이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
대다수의 대형 언어 모델(LLM)은 영어 데이터 중심으로 학습되어 글로벌 시장 배포 시 문화적 오해나 성능 저하를 겪는다. 이를 해결하기 위한 모델 현지화 서비스는 언어적 적응, 문화적 정렬, 규제 준수라는 세 가지 계층을 통해 모델의 내부 로직을 미세 조정한다. iMerit은 SFT, RLHF, 문화적 레드팀 활동을 결합하여 현지 전문가의 피드백을 모델에 반영함으로써 신뢰할 수 있는 글로벌 AI 구축을 지원한다. 결과적으로 현지화된 모델은 사용자 신뢰를 높이고 법적 리스크를 줄이며 비영어권 시장에서의 경쟁력을 확보하게 한다.
배경
LLM 미세 조정(Fine-tuning)에 대한 기본 이해, SFT 및 RLHF의 개념적 지식, 글로벌 서비스 배포 및 현지화 전략에 대한 관심
대상 독자
글로벌 시장 진출을 준비하는 AI 프로덕트 매니저 및 LLM 개발자
의미 / 영향
AI 모델의 글로벌 경쟁력은 단순한 성능을 넘어 현지 문화와 규제에 대한 적응력에 의해 결정될 것이다. 전문적인 현지화 서비스는 기업이 비영어권 시장에서 발생할 수 있는 윤리적, 법적 리스크를 줄이면서 사용자 경험을 극대화하는 필수적인 전략으로 자리 잡을 전망이다.
섹션별 상세
모델 현지화는 단순 번역이 아닌 언어, 문화, 규제의 세 가지 핵심 계층에서 모델의 내부 로직을 미세 조정하는 과정이다. 언어적 측면에서는 지역 방언과 코드 스위칭을 학습하고, 문화적 측면에서는 현지 관습과 유머를 반영하며, 규제 측면에서는 지역 데이터 보호법과 산업 표준을 준수하도록 설계한다.
현지화 프로세스는 고품질의 현지 데이터 큐레이션에서 시작된다. 뉴스, 법전, 소셜 미디어 등 실제 사용되는 데이터를 수집하고 필터링하여 모델이 번역된 텍스트가 아닌 실제 현지 언어 사용 패턴을 학습하도록 유도한다.
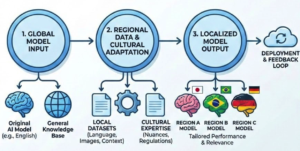
지도 미세 조정(SFT) 단계에서는 현지 언어 전문가가 작성한 고품질 Q&A 쌍을 사용하여 모델을 훈련시킨다. 이를 통해 모델은 해당 시장의 전문적, 사회적 맥락에 적합한 응답 방식을 습득하며 언어적 정확도와 문맥적 적절성을 동시에 확보한다.
인간 피드백 기반 강화학습(RLHF)은 현지 평가자가 모델의 응답을 직접 평가하고 순위를 매기는 방식으로 진행된다. 지역마다 문화적 표준이 다르기 때문에 현지 거주자의 피드백을 통해 보상 모델을 훈련시키는 것이 모델의 행동을 지역적 가치관에 일치시키는 핵심 요소이다.

문화적 레드팀 활동은 지역적 정치 위기나 민감한 사회적 사건을 포함한 프롬프트를 사용하여 모델의 취약점을 테스트하는 안전 조치이다. 이를 통해 출시 전 편향되거나 유해한 콘텐츠 생성을 방지하고 기업의 평판 리스크를 관리한다.
iMerit은 전 세계 60개국 이상의 전문가 네트워크와 Ango Deep Reasoning Lab 플랫폼을 활용하여 복잡한 현지화 작업을 수행한다. 전문가들이 사고의 사슬(Chain of Thought) 기법을 사용하여 모델의 추론 과정을 단계별로 분석하고, HIPAA 및 GDPR 등 글로벌 보안 표준을 준수하는 워크플로우를 통해 안전한 배포를 보장한다.
실무 Takeaway
- 글로벌 시장 진출 시 단순 번역을 넘어 현지 전문가의 SFT와 RLHF 데이터를 활용하여 모델의 문화적 추론 능력을 강화해야 한다.
- 지역별로 상이한 데이터 보호법(GDPR, HIPAA 등)을 준수하기 위해 모델 학습 및 배포 워크플로우에 규제 준수 자동화 도구를 통합해야 한다.
- 저자원 언어(Low-resource languages)의 경우 데이터 증강 기법과 현지 언어학자의 검수를 병행하여 학습 데이터의 품질과 양을 확보하는 전략이 필요하다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 03. 17.수집 2026. 03. 17.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.