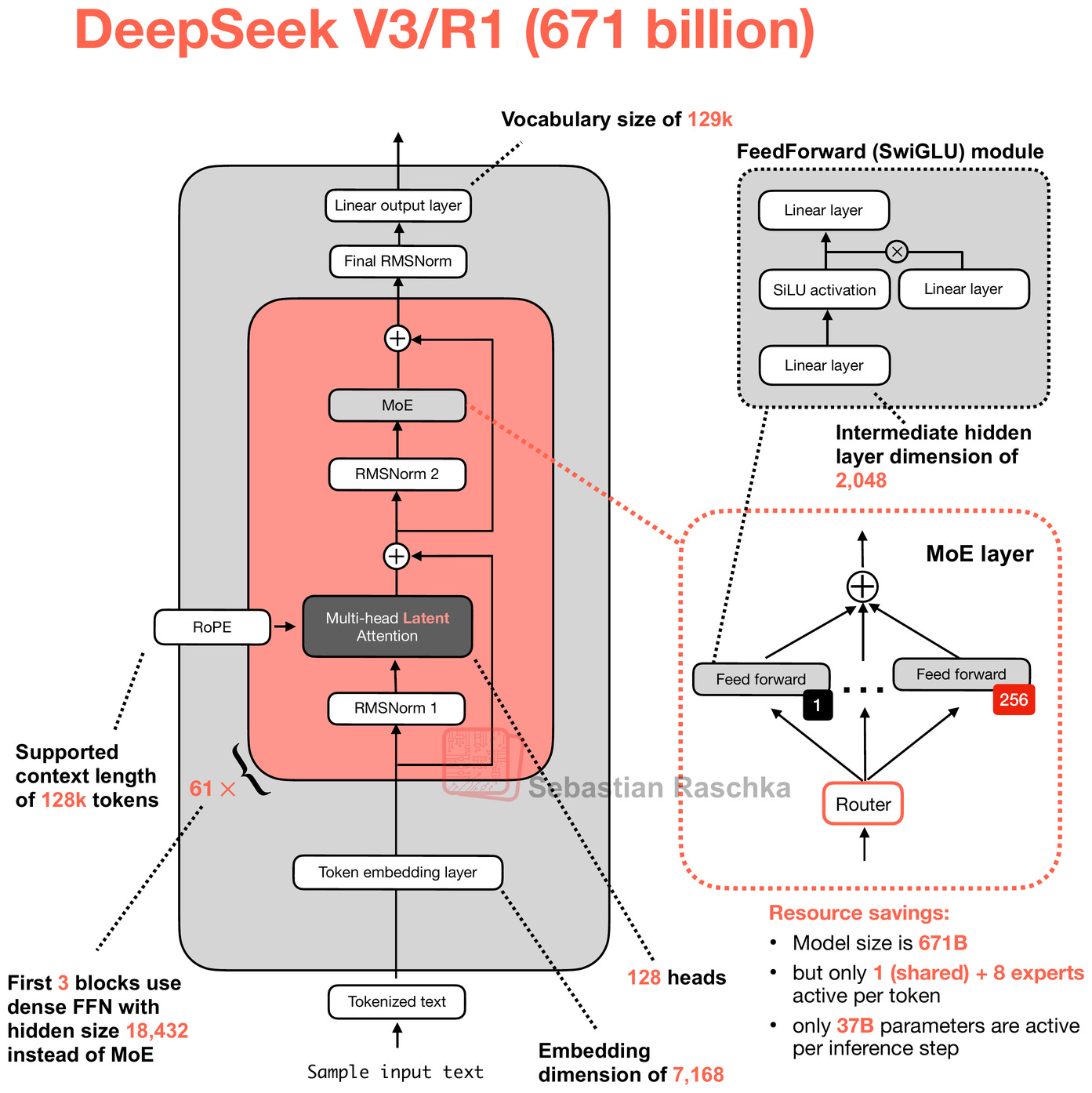
671B 파라미터 중 37B만 활성화되는 MoE 구조와 128k 컨텍스트 길이를 지원하는 아키텍처 세부 사항을 보여준다. V3.2의 기반이 되는 핵심 구조적 특징을 설명한다.
