핵심 요약
FAANG 기업들은 단순한 통계 정의 암기보다 실제 프로덕션 환경에서 발생할 수 있는 데이터 분석 오류를 식별하는 능력을 중시한다. 이 글은 심슨의 역설, 선택 편향, p-해킹 등 면접에서 후보자들을 당황하게 만드는 5가지 주요 통계적 함정을 상세히 설명한다. 각 함정의 발생 원인과 이를 해결하기 위한 기술적 접근법인 층화 분석 및 다중 검정 교정법을 코드 예시와 함께 제공한다. 결과적으로 데이터의 겉모습에 속지 않고 수집 과정과 하위 그룹의 특성을 비판적으로 질문하는 습관이 합격의 핵심임을 강조한다. 통계적 직관이 실제 데이터의 복잡성과 충돌할 때 논리적으로 대응하는 방법을 익히는 것이 중요하다.
배경
기초 통계학 (p-value, 상관관계), Python 데이터 분석 라이브러리 (Pandas, NumPy), A/B 테스트 기본 개념
대상 독자
데이터 사이언티스트 및 FAANG 기업 취업 준비생
의미 / 영향
이 가이드는 데이터 분석가가 실무에서 범하기 쉬운 통계적 오류를 체계적으로 정리하여 프로덕션 환경에서 잘못된 분석 결과가 배포되는 것을 방지합니다. 특히 FAANG과 같은 대규모 데이터 환경에서 비판적 사고가 기술적 숙련도만큼 중요하다는 점을 시사합니다.
섹션별 상세
import pandas as pd
data = pd.DataFrame({
'device': ['mobile', 'mobile', 'desktop', 'desktop'],
'variant': ['A', 'B', 'A', 'B'],
'converts': [40, 765, 90, 10],
'visitors': [100, 900, 900, 100],
})
data['rate'] = data['converts'] / data['visitors']
print('Per device:')
print(data[['device', 'variant', 'rate']].to_string(index=False))
print('
Aggregate (misleading):')
agg = data.groupby('variant')[['converts', 'visitors']].sum()
agg['rate'] = agg['converts'] / agg['visitors']
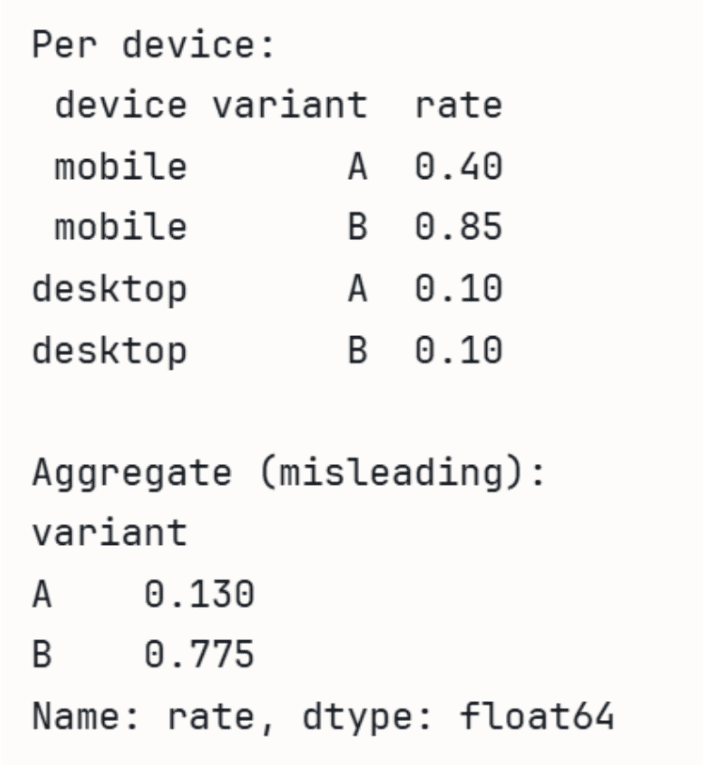
print(agg['rate'])Pandas를 사용하여 전체 집계 수치가 하위 그룹의 추세와 반대로 나타나는 심슨의 역설을 시뮬레이션하는 코드
import numpy as np
np.random.seed(42)
satisfaction = np.random.choice([0, 1], size=1000, p=[0.5, 0.5])
response_prob = np.where(satisfaction == 1, 0.8, 0.2)
responded = np.random.rand(1000) < response_prob
print(f"True satisfaction rate: {satisfaction.mean():.2%}")
print(f"Survey satisfaction rate: {satisfaction[responded].mean():.2%}")만족한 사용자가 설문에 더 많이 응답할 때 발생하는 선택 편향으로 인해 결과가 왜곡되는 과정을 보여주는 코드

from scipy import stats
n_tests, alpha = 20, 0.05
false_positives = 0
for _ in range(n_tests):
a = np.random.normal(0, 1, 1000)
b = np.random.normal(0, 1, 1000)
if stats.ttest_ind(a, b).pvalue < alpha:
false_positives += 1
print(f'Tests run: {n_tests}')
print(f'False positives (p<0.05): {false_positives}')효과가 없는 실험을 20번 반복했을 때 우연히 유의미한 결과가 발생하는 p-해킹의 위험성을 보여주는 코드

이미지 분석

올바른 질문하기, 누락된 정보 파악하기, 겉보기에 깨끗한 숫자에 의문 제기하기라는 세 가지 핵심 단계를 제시한다. 이는 면접관이 후보자의 사고 과정에서 중점적으로 평가하는 요소들을 요약하고 있다.
데이터 분석 시 비판적 사고를 위한 3단계 프로세스를 보여주는 다이어그램이다.

심슨의 역설, 선택 편향, 다중 비교, 데이터 수집 방법, 하위 그룹 분석이라는 핵심 주제를 시각적으로 정리했다. 각 함정이 데이터 해석에 어떤 영향을 미치는지 한눈에 파악할 수 있게 돕는다.
아티클에서 다루는 5가지 통계적 함정을 나열한 인포그래픽이다.
실무 Takeaway
- A/B 테스트 결과가 긍정적이더라도 심슨의 역설을 방지하기 위해 사용자 기기나 지역 등 주요 세그먼트별로 데이터를 쪼개어 추세가 일관적인지 반드시 확인해야 한다.
- 다수의 지표를 동시에 분석할 때는 위양성으로 인한 잘못된 의사결정을 피하기 위해 본페로니 교정 등의 통계적 보정 기법을 적용하여 유의수준을 엄격히 관리해야 한다.
- 데이터 간의 상관관계가 발견되었을 때 이를 즉각적인 인과관계로 해석하지 말고 층화 분석을 통해 숨겨진 교란 변수가 결과에 영향을 미치고 있는지 검증해야 한다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.