핵심 요약
GPU 커널 프로그래밍에서 다차원 데이터를 물리적 메모리 주소로 매핑하는 효율적인 구조 설계는 성능 최적화의 핵심이다. AMD의 Composable Kernel(CK)은 TensorDescriptor라는 추상화 계층을 도입하여 논리적 좌표를 물리적 오프셋으로 변환하는 계층적 변환 트리를 제공한다. 본문은 Embed, Unmerge, Merge 등의 변환을 조합하여 복잡한 레이아웃을 구성하는 방법과 이를 실제 행렬 전치 커널에 적용하는 과정을 상세히 설명한다. AMD MI308X 환경에서 테스트한 결과, 이 방식을 적용한 커널은 PyTorch 대비 약 44.3%의 성능 향상을 기록했다.
배경
C++ Template Programming, GPU Architecture (CU, VGPR, Global Memory), Matrix Operations Basics
대상 독자
AMD ROCm 플랫폼에서 고성능 GPU 커널을 직접 설계하고 최적화하려는 AI/HPC 개발자
의미 / 영향
이 기술은 AMD GPU의 하드웨어 잠재력을 최대한 끌어내어 PyTorch와 같은 범용 프레임워크보다 높은 성능의 커널을 구축할 수 있게 한다. 특히 대규모 언어 모델(LLM)이나 복잡한 행렬 연산이 필요한 AI 워크로드에서 비용 대비 성능을 최적화하는 데 중요한 역할을 할 것으로 기대된다.
섹션별 상세
auto tensor_desc = make_naive_tensor_descriptor(make_tuple(M, K), make_tuple(K, 1));
auto transformed_tensor_desc = transform_tensor_descriptor(
tensor_desc,
make_tuple(unmerge, passthrough),
make_tuple(Sequence<0>{}, Sequence<1>{}), // Lower dimension ids
