이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
핵심 요약
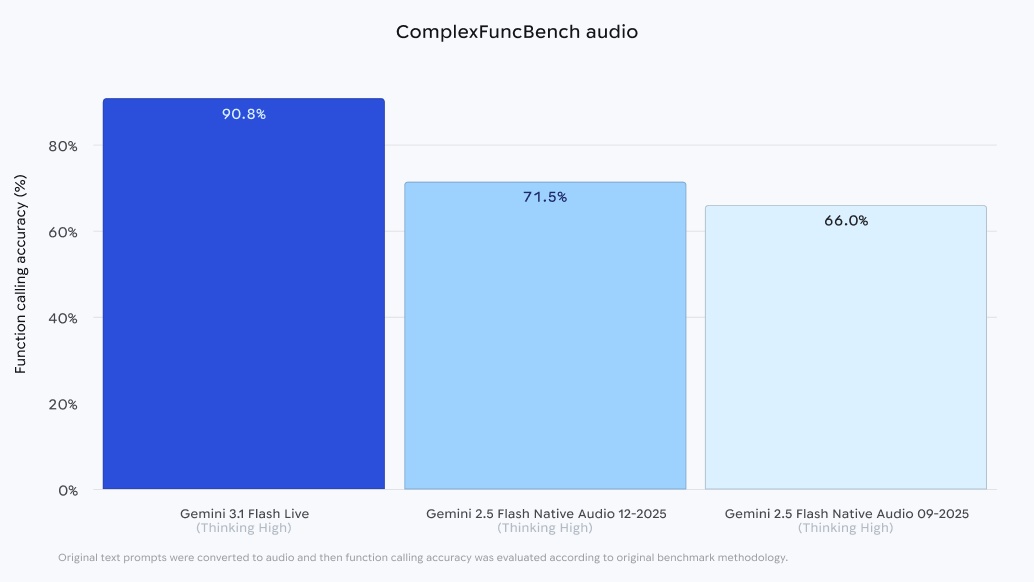
실시간 대화의 자연스러움과 신뢰성을 높이기 위해 설계된 구글의 최신 음성 모델 Gemini 3.1 Flash Live가 공개되었다. 이 모델은 입력된 음성의 톤, 피치, 속도 등 음향적 뉘앙스를 정교하게 파악하여 사용자 감정에 맞춘 응답을 생성하며, 복잡한 명령 수행 능력을 강화했다. 벤치마크 결과 ComplexFuncBench Audio에서 90.8%의 높은 점수를 기록하며 이전 모델 대비 성능 향상을 입증했다. 이를 통해 개발자는 시끄러운 환경에서도 작동하는 음성 에이전트를 구축할 수 있으며, 전 세계 200개 이상의 국가에서 다국어 서비스를 지원한다.
배경
Gemini API 사용 경험, 실시간 오디오 스트리밍 및 처리 개념, 함수 호출(Function Calling) 메커니즘에 대한 이해
대상 독자
실시간 음성 인터페이스 및 AI 에이전트를 구축하는 개발자와 기업 서비스 기획자
의미 / 영향
이 모델은 음성 AI의 지연 시간을 획기적으로 줄이고 추론 능력을 결합하여, 단순한 답변을 넘어 실제 업무를 수행하는 음성 에이전트 시대를 앞당길 것으로 보인다. 특히 다국어 지원과 워터마킹 기술은 글로벌 서비스 배포와 윤리적 운영에 중요한 기반이 된다.
섹션별 상세
기존 음성 모델들이 복잡한 다단계 명령이나 실시간 중단 상황에서 한계를 보였던 문제를 해결했다. Gemini 3.1 Flash Live는 ComplexFuncBench Audio 벤치마크에서 90.8%를 기록하며 다단계 함수 호출 능력을 입증했다. 이를 통해 개발자는 실제 대화 중 발생하는 망설임이나 끼어들기 상황에서도 맥락을 놓치지 않는 고성능 음성 에이전트를 개발할 수 있다.
