핵심 요약
vLLM 서버 설정과 관리는 복잡한 명령줄 지식과 컨테이너 오케스트레이션 숙련도를 요구하는 경우가 많다. vLLM Playground는 이러한 장벽을 제거하기 위해 컨테이너 기반의 자동 설치와 직관적인 UI를 제공하여 누구나 쉽게 vLLM을 활용할 수 있게 한다. 구조화된 출력(Structured Outputs), 도구 호출(Tool Calling), GuideLLM 벤치마킹 등 vLLM의 최신 기능을 시각적으로 실험하고 관리할 수 있는 환경을 지원한다. 로컬 macOS부터 엔터프라이즈급 Kubernetes 클러스터까지 동일한 사용자 경험을 제공하며 LLM 배포 효율성을 극대화한다.
배경
vLLM 기본 개념, 컨테이너(Docker/Podman) 기초 지식, Python 패키지 관리
대상 독자
vLLM을 사용하여 LLM 서비스를 개발하거나 배포하려는 엔지니어 및 연구원
의미 / 영향
vLLM Playground는 복잡한 인프라 설정 없이도 고성능 추론 엔진인 vLLM을 즉시 사용할 수 있게 하여 LLM 애플리케이션의 프로토타이핑 속도를 획기적으로 높인다. 특히 엔터프라이즈 환경의 Kubernetes 지원을 통해 로컬 개발과 실제 운영 환경 간의 기술적 간극을 메우는 데 기여한다.
섹션별 상세
이미지 분석
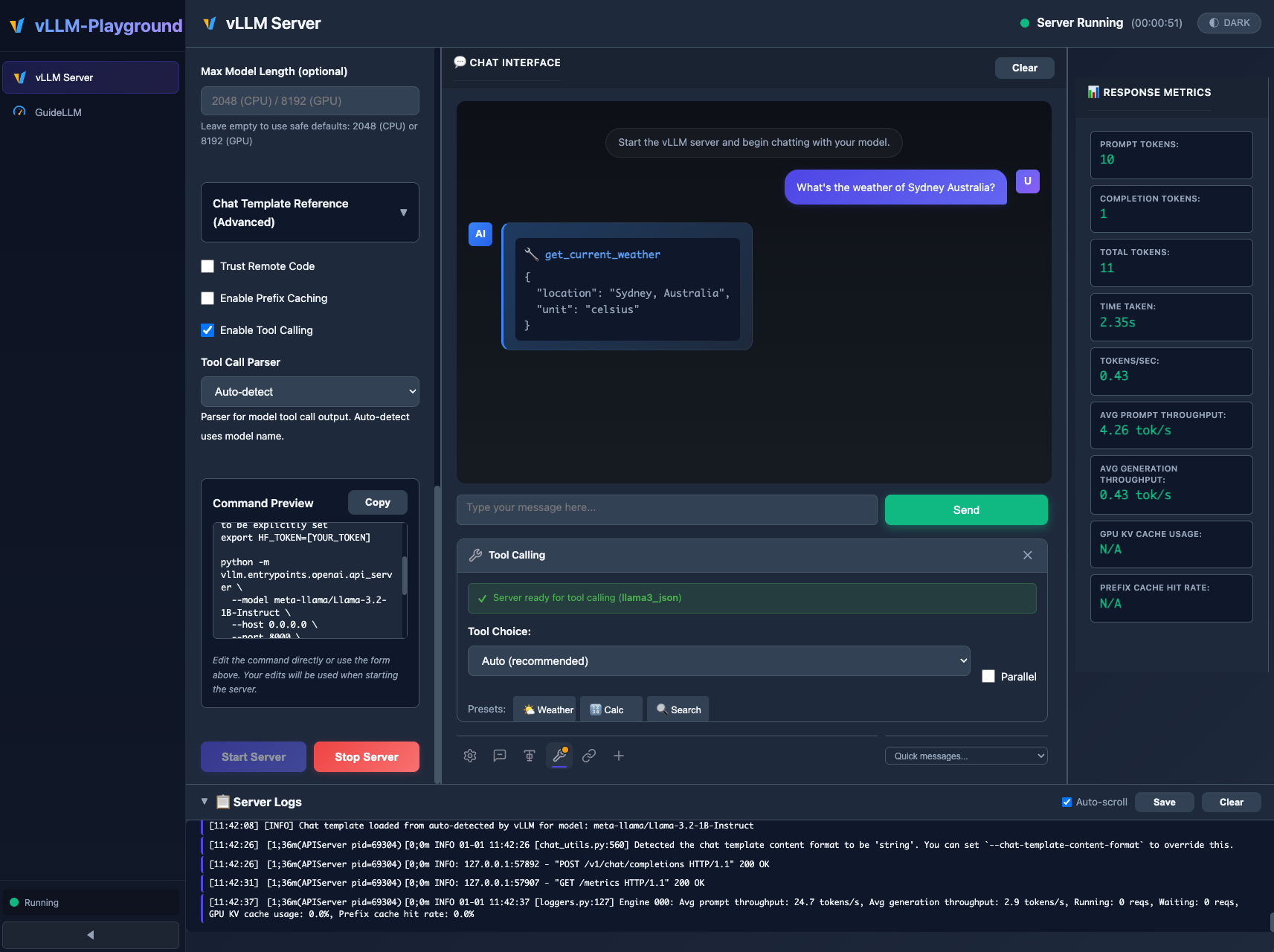
실시간 메트릭 확인, 도구 호출 설정, 명령줄 미리보기 등이 포함된 현대적인 다크 모드 UI 구성을 확인할 수 있다. 사용자가 UI에서 설정을 변경하면 하단의 서버 로그에 즉시 반영되는 구조를 보여준다.
vLLM Playground의 메인 채팅 인터페이스와 서버 설정 패널을 보여준다.