make_tuple(Sequence<0, 1>{}, Sequence<2>{}) // Upper dimension ids
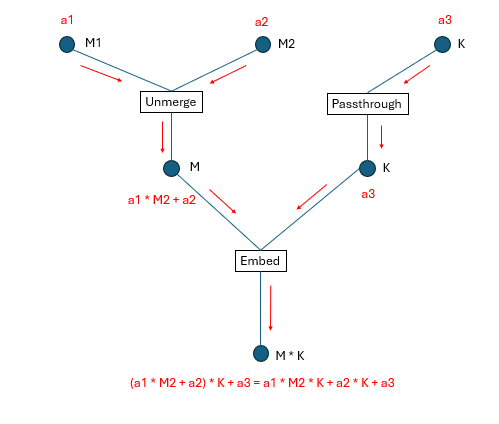
);TensorDescriptor를 생성하고 Unmerge 변환을 적용하여 2D 텐서를 3D 레이아웃으로 변경하는 예시

static_for<0, 4, 1>{}([&](auto i){
a(Number<i>{}) = buf.Get<d4_t>(
tensor_desc.CalculateOffset(Tuple{x + i, y}), true);
});
// In-register transpose
static_for<1, 4, 1>{}([&](auto i){
static_for<0, i, 1>{}([&](auto j){
auto tmp = b(Number<i * 4 + j>{});
b(Number<i * 4 + j>{}) = b(Number<j * 4 + i>{});
b(Number<j * 4 + i>{}) = tmp;
});
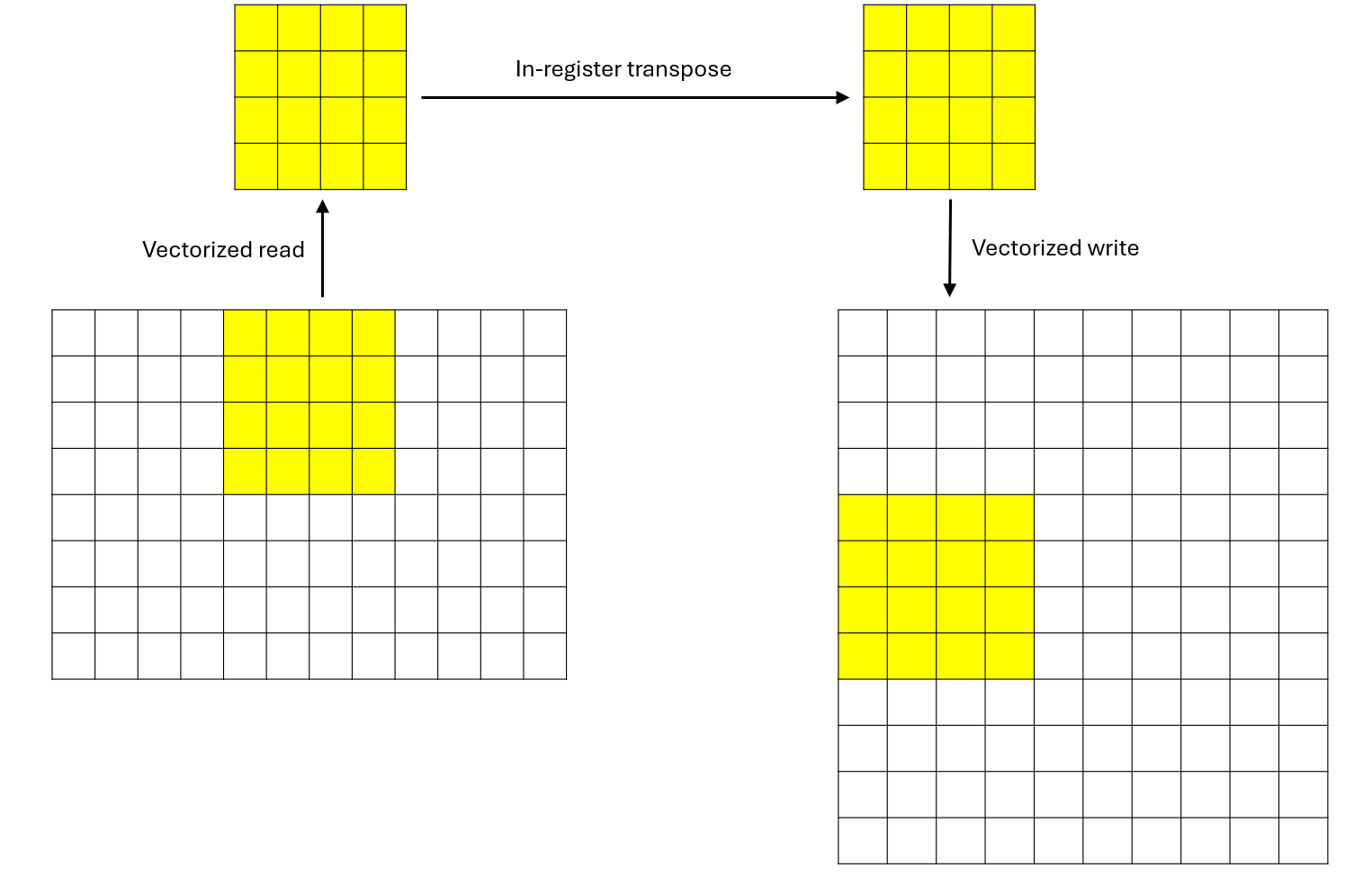
});벡터화된 읽기를 수행한 후 레지스터 내에서 4x4 행렬 전치를 수행하는 핵심 로직
실무 Takeaway
- TensorDescriptor를 활용하면 복잡한 다차원 인덱스 계산 로직을 추상화하여 커널 코드의 가독성과 유지보수성을 획기적으로 개선할 수 있다.
- GPU 커널 최적화 시 static_for와 같은 컴파일 타임 루프 언롤링을 적용하여 런타임 제어 오버헤드를 최소화하고 연산 처리량을 극대화해야 한다.
- 성능 병목을 해결하기 위해 공유 메모리 대신 레지스터 수준에서 데이터를 처리하고 벡터화된 메모리 접근 패턴을 우선적으로 고려하는 설계가 유효하다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.