DeepSeek V3/R1의 Mixture-of-Experts(MoE) 기반 아키텍처 다이어그램
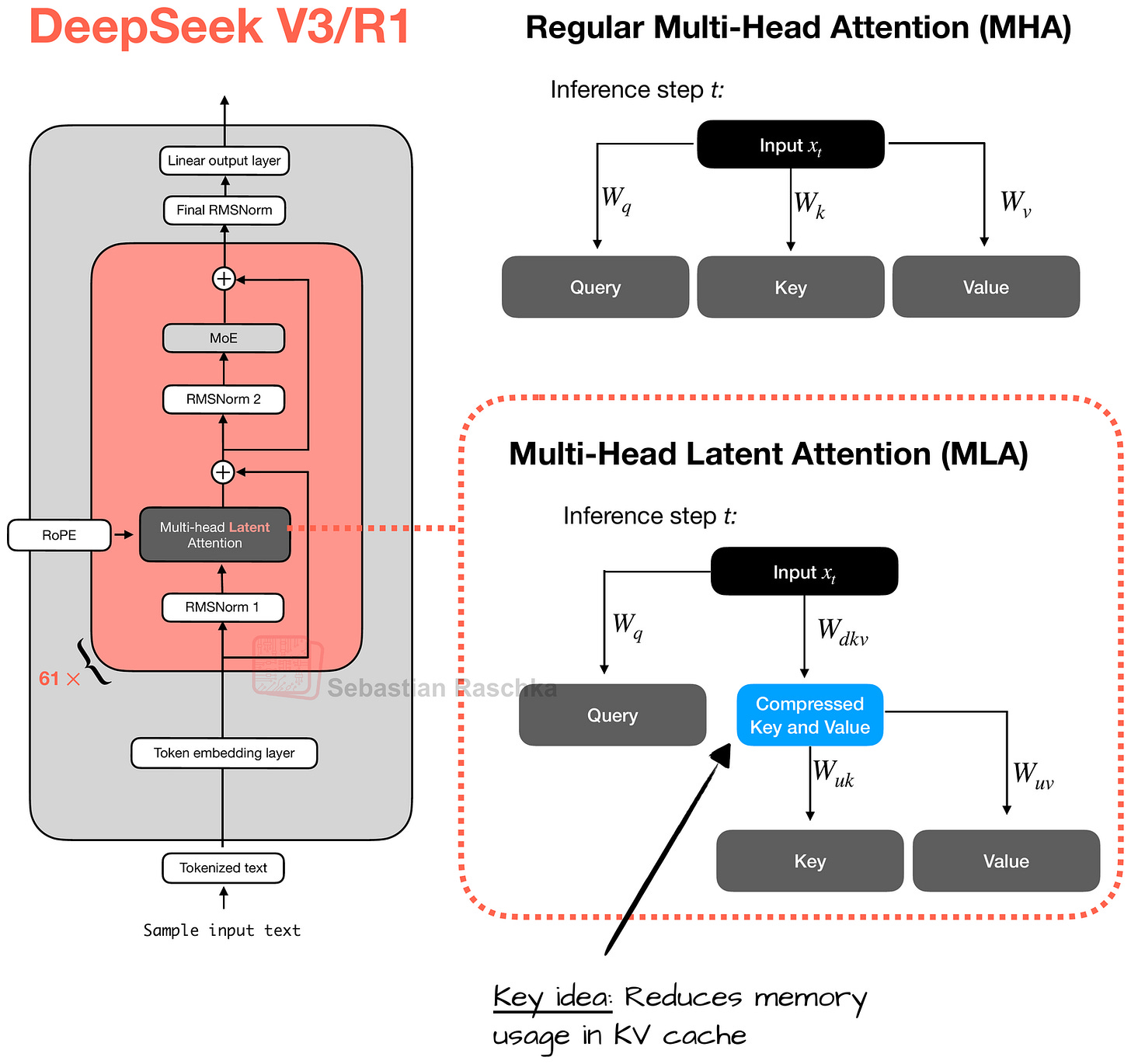
Key와 Value를 저차원 공간으로 압축하여 KV 캐시 메모리 사용량을 줄이는 MLA의 작동 원리를 일반적인 MHA와 비교하여 보여준다. 이는 DeepSeek 모델들의 높은 추론 효율성을 뒷받침하는 핵심 기술이다.
DeepSeek V3/R1의 Multi-Head Latent Attention(MLA) 메커니즘 상세도
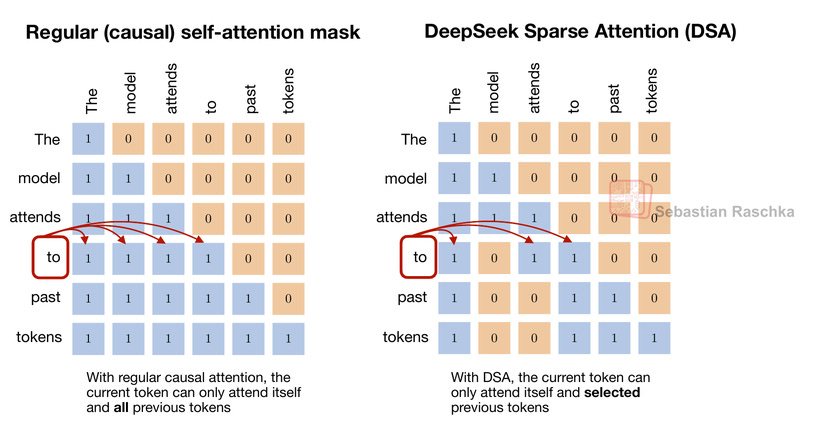
현재 토큰이 모든 이전 토큰이 아닌, 학습된 인덱서에 의해 선택된 특정 토큰들에만 어텐션을 수행하는 DSA의 희소성을 보여준다. 이를 통해 연산 복잡도를 O(L^2)에서 O(L*k)로 낮추는 원리를 설명한다.
DeepSeek Sparse Attention(DSA)의 어텐션 마스크 시각화
실무 Takeaway
- MLA와 DSA의 결합은 대규모 모델에서 KV 캐시 메모리 절약과 연산 효율성이라는 두 마리 토끼를 잡는 핵심 아키텍처 설계 패턴이다.
- 단순한 정답 기반 보상을 넘어 LLM 검증기를 통한 프로세스 보상(Process Reward)과 자가 정제 루프는 고도화된 추론 모델 구축의 필수 요소이다.
- GRPO의 안정화 기법(KL 가중치 튜닝, 오프-폴리시 마스킹 등)은 대규모 강화학습 시 발생할 수 있는 성능 저하와 불안정성을 해결하는 실무적 지침을 제공한다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료