핵심 요약
전통적인 소프트웨어 테스트는 결정론적 출력에 의존하지만, 자연어를 생성하고 도구를 사용하는 AI 에이전트는 동일한 입력에도 다양한 결과를 내놓아 평가가 어렵다. Strands Evals는 이러한 문제를 해결하기 위해 LLM을 판정관으로 사용하는 판단 기반 평가 프레임워크를 제공한다. 이 가이드는 Case, Experiment, Evaluator라는 핵심 개념을 바탕으로 실시간 개발 단계와 과거 데이터 분석 모두에서 에이전트의 성능을 측정하는 방법을 설명한다. 특히 사용자 시뮬레이터를 통한 멀티턴 대화 테스트와 도구 호출, 개별 턴, 전체 세션에 이르는 계층적 평가 구조를 통해 에이전트의 신뢰성을 확보하는 구체적인 방안을 제시한다.
배경
Python 프로그래밍 지식, LLM API 사용 경험, AI 에이전트 기본 개념 (Tool use, RAG 등)
대상 독자
프로덕션 환경에서 AI 에이전트를 개발하고 성능을 최적화하려는 엔지니어 및 MLOps 전문가
의미 / 영향
에이전트 평가의 표준화된 프레임워크를 제공함으로써 개발자가 감에 의존하지 않고 데이터 기반으로 모델이나 프롬프트를 개선할 수 있게 한다. 이는 에이전트 기술의 실무 도입 장벽을 낮추는 데 기여한다.
섹션별 상세
from strands_evals import Case
case = Case(
name="Weather Query",
input="What is the weather like in Tokyo?",
expected_output="Should include temperature and conditions",
expected_trajectory=["weather_api"]
)테스트 시나리오를 정의하는 Case 객체 생성 예시
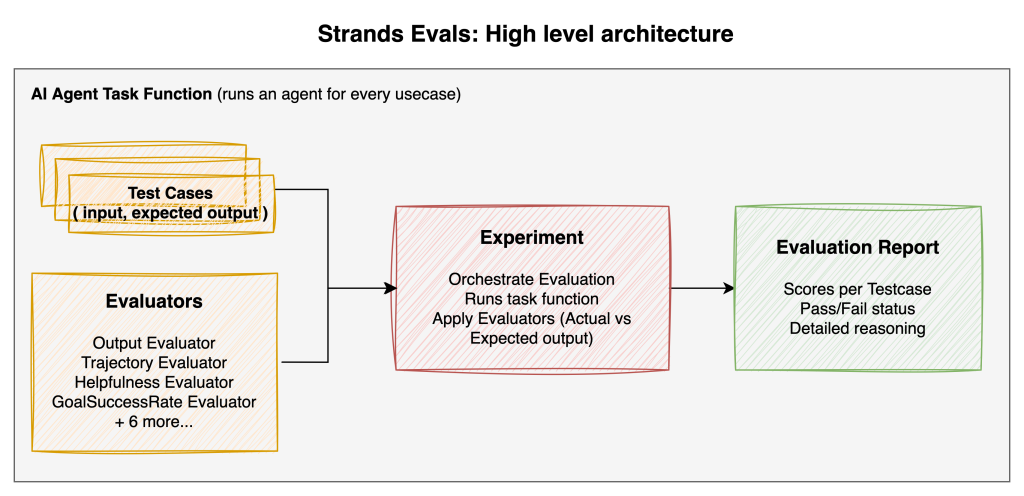
