핵심 요약
대형 언어 모델(LLM)의 성능을 높이기 위해 흔히 복잡한 프롬프트 엔지니어링이나 파인튜닝을 고려하지만, 단순히 프롬프트 전체를 복사하여 두 번 입력하는 '프롬프트 반복(Prompt Repetition)'만으로도 놀라운 성능 향상을 얻을 수 있다. 최근 연구에 따르면 이 기법은 특히 리스트 인덱싱이나 다지선다형 문제와 같은 비추론(Non-reasoning) 작업에서 효과적이며, Gemini 2.0 Flash Lite의 경우 특정 작업에서 정확도가 21%에서 97%로 상승하기도 했다. 이 방법은 출력 토큰을 늘리지 않아 비용 효율적이며, 지연 시간(Latency)에도 큰 영향을 주지 않아 실무 적용 가치가 매우 높다.
배경
LLM 프롬프트 엔지니어링 기초, 토큰 및 컨텍스트 윈도우 개념, LLM 추론 단계(Prefill vs Generation) 이해
대상 독자
LLM 애플리케이션의 정확도를 높이고자 하는 AI 엔지니어 및 프롬프트 엔지니어
의미 / 영향
복잡한 기법 없이도 입력 방식의 변화만으로 모델의 인코딩 능력을 극대화할 수 있음을 보여준다. 이는 특히 비용과 지연 시간에 민감한 프로덕션 환경에서 저비용 고효율의 최적화 수단이 될 것이다.
섹션별 상세
이미지 분석
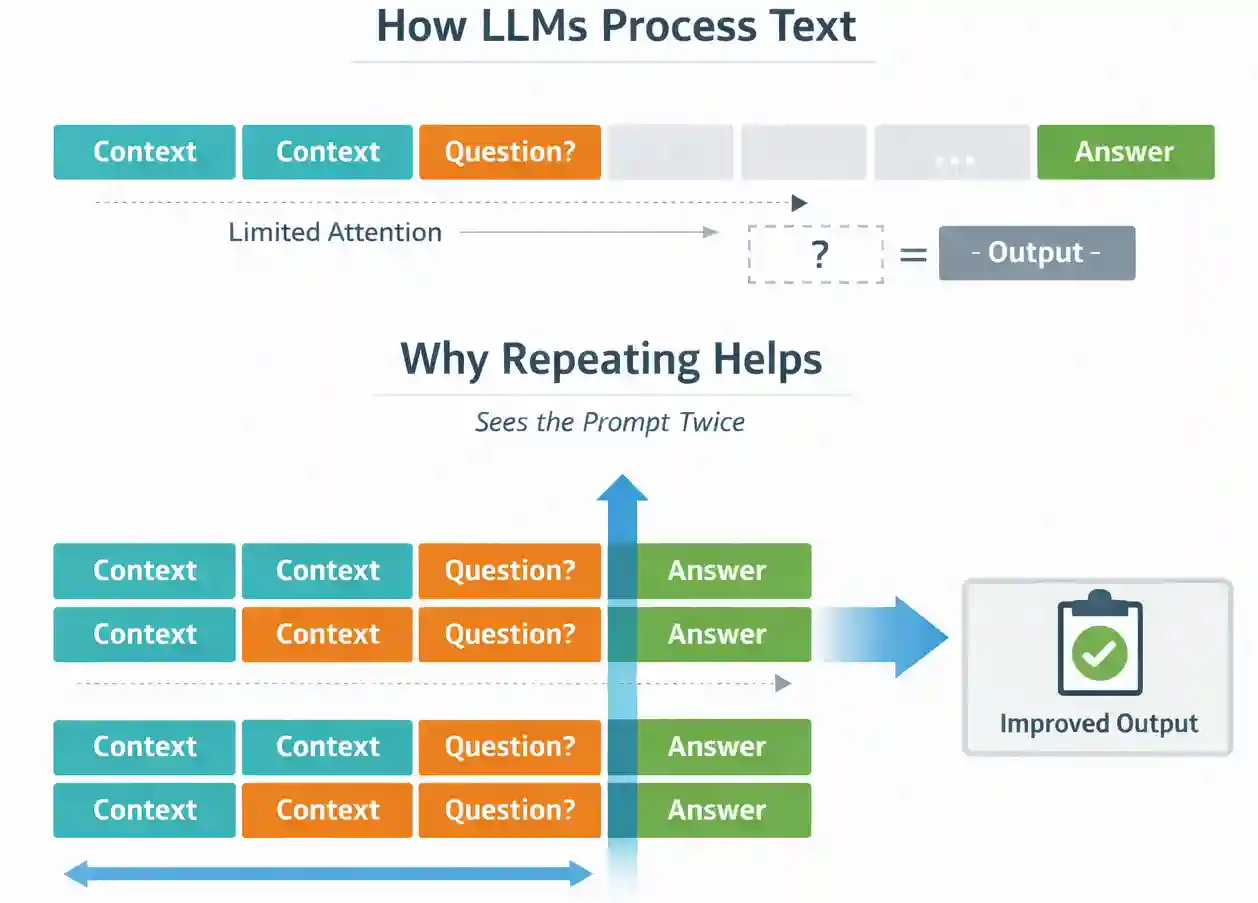
LLM이 제한된 주의력을 가지고 텍스트를 처리하는 방식과, 프롬프트를 두 번 반복했을 때 모델이 정보를 두 번 보게 되어 출력이 개선되는 메커니즘을 시각화했다.
