핵심 요약
대규모 데이터 큐레이션이나 평가와 같은 LLM 배치 워크로드는 개별 요청의 지연 시간보다 전체 시스템의 처리량 최적화가 핵심이다. 기존 vLLM의 동기식 API나 단순한 Ray 통합 방식은 메모리 부족(OOM)이나 리소스 유휴 상태인 파이프라인 버블 문제를 겪는다. Ray Data LLM은 vLLM의 비동기 엔진과 Ray의 스트리밍 실행 모델을 결합하여 리소스 활용도를 극대화한다. 이를 통해 오류 발생 시에도 파이프라인이 중단되지 않는 프로덕션 수준의 안정성과 2배 이상의 처리량 향상을 달성했다.
배경
Ray 프레임워크 기본 지식, vLLM 추론 엔진에 대한 이해, Python 및 분산 데이터 처리 개념
대상 독자
프로덕션 환경에서 대규모 LLM 배치 추론 및 데이터 처리를 수행하는 AI 엔지니어
의미 / 영향
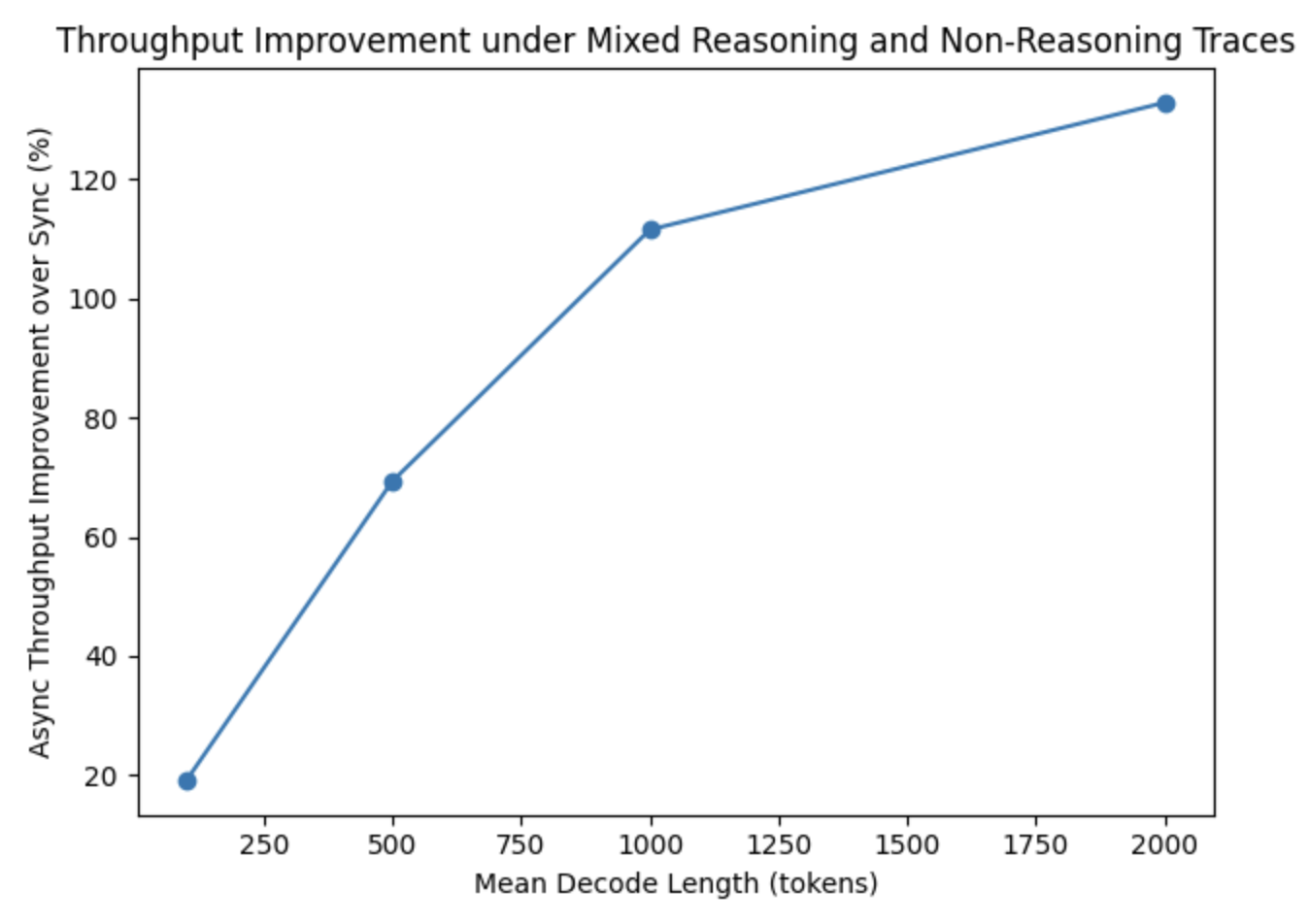
이 기술은 대규모 데이터 합성이나 모델 평가 비용을 획기적으로 낮출 수 있게 합니다. 특히 추론 길이가 길고 가변적인 최신 추론 모델(Reasoning Models) 환경에서 리소스 활용도를 극대화하여 인프라 효율성을 크게 개선할 것으로 기대됩니다.
