이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
코드 데이터는 함수나 클래스 같은 계층 구조를 가져 일반 텍스트용 청킹을 적용하면 논리적 맥락이 끊기는 문제가 발생한다. 이 아티클은 고정 크기(Naive), 언어 인식(LangChain), AST 기반(Tree-sitter)의 세 가지 청킹 전략을 Databricks Knowledge Assistant에 적용해 비교한다. 46개의 질문 데이터셋과 MLflow 평가 프레임워크를 사용해 분석한 결과, AST 기반 방식이 70%의 정답 정확도를 기록하며 가장 우수한 성능을 보였다. 구조적 맥락을 보존하는 청킹이 개발자용 지식 어시스턴트의 실무적 유용성을 결정짓는 핵심 요소임이 확인됐다.
배경
RAG (Retrieval-Augmented Generation) 기본 개념, AST (Abstract Syntax Tree)에 대한 이해, MLflow 평가 프레임워크 사용 경험
대상 독자
코드베이스 기반 RAG 시스템을 구축하거나 LLM 성능 최적화를 고민하는 AI 엔지니어
의미 / 영향
코드 데이터의 특수성을 고려한 전처리가 RAG 성능의 병목을 해결하는 핵심임을 보여준다. 특히 AST 기반 청킹은 개발 도구용 AI 에이전트의 신뢰도를 높여 실무 도입 가능성을 확장하는 중요한 기법으로 자리 잡을 것이다.
섹션별 상세