def online_task(case):
agent = Agent(tools=[search_tool, calculator_tool])
result = agent(case.input)
return {
"output": str(result),
"trajectory": agent.session
}실시간 에이전트 호출을 통한 온라인 평가용 Task Function 구현


user_sim = ActorSimulator.from_case_for_user_simulator(
case=case,
max_turns=10
)
while user_sim.has_next():
agent_response = agent(user_message)
user_result = user_sim.act(str(agent_response))
user_message = str(user_result.structured_output.message)ActorSimulator를 활용한 멀티턴 대화 시뮬레이션 루프
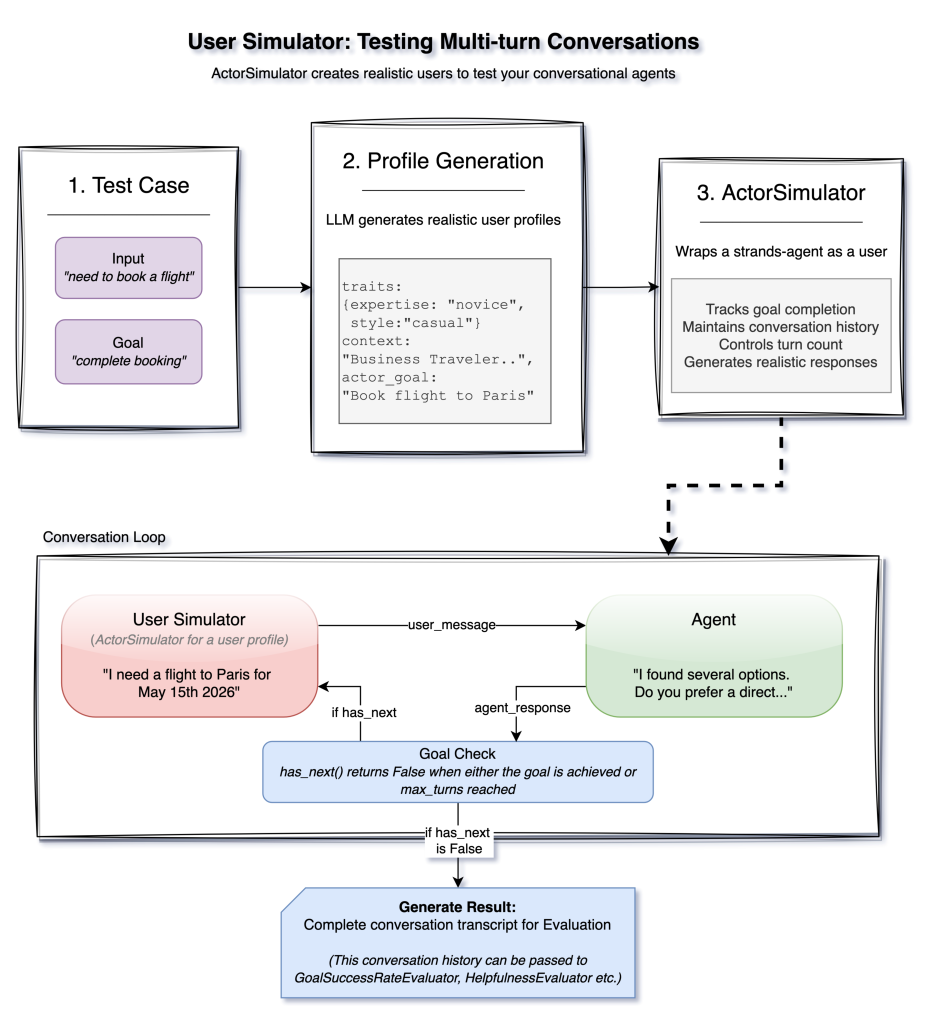
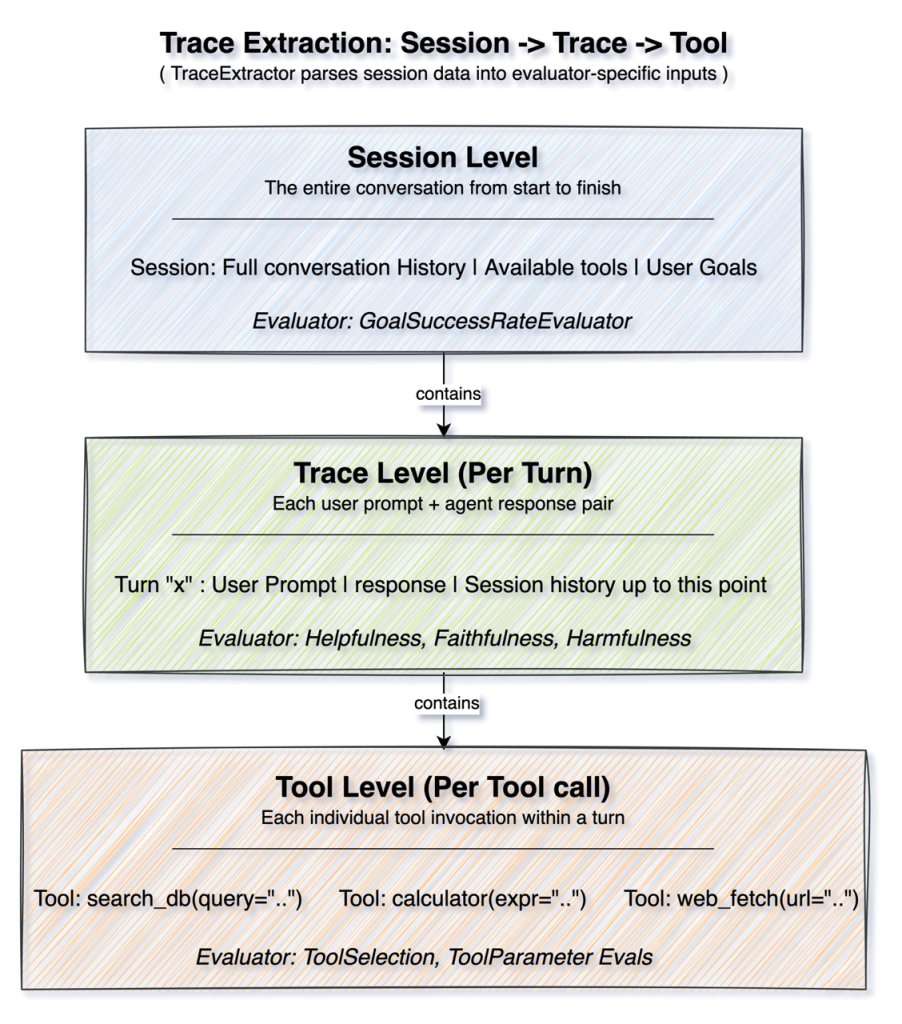
실무 Takeaway
- 비결정적인 에이전트 출력 검증을 위해 단순 어설션 대신 LLM 기반의 루브릭 평가기를 도입하여 응답의 유용성과 성실성을 정량화해야 한다.
- 도구 호출이 잦은 에이전트의 경우 최종 응답뿐만 아니라 TrajectoryEvaluator를 사용해 도구 선택의 적절성과 파라미터 정확도를 단계별로 검증해야 한다.
- CI/CD 파이프라인에 Strands Evals를 통합하여 배포 전 성능 저하를 방지하고, 운영 환경에서는 오프라인 평가를 통해 실제 사용자 패턴에서의 드리프트를 감시해야 한다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.