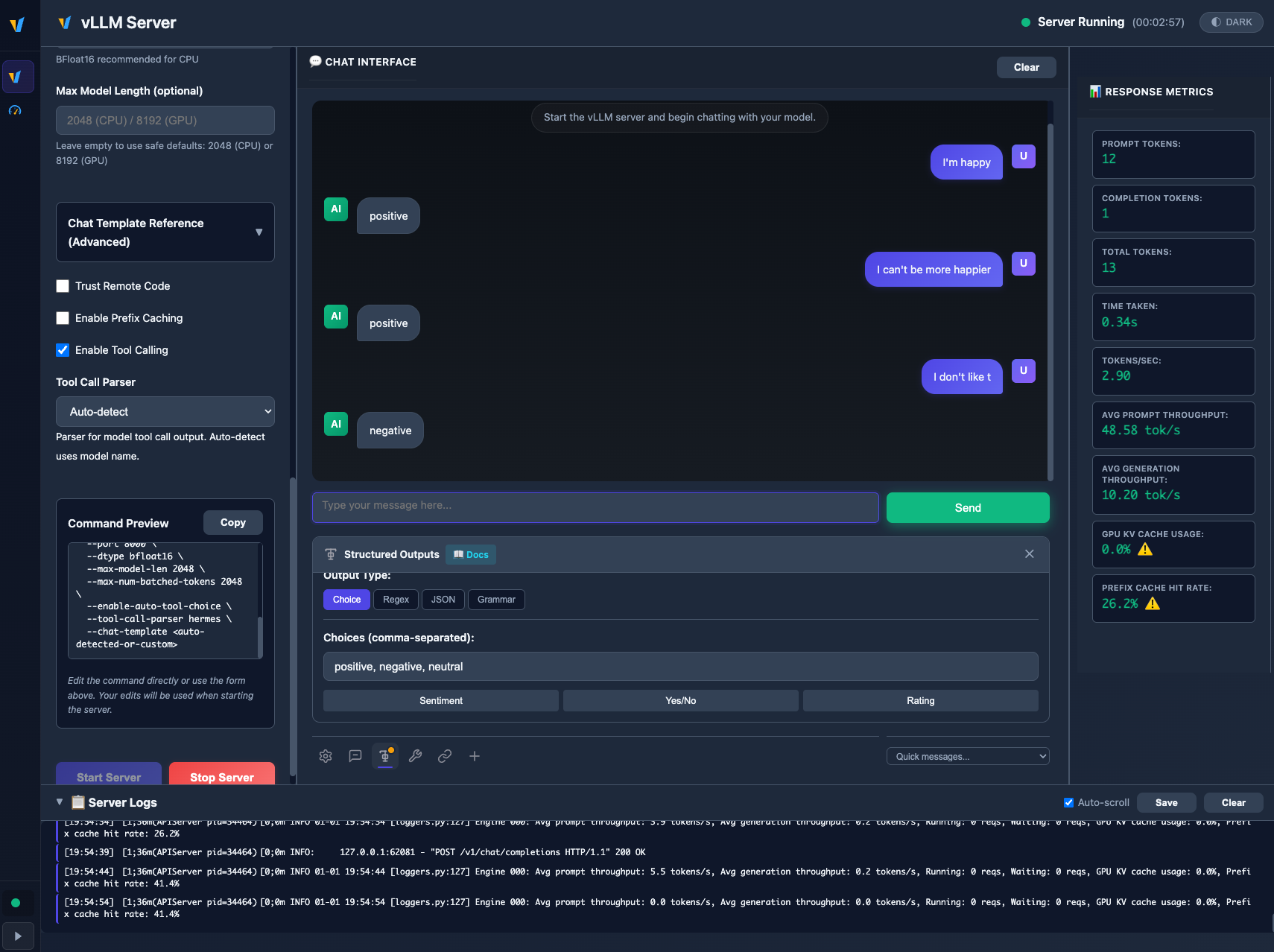
Choice, Regex, JSON, Grammar 모드를 선택하여 모델의 응답 형식을 강제하는 인터페이스를 제시한다. 감성 분석 예시에서 모델이 'positive'라는 정해진 레이블로만 응답하도록 제약하는 과정을 시각화한다.
구조화된 출력(Structured Outputs) 설정 화면과 실제 응답 예시를 보여준다.
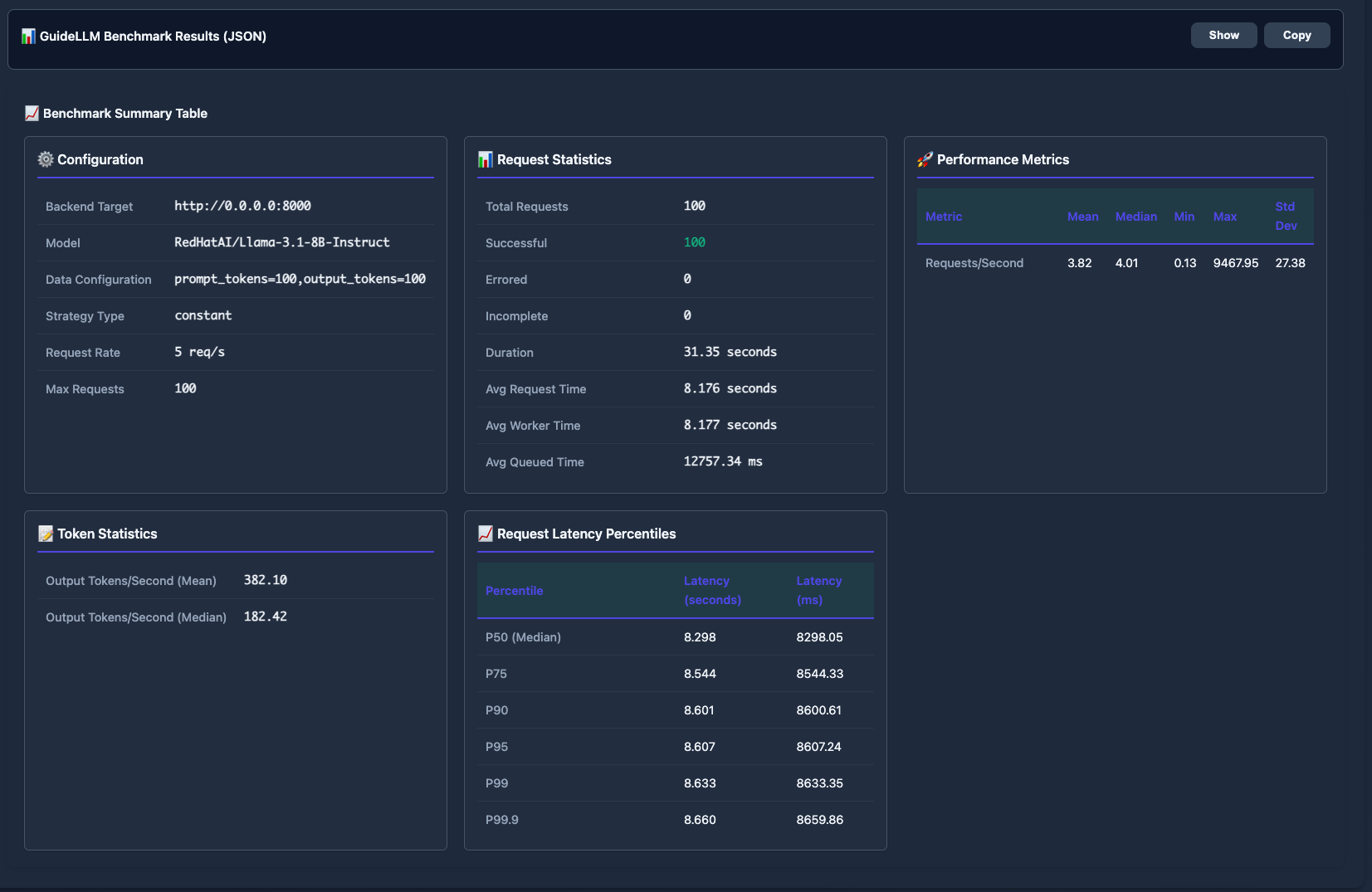
요청 통계, 성능 지표, 토큰 통계, 지연 시간 백분위수(P50~P99.9)를 상세히 나타낸다. 모델의 초당 요청 처리량(RPS)과 토큰 처리량을 정량적으로 분석하여 성능 최적화의 근거를 제공한다.
GuideLLM을 통한 벤치마크 결과 요약 테이블이다.
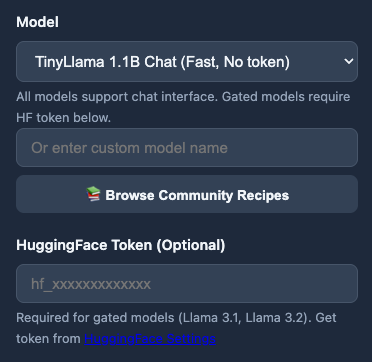
TinyLlama 등 사전 정의된 모델 목록을 선택하거나 커뮤니티 레시피를 브라우징하는 기능을 보여준다. 게이트된 모델(Llama 3.1 등) 사용을 위한 토큰 입력 필드를 포함하여 모델 접근성을 높이는 워크플로우를 설명한다.
모델 선택 및 Hugging Face 토큰 입력 인터페이스이다.
실무 Takeaway
- pip install vllm-playground 명령어로 로컬 및 클라우드 환경에서 즉시 vLLM 서버를 구축하고 관리할 수 있다.
- GuideLLM 통합 기능을 활용하여 모델의 토큰 처리량과 지연 시간을 정밀하게 측정하고 성능을 최적화한다.
- vLLM Recipes를 통해 최신 오픈소스 모델들에 최적화된 서버 설정을 수동 입력 없이 즉시 적용한다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료