이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
RAG 기반 AI 에이전트 구축 시 비정형 문서에서 정확한 데이터를 추출하는 것은 큰 도전 과제이다. Langflow 1.6은 오픈소스 문서 처리기인 Docling을 File 컴포넌트에 통합하여 이 문제를 해결했다. 사용자는 표준 파이프라인이나 VLM 기반 파이프라인을 선택하여 PDF를 구조화된 Markdown으로 변환할 수 있다. 이렇게 변환된 데이터는 단순 요약부터 복잡한 RAG 인제스션 파이프라인 구축까지 폭넓게 활용 가능하다.
배경
Langflow 1.6 이상 설치, 기본적인 RAG 개념 이해, JavaScript/TypeScript 기초 (API 통합 시 필요)
대상 독자
Langflow를 사용하여 RAG 시스템이나 AI 에이전트를 구축하려는 개발자
의미 / 영향
Docling의 통합으로 Langflow 사용자들은 복잡한 코딩 없이도 고성능 문서 파싱 기능을 사용할 수 있게 되었다. 이는 RAG 파이프라인의 데이터 품질을 획기적으로 개선하여 LLM의 답변 정확도를 높이는 데 기여할 것이다.
섹션별 상세
Docling은 IBM이 개발한 오픈소스 문서 프로세서로, PDF, DOCX, 이미지 등 다양한 형식을 처리하여 생성형 AI에 적합한 깨끗한 콘텐츠를 생성한다. OCR 기술과 레이아웃 분석 기법을 사용하거나 Granite-Docling-258M과 같은 Vision Language Model(VLM)을 활용해 문서의 읽기 순서와 구조를 파악한다. Langflow 1.5에서 처음 도입된 이후 1.6 버전에서는 File 컴포넌트의 고급 파서 기능을 통해 더욱 강력하게 통합되었다.
