핵심 요약
AI 에이전트는 실행 시점에 추론 결과가 결정되는 비결정적 특성을 지니므로 기존의 코드 중심 디버깅 방식으로는 한계가 있다. 에이전트 엔지니어링의 핵심은 실행 과정에서 발생하는 추론 궤적(Trace)을 캡처하고 이를 기반으로 성능을 평가하는 것이다. 실행 단위(Run), 전체 실행(Trace), 대화 세션(Thread)이라는 세 가지 기본 요소를 통해 에이전트의 의사결정 과정을 가시화하고 검증할 수 있다. 관측 데이터는 단순한 모니터링을 넘어 오프라인 테스트 데이터셋 구축과 실시간 성능 개선의 토대가 된다.
배경
LLM 애플리케이션 개발 기초, AI 에이전트 및 도구 사용(Tool Use) 개념, 소프트웨어 관측성(Observability) 및 테스팅 기본 지식
대상 독자
프로덕션 환경에서 LLM 에이전트를 구축하고 성능을 최적화하려는 AI 엔지니어 및 개발자
의미 / 영향
에이전트 개발 패러다임이 코드 작성에서 추론 관리 및 평가로 이동하고 있음을 시사한다. 이는 LLM 앱의 신뢰성을 확보하기 위해 관측성 도구와 평가 프레임워크의 통합이 필수적임을 의미한다.
섹션별 상세
이미지 분석
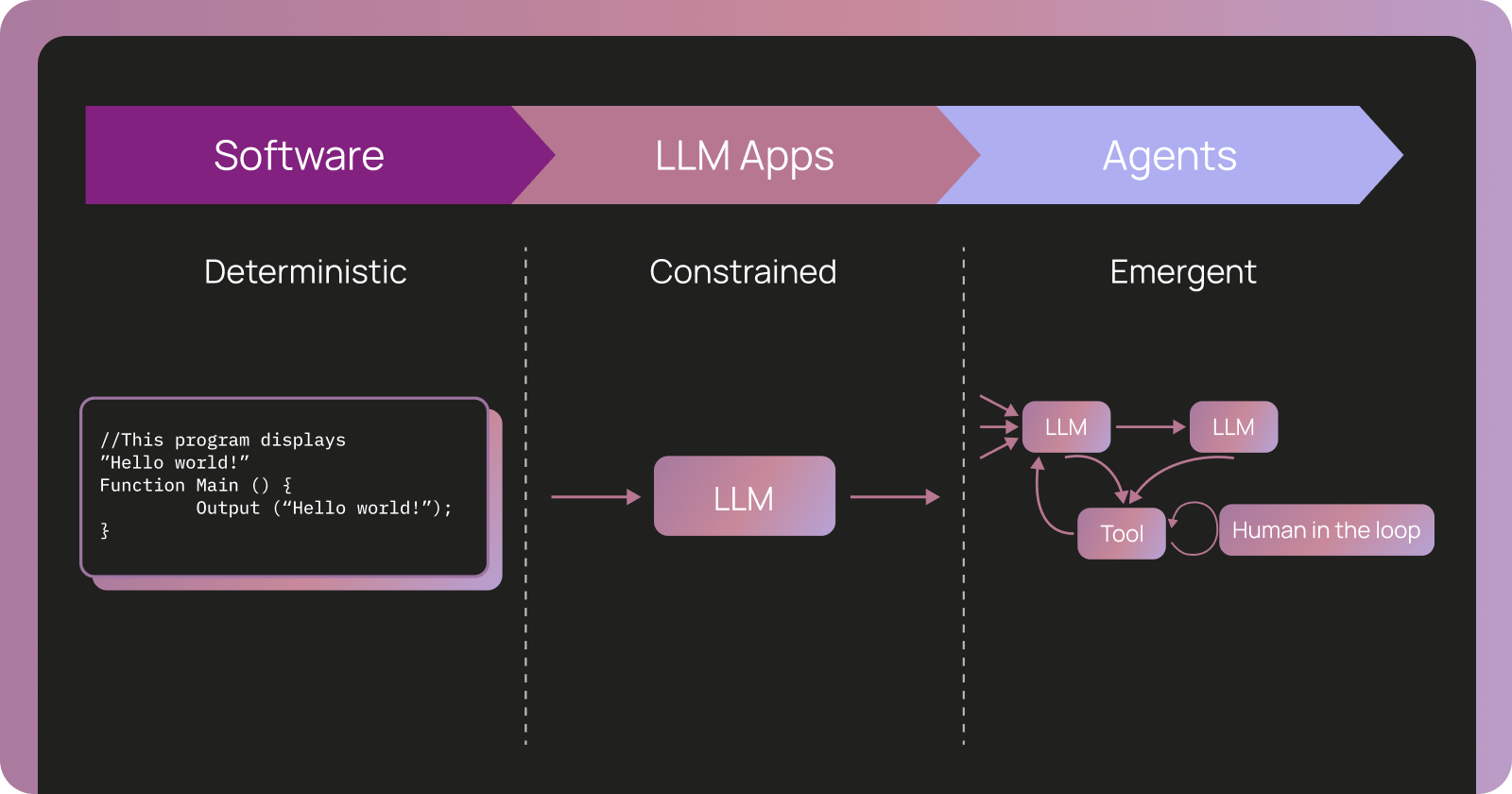
소프트웨어는 결정론적이고 코드가 진실의 원천인 반면, 에이전트는 비결정론적이며 실행 추적(Trace)이 진실의 원천이 됨을 시각화한다. 에이전트로 갈수록 불확실성이 높아짐을 보여준다.