LLM의 텍스트 처리 방식과 프롬프트 반복이 도움을 주는 이유를 설명하는 다이어그램이다.
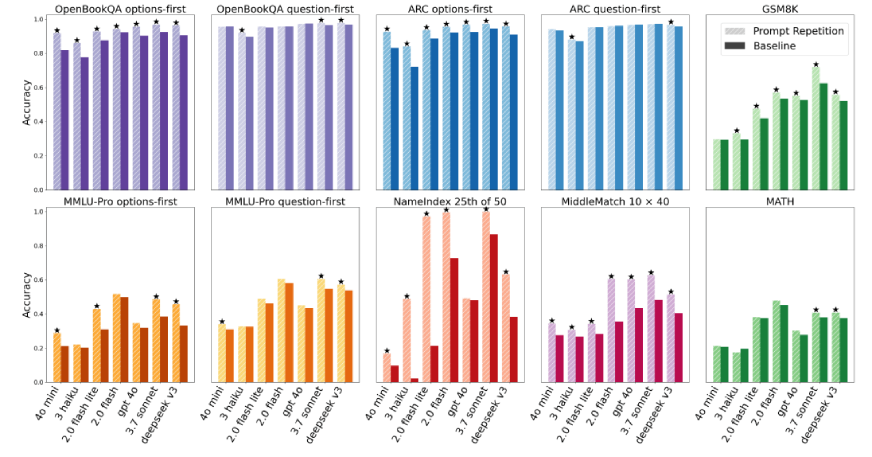
ARC, GSM8K, MMLU-Pro 등 여러 테스트에서 프롬프트 반복(연한 색)이 베이스라인(진한 색)보다 일관되게 높은 정확도를 기록함을 보여준다.
다양한 벤치마크에서 프롬프트 반복과 베이스라인의 정확도를 비교한 차트이다.

50개의 이름 리스트를 제공하고 특정 순서의 이름을 묻는 작업의 구조를 보여주며, 모델이 위치 정보를 어떻게 처리해야 하는지 설명한다.
실험에 사용된 NameIndex 작업의 예시 프롬프트이다.