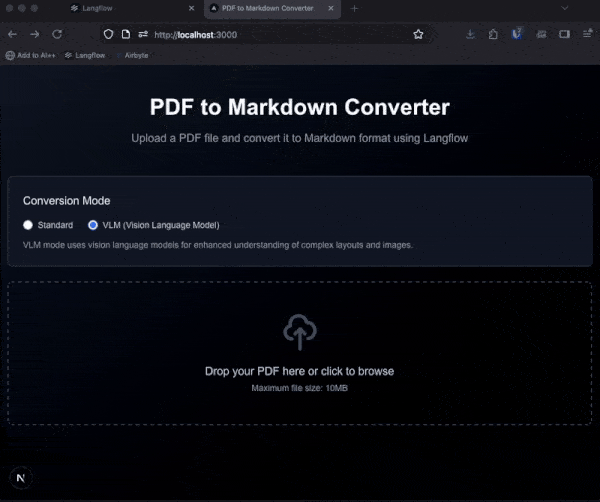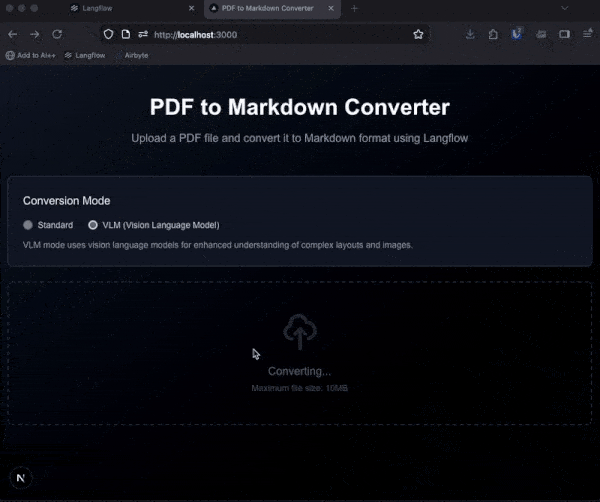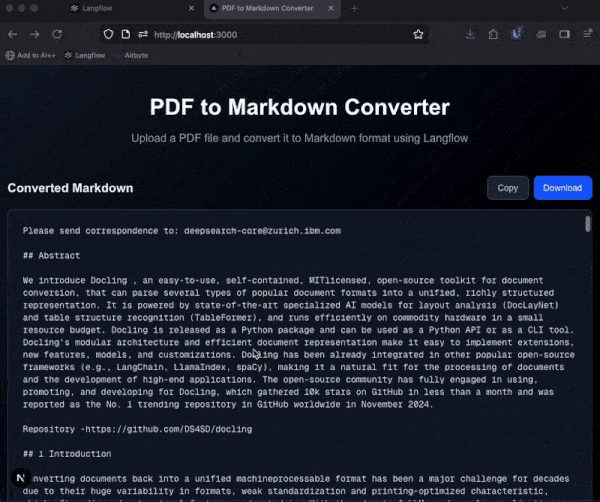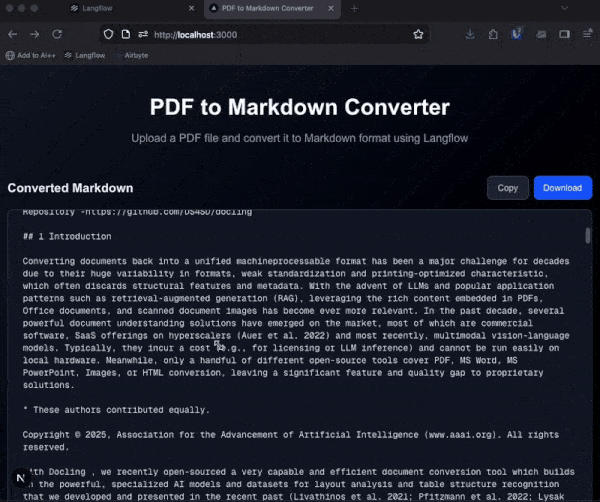
Langflow 내에서 PDF를 파싱하는 과정은 File 컴포넌트와 Chat Output 컴포넌트를 연결하는 것만으로 시작할 수 있다. 기본 파서는 텍스트 스트림 위주로 추출하지만, Advanced Parser를 활성화하면 Docling의 강력한 기능을 사용할 수 있다. 사용자는 표준 Docling 파이프라인, EasyOCR 엔진 추가, 또는 VLM 전용 파이프라인 중 하나를 선택하여 문서의 헤더와 구조를 보존한 Markdown 출력을 얻을 수 있다.

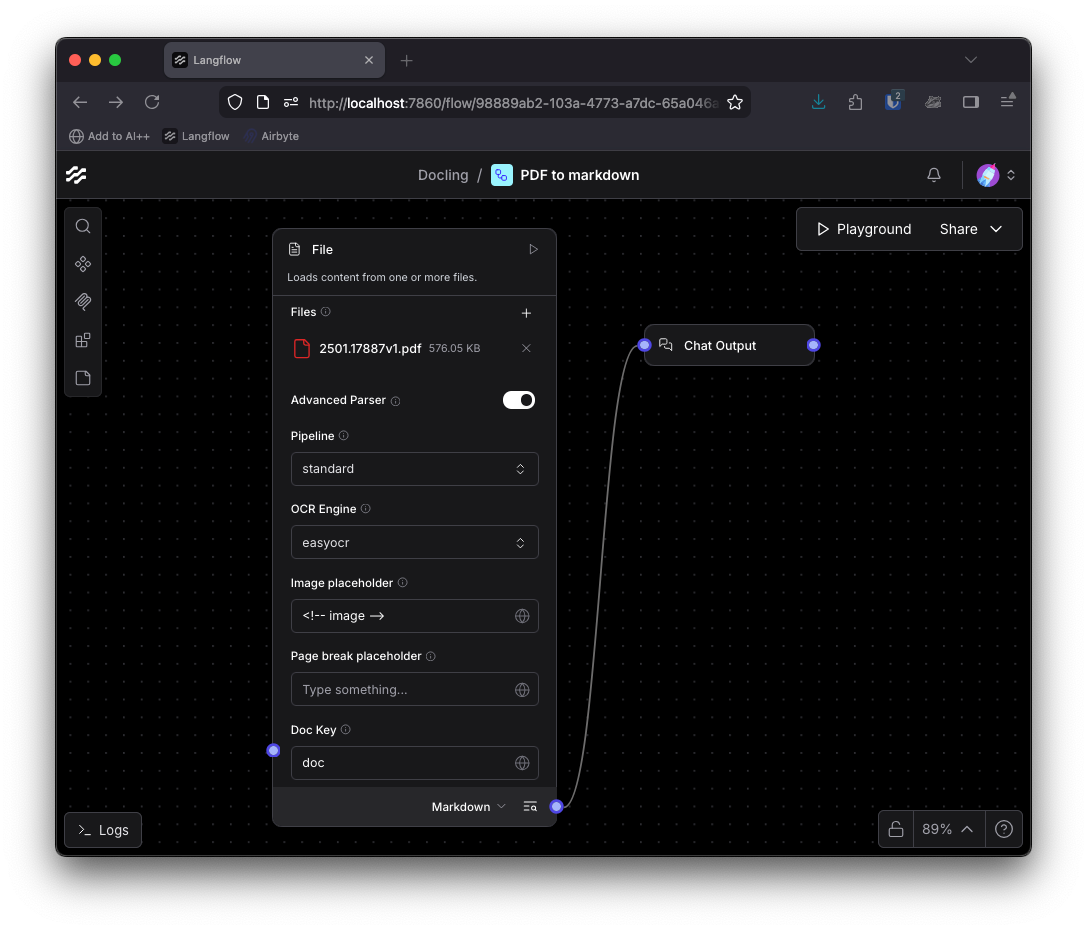
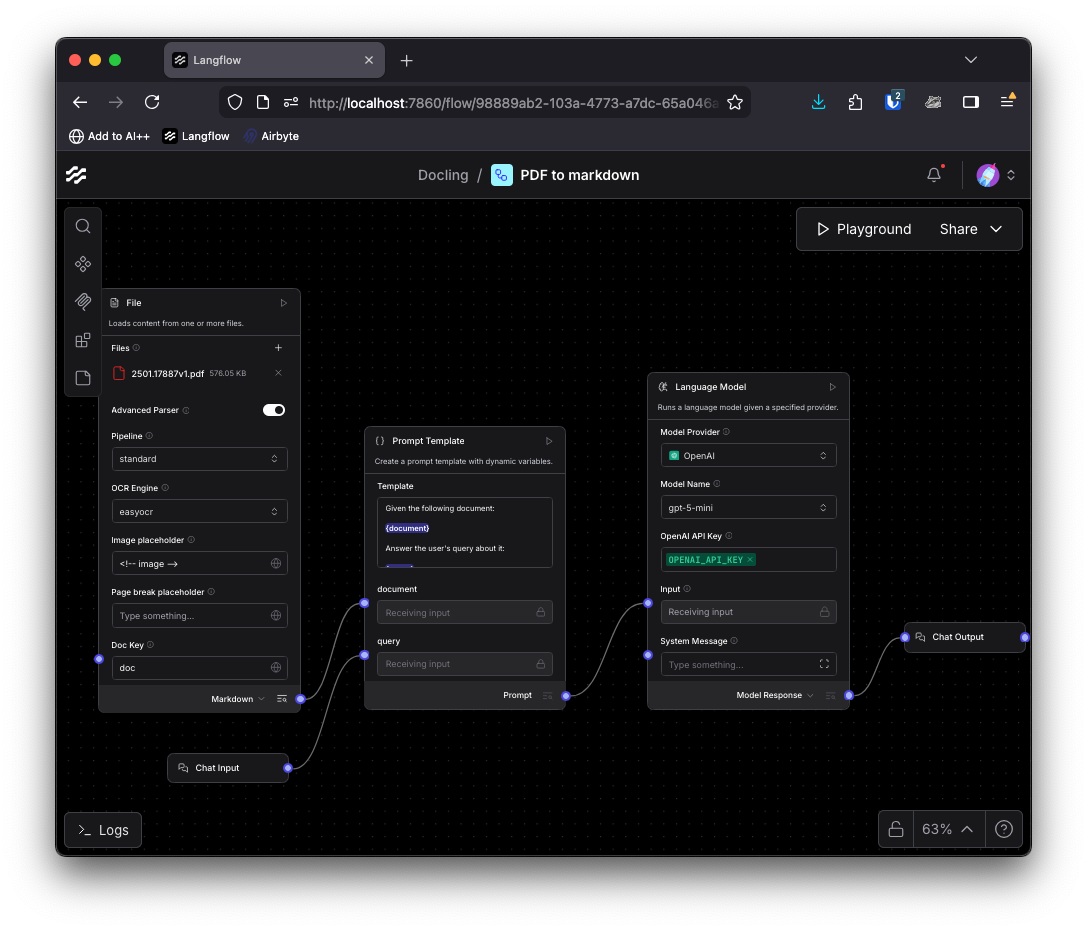
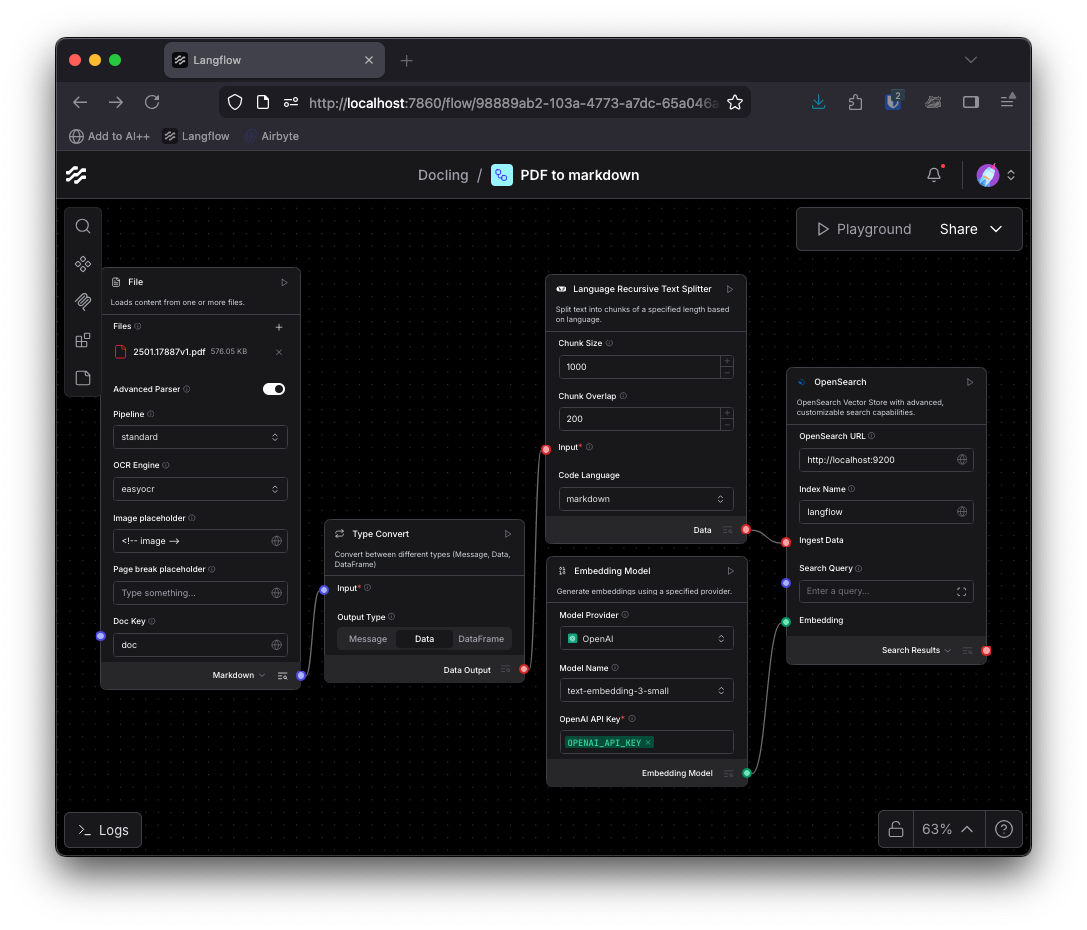
