핵심 요약
기존의 오프라인 벤치마크는 복잡한 다단계 워크플로우를 수행하는 AI 에이전트의 실제 성능을 측정하는 데 한계가 있다. 이를 해결하기 위해 작업 성공(Task Success), 도구 사용 정확도(Tool-Use Correctness), 에스컬레이션 품질(Escalation Quality)이라는 행동 중심의 평가 지표 도입이 필수적이다. 이러한 지표는 에이전트가 도구를 올바르게 선택하고, 불확실한 상황에서 적절히 인간에게 업무를 넘기는지를 평가하여 운영 리스크를 줄인다. 최종적으로 인간 참여형(Human-in-the-loop) 평가와 체계적인 파이프라인 구축을 통해 지속적인 모델 개선과 신뢰성 있는 배포가 가능해진다.
배경
LLM 에이전트 아키텍처에 대한 기본 이해, RAG 및 도구 호출(Tool Calling) 메커니즘 지식, MLOps 평가 파이프라인 개념
대상 독자
프로덕션 환경에서 AI 에이전트를 설계하고 배포하는 ML 엔지니어 및 제품 관리자
의미 / 영향
이 방법론은 AI 에이전트가 단순한 실험 단계를 넘어 실제 비즈니스 운영에 통합될 수 있는 신뢰성 기준을 제공한다. 특히 작업 성공, 도구 사용, 에스컬레이션이라는 구체적 지표는 기업이 AI 도입 시 겪는 리스크 관리 문제를 해결하는 데 핵심적인 역할을 할 것이다.
섹션별 상세
이미지 분석
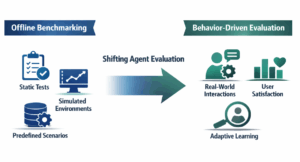
정적 테스트와 시뮬레이션 환경 중심의 기존 평가 방식이 실제 상호작용, 사용자 만족도, 적응형 학습을 중시하는 방식으로 변화해야 함을 시각화한다. 이는 에이전트 평가의 패러다임 시프트를 명확히 보여준다.
오프라인 벤치마킹에서 행동 중심 평가로의 전환을 보여주는 도식이다.
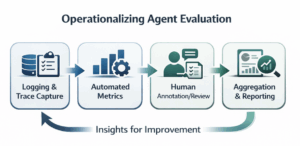
로깅 및 추적 캡처, 자동화된 지표 측정, 인간의 주석 및 검토, 보고서 생성으로 이어지는 순환 구조를 통해 지속적인 개선 통찰력을 얻는 과정을 나타낸다. 평가가 일회성이 아닌 지속적인 프로세스임을 강조한다.
에이전트 평가의 운영화 워크플로우 다이어그램이다.
실무 Takeaway
- 단일 응답 정확도 대신 전체 워크플로우의 엔드투엔드(End-to-End) 성공률을 측정하여 실제 비즈니스 가치를 평가해야 한다.
- 도구 사용 시 발생하는 매개변수 오류나 잘못된 순서 배치를 방지하기 위해 추적(Trace) 기반의 세부 분석을 도입한다.
- 에스컬레이션 품질 지표를 통해 에이전트의 한계를 명확히 관리하고 자동화 시스템의 안전 장치를 확보한다.
- 자동화된 지표와 인간의 정성적 평가를 결합한 지속적인 피드백 루프를 구축하여 프로덕션 환경의 에이전트 신뢰성을 극대화한다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료