섹션별 상세
from vllm import LLM
llm = LLM(model="facebook/opt-125m")
prompts = [
"What is machine learning?",
"Explain neural networks.",
"How does backpropagation work?",
]
sampling_params = SamplingParams(
temperature=0.7,
max_tokens=100,
)
outputs = llm.generate(prompts, sampling_params)vLLM의 Offline Inference API를 사용하는 나이브한 배치 추론 예시
class vLLMCallable:
def __init__(self, *args, **kwargs):
self.llm = LLM(*args, **kwargs)
def __call__(self, batch: pd.DataFrame) -> dict:
prompts = batch['prompt'].tolist()
sampling_params = SamplingParams(temperature=0.7, max_tokens=100)
outputs = self.llm.generate(prompts, sampling_params)
generated_texts = [out.outputs[0].text for out in outputs]
return {"generated_text": generated_texts}
ds = ds.map_batches(
vLLMCallable,
batch_size=32,
num_gpus=1,
fn_constructor_kwargs={"model": "facebook/opt-125m"},
)Ray Data와 vLLM을 결합한 동기식 분산 배치 추론 구현 방식
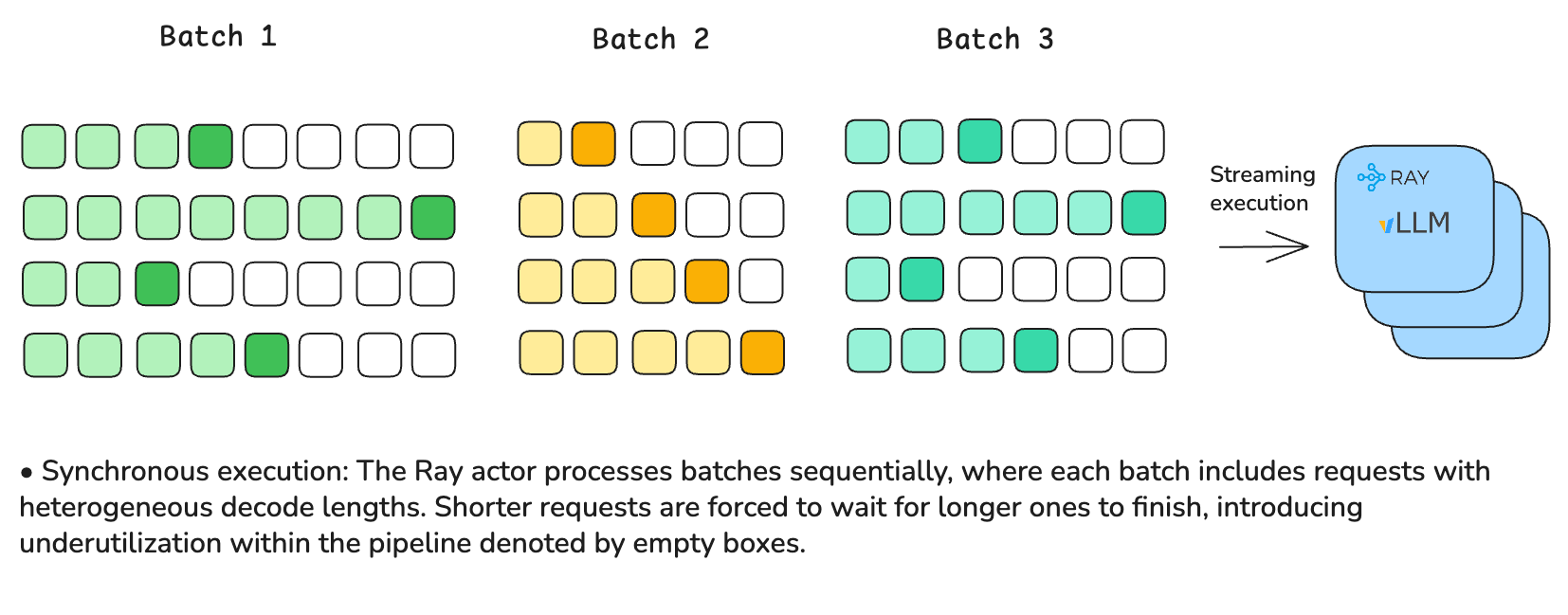
from ray.data.llm import vLLMEngineProcessorConfig, build_processor
config = vLLMEngineProcessorConfig(
model_source="facebook/opt-125m",
concurrency=16,
batch_size=32,
tokenize_stage=True,
detokenize_stage=True,
)
processor = build_processor(
config,
preprocess=lambda row: {
"messages": [{"role": "user", "content": row["prompt"]}],
"sampling_params": {"temperature": 0.7, "max_tokens": 100},
},
postprocess=lambda row: {"response": row["generated_text"]},
)
ds = processor(ds)Ray Data LLM 라이브러리를 사용한 비동기식 프로덕션 규모 배치 추론 설정



실무 Takeaway
- 대규모 배치 추론 시 Ray Data LLM을 사용하면 비동기 실행을 통해 GPU 유휴 시간을 최소화하고 처리량을 2배까지 높일 수 있다.
- 연속 배칭 기능이 없는 동기식 API 대신 비동기 엔진 기반의 라이브러리를 선택해야 가변적인 응답 길이 환경에서 리소스 효율을 극대화할 수 있다.
- 프로덕션 환경에서는 개별 요청 실패가 전체 배치 작업을 중단시키지 않도록 Ray Data LLM의 에러 기록 및 결함 허용 기능을 활용하는 것이 필수적이다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.