추출된 Markdown 데이터는 다양한 AI 애플리케이션의 기초가 된다. Prompt Template과 LLM을 연결하여 PDF 내용으로 대화하는 챗봇을 만들거나, Type Convert 컴포넌트를 거쳐 LangChain의 Recursive Text Splitter로 텍스트를 분할할 수 있다. 이후 임베딩 모델과 OpenSearch 같은 벡터 데이터베이스를 연결하면 문서 구조를 반영한 고품질 RAG 인제스션 파이프라인이 완성된다.
개발자는 Langflow API와 JavaScript 클라이언트를 사용하여 이 기능을 자신의 애플리케이션에 통합할 수 있다. 먼저 파일을 Langflow 서버에 업로드한 후, 반환된 파일 경로를 tweak 파라미터로 전달하여 플로우를 실행하는 방식이다. 이를 통해 사용자가 업로드한 문서를 실시간으로 파싱하고 처리하는 웹 서비스를 구축할 수 있다.
javascript
import { LangflowClient } from "@datastax/langflow-client";
const client = new LangflowClient({
baseUrl: process.env.LANGFLOW_BASE_URL,
apiKey: process.env.LANGFLOW_API_TOKEN,
});
const flow = client.flow(process.env.LANGFLOW_FLOW_ID);
// Step 1: Upload the file to Langflow
const uploadResponse = await client.files.upload(file);
// Step 2: Run the flow with the uploaded file path and pipeline mode as tweaks
const fileComponentName = process.env.LANGFLOW_FILE_COMPONENT_NAME;
const response = await flow
.tweak(fileComponentName, {
path: uploadResponse.path,
pipeline: mode,
})
.run("");Langflow JavaScript 클라이언트를 사용하여 파일을 업로드하고 파이프라인 모드를 조정하여 플로우를 실행하는 예시 코드
실무 Takeaway
- 비정형 PDF 데이터를 RAG에 활용하려면 Langflow 1.6의 File 컴포넌트에서 Advanced Parser를 활성화하여 Docling 기반의 구조화된 Markdown 추출을 수행해야 한다.
- 문서의 복잡도에 따라 표준 Docling 파이프라인이나 VLM 파이프라인을 선택적으로 적용하여 OCR 정확도와 레이아웃 보존 성능을 최적화할 수 있다.
- Langflow Client SDK를 사용하면 파일 업로드와 tweak 기능을 조합해 외부 앱에서도 Docling의 강력한 파싱 기능을 API 형태로 호출하여 사용할 수 있다.
언급된 리소스
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2025. 11. 28.수집 2026. 02. 21.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.