핵심 요약
캐나다 스타트업 Taalas가 Llama 3.1 8B 모델을 ASIC 칩에 직접 하드와이어링하여 초당 17,000 토큰의 추론 속도를 구현했다. 기존 GPU가 VRAM과 연산 코어 사이에서 데이터를 반복적으로 주고받으며 발생하는 '메모리 벽' 문제를 해결하기 위해, 모델의 각 레이어를 물리적 트랜지스터로 칩에 식각했다. 이 방식은 GPU 기반 시스템보다 비용과 전력 소모를 각각 10배 절감하면서도 속도는 10배 향상시키는 성과를 거두었다. 비록 모델 변경이 불가능한 고정 기능 칩이지만, 특정 모델의 대규모 추론 서비스에 혁신적인 대안을 제시한다.
배경
LLM 추론 구조(Layers, Weights), GPU 아키텍처 기초, ASIC 및 메모리 병목 현상 개념
대상 독자
LLM 추론 인프라 엔지니어, AI 하드웨어 설계자, 비용 효율적인 대규모 모델 서빙을 고민하는 개발자
의미 / 영향
범용 GPU 중심의 AI 인프라 시장에서 특정 모델에 최적화된 전용 ASIC의 경제성이 부각될 것이다. 이는 대규모 서비스 운영사들이 고정된 모델을 저비용/고효율로 서빙하기 위해 전용 칩을 도입하는 트렌드를 가속화할 수 있다.
섹션별 상세
이미지 분석
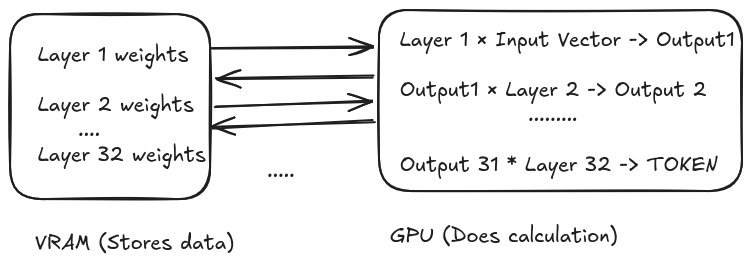
GPU가 매 레이어 연산마다 VRAM에서 가중치를 읽어오고 결과를 다시 쓰는 반복적인 과정을 시각화하여 '메모리 벽' 문제를 설명한다. 32개 레이어를 거치며 발생하는 데이터 전송의 비효율성을 강조한다.
GPU와 VRAM 사이의 데이터 이동 과정을 보여주는 다이어그램.

소프트웨어 형태의 모델이 물리적인 칩 구조로 '인쇄'되는 개념을 단계별로 보여준다. 추상적인 신경망 구조가 실제 실리콘 칩의 물리적 레이아웃으로 고정되는 Taalas의 핵심 접근 방식을 시각적으로 전달한다.
PyTorch 모델이 Taalas 파운드리를 거쳐 하드웨어 모델(칩)로 변환되는 과정을 보여주는 인포그래픽.
실무 Takeaway
- 특정 LLM 모델을 ASIC에 하드와이어링하면 GPU 대비 전력 효율과 추론 속도를 10배 이상 개선할 수 있다.
- 메모리 병목 현상을 해결하기 위해 가중치를 연산 유닛 근처가 아닌 연산 유닛 그 자체(트랜지스터)로 구현하는 접근 방식이 유효함을 입증했다.
- 모델 수정이 불가능한 ASIC의 단점을 베이스 칩과 상단 마스크 커스터마이징 전략으로 보완하여 제작 기간을 2개월로 단축했다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료