코드 RAG는 일반 문서와 달리 중첩된 계층 구조를 가지며 함수 단위가 의미의 최소 단위가 된다. 단순 텍스트 분할은 함수 중간을 잘라버려 모델이 로직을 이해하지 못하게 만들며, 이를 해결하기 위해 파일 경로와 함수 계층 구조를 포함하는 메타데이터 헤더가 필수적이다.
세 가지 청킹 전략 중 AST 기반 방식은 Tree-sitter를 사용해 구문 트리를 분석하고 의미적 경계에서 분할하며 메타데이터를 추가해 검색 품질을 높인다. 반면 고정 크기 방식은 구현이 쉽지만 구문을 무시하며, 언어 인식 방식은 예약어를 기준으로 분할하지만 여전히 크기 제한에 의해 맥락이 끊기는 한계가 존재한다.
MLflow의 GenAI 평가 프레임워크를 통해 46개의 질문으로 구성된 데이터셋에서 검색 충분성, 근거성, 정답 정확도를 측정했다. 특히 비슷한 이름의 함수가 여러 곳에 존재하는 '모호성 해소' 질문에서 AST 방식이 메타데이터를 통해 맥락을 제공함으로써 가장 뛰어난 성능을 입증했다.
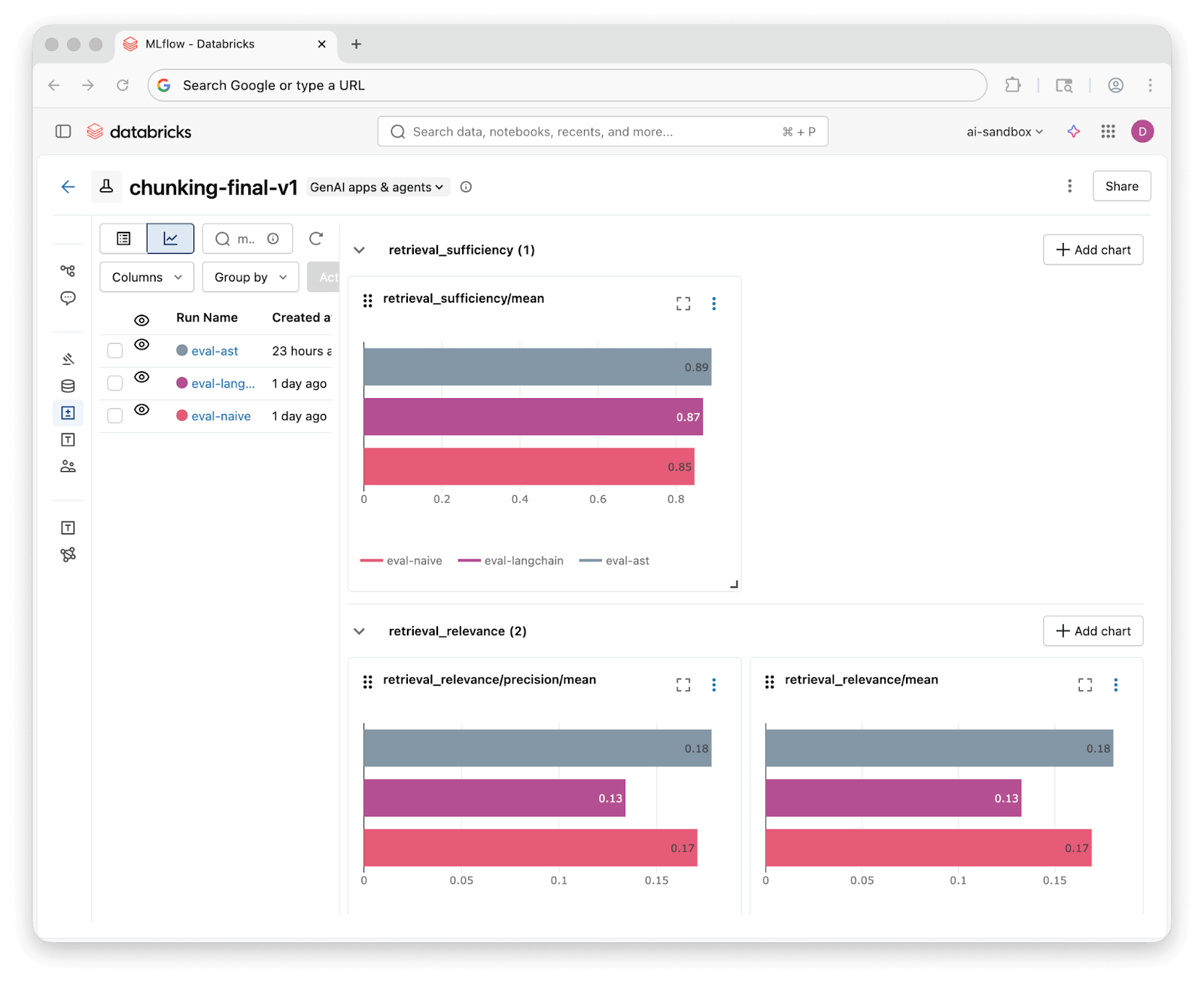
실험 결과 모든 전략이 85% 이상의 검색 충분성을 보였으나 최종 정답의 완전성은 AST 방식(70%)이 Naive(59%)보다 월등히 높았다. 이는 검색된 컨텍스트의 질이 생성 결과의 정확도로 직결됨을 보여주며, MLflow Trace를 통한 단계별 추적과 디버깅이 RAG 최적화에 중요함을 시사한다.
