이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
대형 언어 모델의 효율성을 높이는 양자화 기술은 모델 가중치를 낮은 정밀도로 변환하는 과정에서 품질 저하를 최소화하는 것이 핵심이다. Sam Rose의 에세이는 부동 소수점의 이진수 표현부터 시작하여 양자화 과정에서 발생하는 '아웃라이어' 가중치의 결정적인 역할을 시각적으로 구현했다. 특히 '슈퍼 웨이트'라고 불리는 극소수의 아웃라이어를 보존하는 것이 모델의 출력 품질 유지에 필수적이다. Qwen 3.5 9B 모델을 대상으로 한 벤치마크 결과, 16비트에서 8비트로의 양자화는 성능 저하가 거의 없으며 4비트에서도 약 90%의 성능을 유지함이 확인됐다.
배경
컴퓨터 구조 기초, 부동 소수점 표현 방식, LLM 추론 기본 개념
대상 독자
LLM 최적화 및 배포를 담당하는 엔지니어
의미 / 영향
양자화가 단순히 용량을 줄이는 작업이 아니라 핵심 가중치를 선별적으로 보호하는 정교한 과정임을 시사한다. 특히 8비트 양자화의 높은 효율성은 중소규모 모델의 실전 배포 가능성을 더욱 높여준다.
섹션별 상세
양자화는 고정밀 부동 소수점 데이터를 저정밀 비트 형식으로 변환하여 모델 크기와 연산 비용을 줄이는 기술이다. Sam Rose는 float32의 부호, 지수, 가수 구조를 시각화하여 이진수 기반의 수치 표현 방식을 직관적으로 구현했다. 이를 통해 양자화가 데이터 분포를 재구성하는 정밀한 과정임이 드러난다.
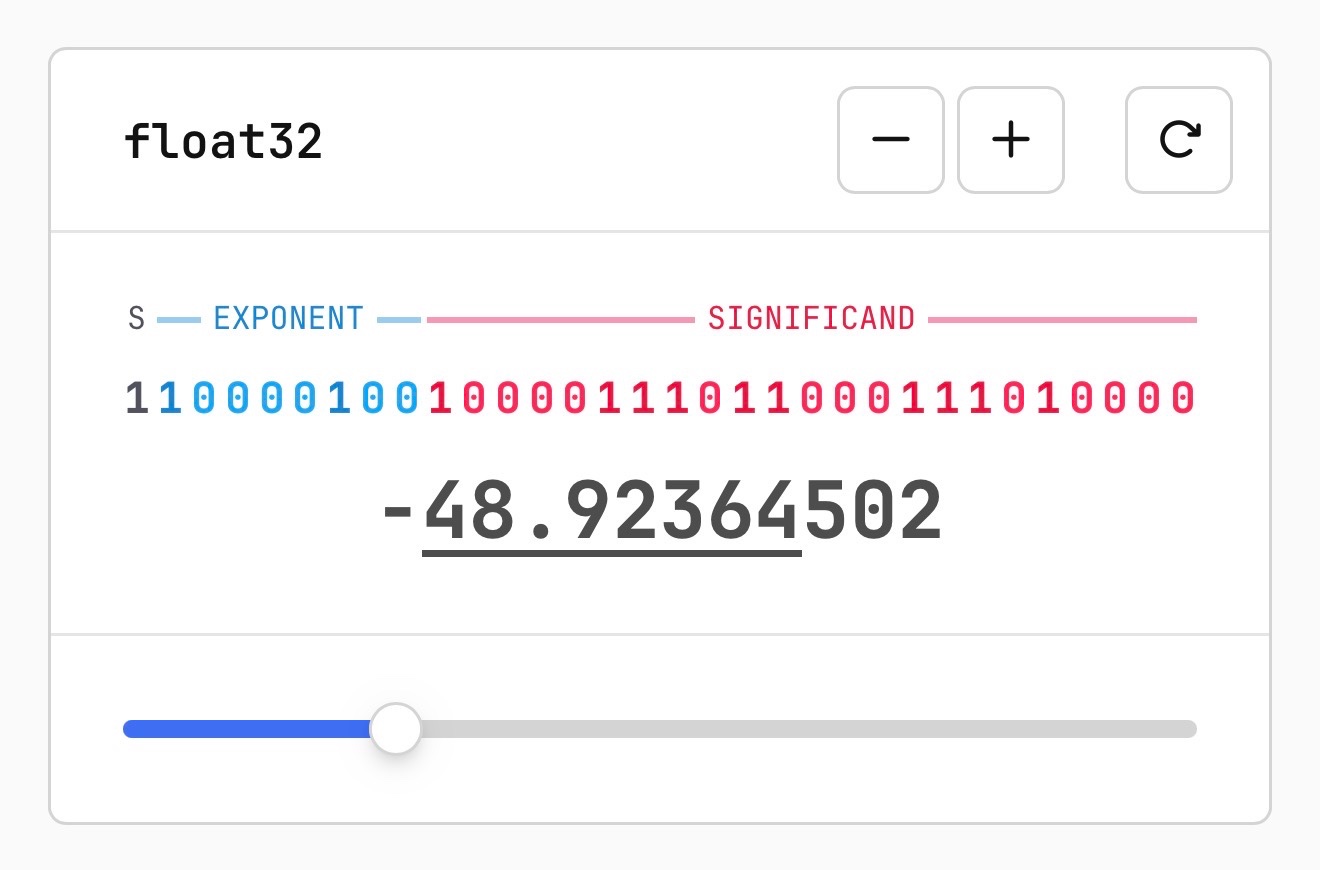
양자화 과정에서 일반적인 분포를 벗어나는 '아웃라이어' 가중치는 모델의 추론 능력에 지대한 영향을 미친다. Apple이 '슈퍼 웨이트'라고 명명한 이 소수의 가중치들이 제거될 경우 모델은 의미 없는 문장을 출력하게 된다. 최신 양자화 기법들은 이 아웃라이어들을 별도의 테이블에 저장하거나 양자화 대상에서 제외하여 모델의 지능을 보존한다.
양자화 수준에 따른 모델의 정확도 변화는 Perplexity와 KL Divergence 지표를 통해 정량적으로 측정된다. llama.cpp와 GPQA 벤치마크를 활용해 Qwen 3.5 9B 모델을 테스트한 결과, 16비트에서 8비트로 전환 시 성능 손실은 거의 발생하지 않았다. 4비트 양자화는 다소 성능 저하가 관찰되지만 원본 대비 약 90% 수준의 효율성을 보여 실용성이 높다.
실무 Takeaway
- LLM 양자화 시 '슈퍼 웨이트'로 불리는 아웃라이어 가중치를 식별하고 별도로 관리해야 모델의 치명적인 성능 저하를 막을 수 있다.
- 실무 환경에서 Qwen 3.5 9B와 같은 모델을 8비트로 양자화할 경우 성능 손실 없이 메모리 사용량을 절반으로 줄이는 것이 가능하다.
- 양자화의 영향을 평가할 때는 단순 정확도뿐만 아니라 Perplexity와 KL Divergence를 함께 모니터링하여 언어 모델의 확률 분포 변화를 세밀하게 파악해야 한다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 03. 27.수집 2026. 03. 27.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.