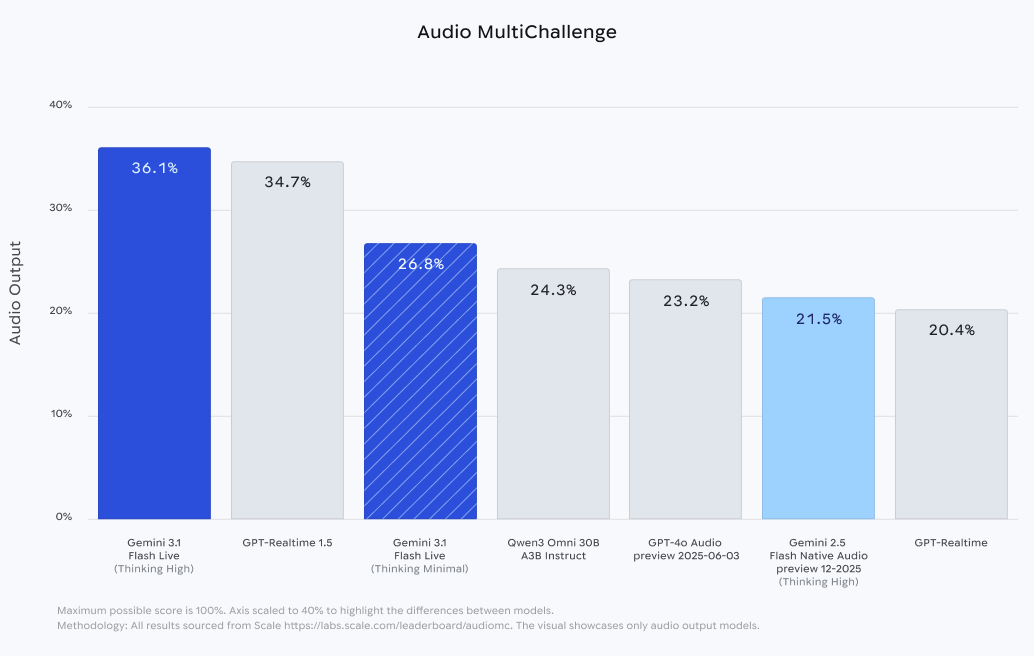
단순 텍스트 변환을 넘어 음성의 물리적 특성을 이해하지 못하면 대화가 부자연스러워지는 문제를 개선했다. 모델은 사용자의 목소리 톤, 피치, 속도를 분석하여 좌절이나 혼란 같은 감정 상태를 감지하고 이에 맞춰 응답을 동적으로 조정한다. Gemini Enterprise for Customer Experience에 적용되어 고객 상담 시 더욱 공감 능력 있는 상호작용을 가능하게 한다.
실시간 음성 AI의 오용 가능성과 언어 장벽 문제를 해결하기 위해 기술적 장치를 마련했다. 생성된 모든 오디오에는 SynthID 워터마크가 삽입되어 AI 생성 콘텐츠임을 식별할 수 있게 함으로써 미정보 확산을 방지한다. 또한 고유의 다국어 능력을 바탕으로 Search Live 서비스를 200개 이상의 국가로 확대하여 전 세계 사용자가 자국어로 실시간 대화를 나눌 수 있도록 지원한다.
실무 Takeaway
- Gemini 3.1 Flash Live의 향상된 함수 호출 능력을 활용하면 복잡한 워크플로우를 음성만으로 제어하는 에이전트를 구축할 수 있다.
- SynthID 워터마킹 기술이 기본 적용되어 있어 기업 사용자는 AI 생성 음성 콘텐츠의 투명성과 안전성을 확보하며 서비스를 운영할 수 있다.
- 낮은 지연 시간과 긴 대화 맥락 유지 기능을 통해 브레인스토밍이나 실시간 문제 해결과 같은 장기적인 대화 시나리오에 적합하다.
언급된 리소스
API DocsGoogle AI Studio
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 03. 27.수집 2026. 03. 27.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.