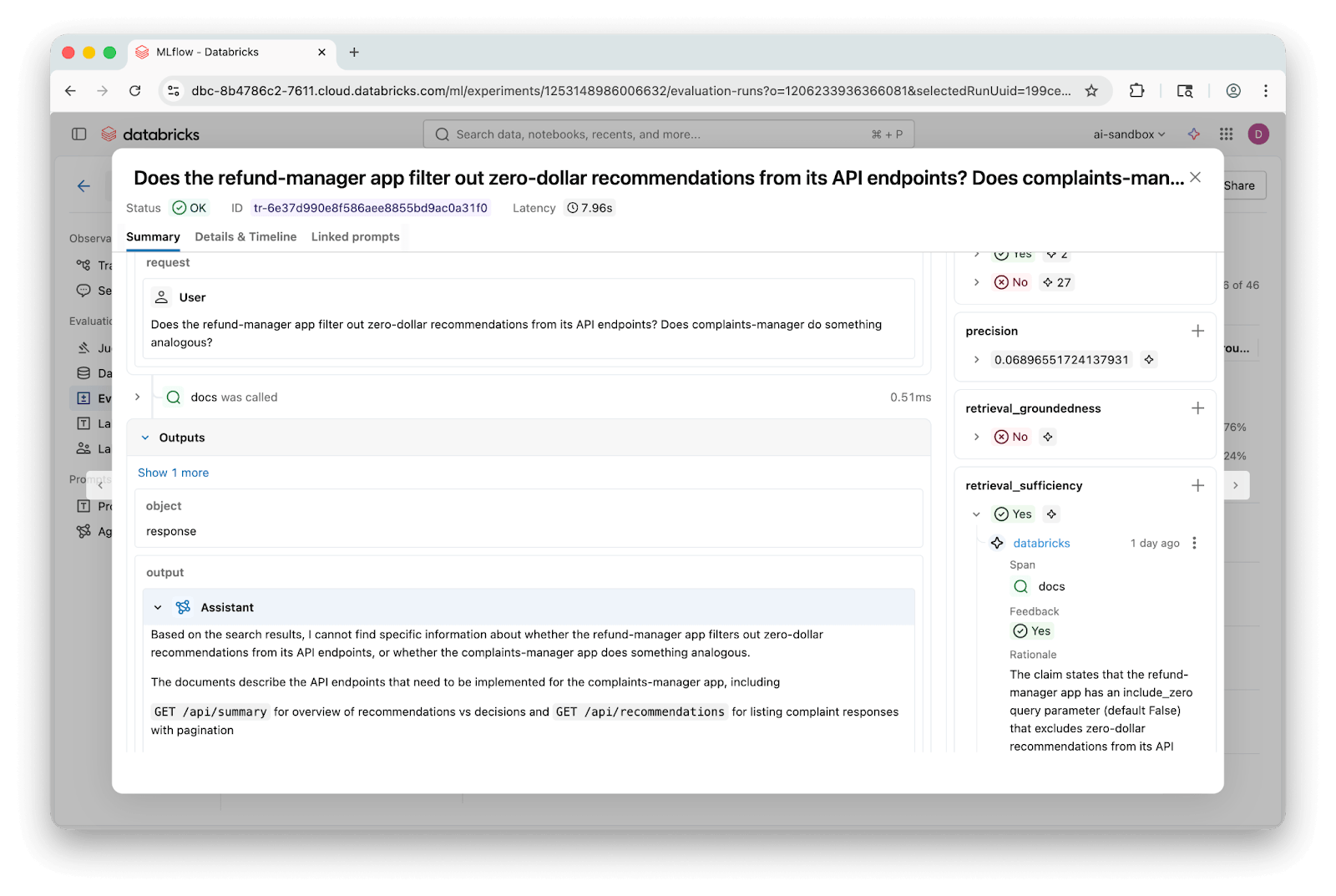
실무 Takeaway
- 코드 RAG 구축 시 단순 고정 크기 분할 대신 AST(Abstract Syntax Tree)를 활용해 함수와 클래스 경계를 보존하면 답변 정확도를 10% 이상 향상시킬 수 있다.
- 청킹된 코드 조각 상단에 파일 경로와 함수 계층 구조를 메타데이터 헤더로 추가하면 대규모 코드베이스에서 발생하는 모델의 컨텍스트 혼동을 효과적으로 방지한다.
- MLflow의 GenAI 평가 프레임워크와 커스텀 LLM Judge를 활용해 RAG 파이프라인의 변경 사항이 실제 답변 품질에 미치는 영향을 정량적으로 관리해야 한다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 03. 24.수집 2026. 03. 24.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.