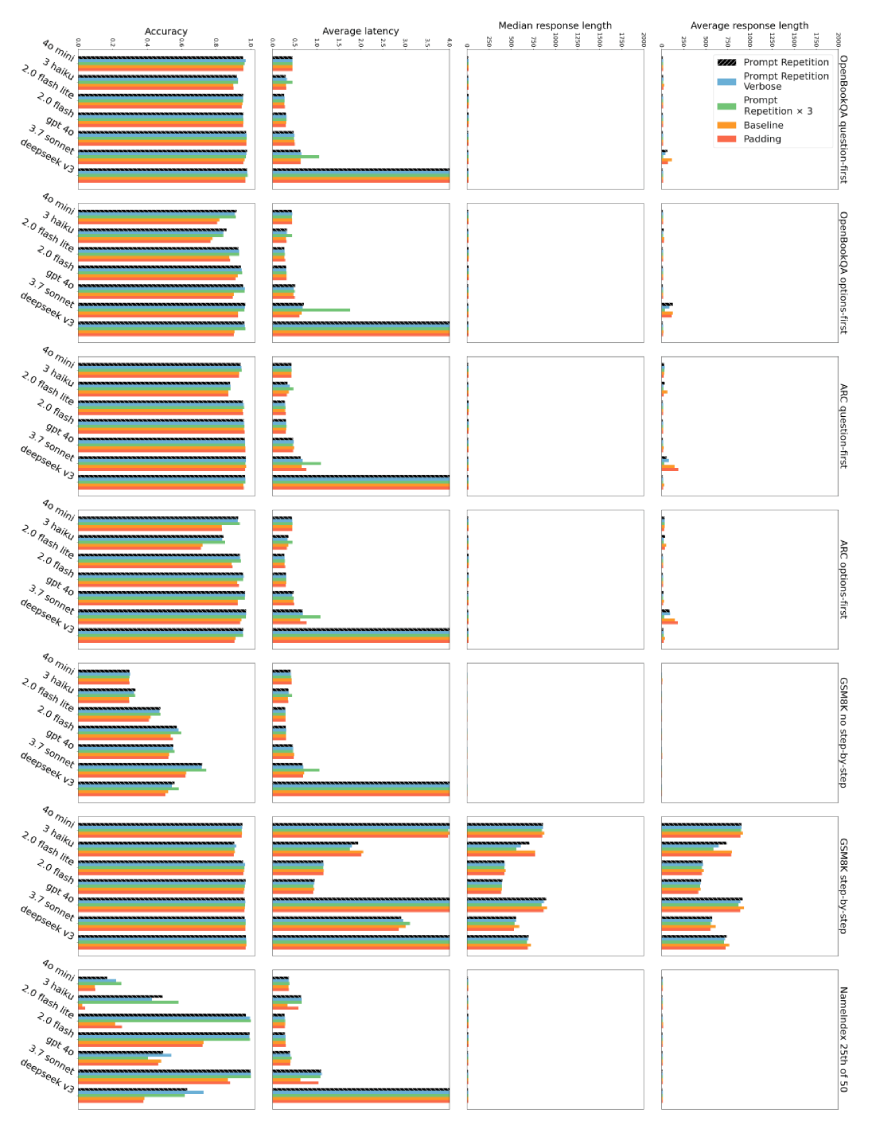
프롬프트 반복이 정확도는 높이면서도 응답 길이는 늘리지 않으며, 지연 시간 또한 베이스라인과 유사한 수준을 유지함을 수치로 증명한다.
프롬프트 반복 시의 정확도, 지연 시간, 응답 길이를 비교한 상세 데이터이다.
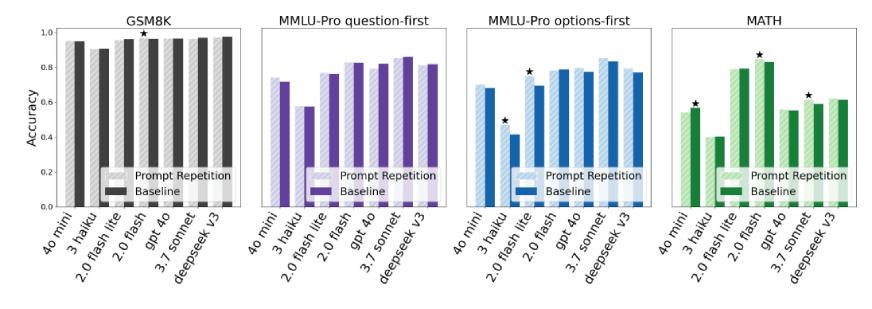
단계별 추론(Step-by-step)이 포함되지 않은 일반 작업에서 프롬프트 반복의 효과가 가장 극적으로 나타남을 비교 분석했다.
추론 프롬프트 유무에 따른 프롬프트 반복의 효과 차이를 보여주는 차트이다.
실무 Takeaway
- 비추론 작업(분류, 추출, 인덱싱)에서 성능이 낮을 경우 프롬프트를 단순히 두 번 반복(prompt + '\n' + prompt)하여 테스트하라.
- 출력 형식을 유지하면서 정확도만 높이고 싶을 때 Chain-of-Thought의 대안으로 활용 가능하다.
- 컨텍스트 윈도우 제한을 확인하고, Anthropic 모델 등 일부 모델에서의 Prefill 지연 시간 증가 여부를 모니터링하라.
AI 요약 · 북마크 · 개인 피드 설정 — 무료