전통적 소프트웨어, LLM 앱, 에이전트의 특성 비교 다이어그램이다.
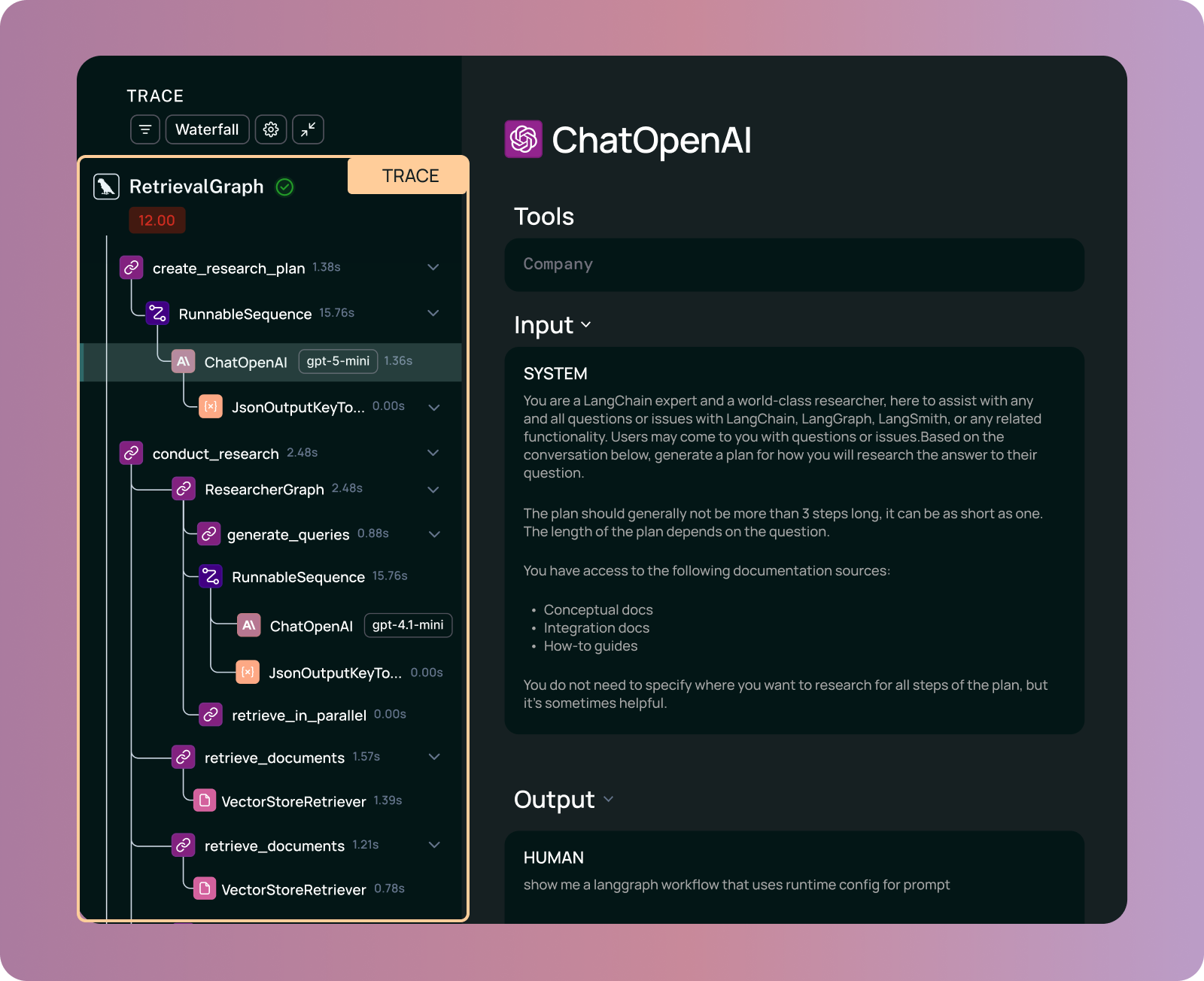
에이전트가 작업을 수행하는 동안 거친 중첩된 단계들과 각 단계의 실행 시간, 입출력 데이터를 상세히 보여준다. 복잡한 에이전트의 추론 과정을 계층적으로 파악할 수 있다.
LangSmith의 실행 추적(Trace) 인터페이스 스크린샷이다.
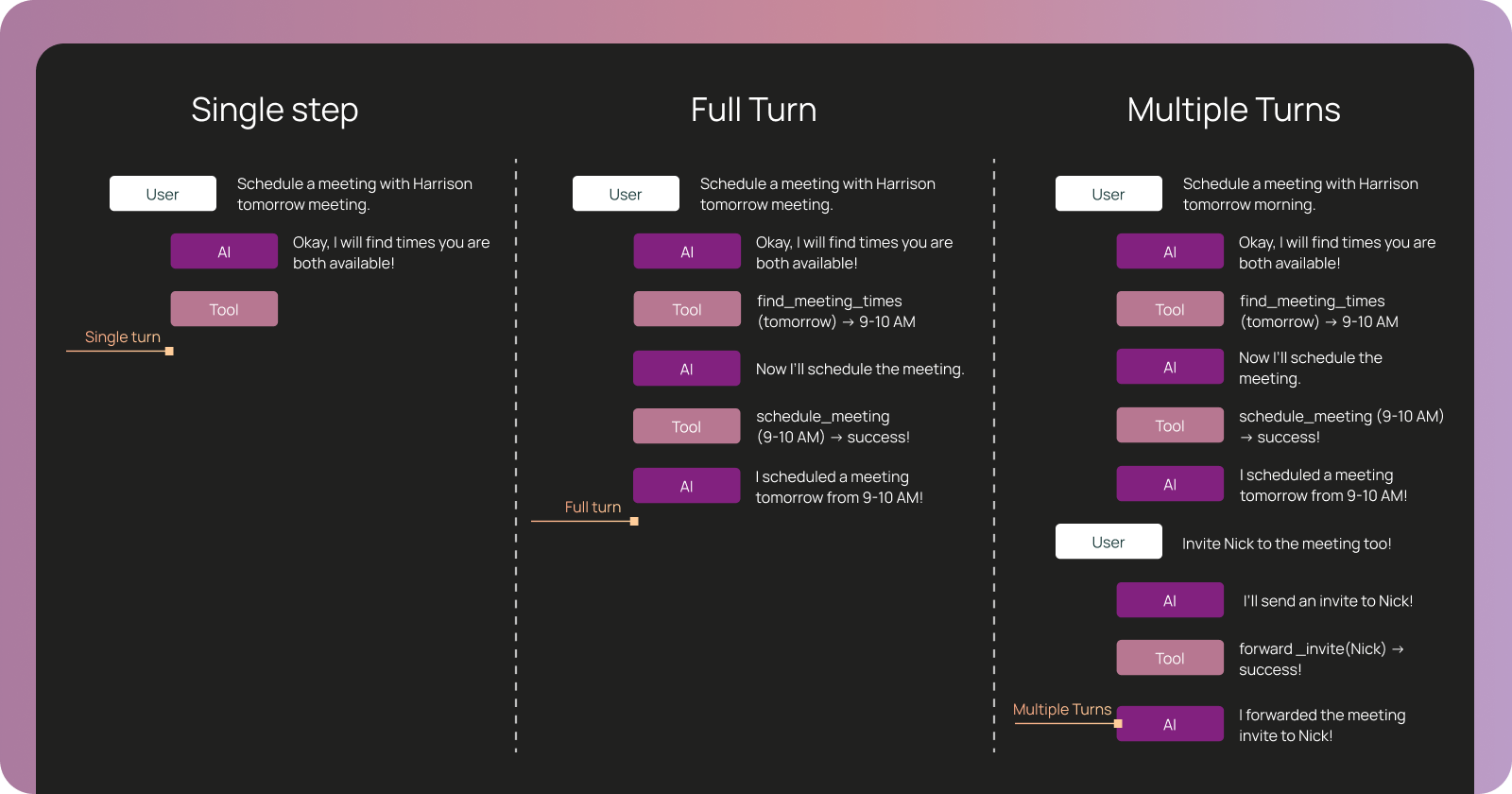
평가 단위에 따라 검증 범위가 어떻게 확장되는지 설명한다. 단일 단계는 도구 선택을, 전체 턴은 작업 완수를, 멀티 턴은 대화 맥락 유지를 중점적으로 평가한다.
단일 단계, 전체 턴, 멀티 턴 평가의 차이를 보여주는 다이어그램이다.

단일 단계(Run)는 지표 정의가 쉽지만 아키텍처 변경에 취약하고, 멀티 턴(Thread)은 가장 현실적이지만 입력과 지표 정의가 모두 어렵다는 점을 명시한다.
평가 단위별 장단점 비교표이다.

오프라인 평가는 개발 중 회귀 방지에, 온라인 평가는 프로덕션 이슈 감지에, 애드혹 평가는 탐색적 데이터 분석에 적합함을 나타낸다.
오프라인, 온라인, 애드혹 평가의 시점과 용도를 정리한 표이다.
실무 Takeaway
- 에이전트 오류 발생 시 코드 수정에 앞서 추론 궤적에서 에이전트가 잘못된 판단을 내린 특정 단계를 식별해야 한다.
- 프로덕션의 실제 실패 사례를 즉시 테스트 데이터셋으로 변환하여 동일한 유형의 추론 오류가 재발하지 않도록 관리한다.
- 에이전트의 복잡도에 따라 단일 단계 평가와 전체 턴 평가를 병행하여 의사결정의 정확도와 최종 결과의 품질을 모두 확보한다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료