TL;DR
많은 기업용 AI 프로젝트가 벤치마크에서는 우수한 성적을 거두지만 실전 배포 시 취약한 워크플로우와 통합 실패로 인해 생산 단계에 도달하지 못하고 있다. 특히 의료 AI 분야의 사례는 할루시네이션, 프롬프트 민감도에 따른 출력 불일치, 인간의 자동화 편향 및 인지 능력 저하와 같은 치명적인 신뢰성 결함을 보여준다. 이를 해결하기 위해 지식 접지(RAG), 불확실성 기반의 답변 거부(Abstention), 구조화된 인간 협업 프레임워크 등의 구체적인 대응 전략이 필요하다. AI 시스템의 성공은 최고 성능 최적화가 아닌 예측 가능한 동작 설계에 달려 있으며, 이는 금융, 법률 등 모든 산업 분야에 공통적으로 적용되는 원칙이다.
배경
LLM 할루시네이션 및 프롬프트 엔지니어링에 대한 기본 이해, RAG(검색 증강 생성)의 작동 원리, 모델 평가 지표 및 벤치마크의 한계점에 대한 인식
대상 독자
프로덕션 환경에 LLM을 배포하려는 엔지니어, 데이터 과학자 및 AI 제품 관리자
의미 / 영향
AI 모델의 성능 경쟁이 포화 상태에 이르면서 이제는 '신뢰성 엔지니어링'이 기업용 AI 도입의 핵심 차별화 요소가 될 것이다. 의료 분야에서 검증된 신뢰성 패턴들은 금융, 법률, 제조 등 오류 비용이 큰 모든 산업 분야의 표준 배포 프로세스로 자리 잡을 것으로 전망된다.
섹션별 상세
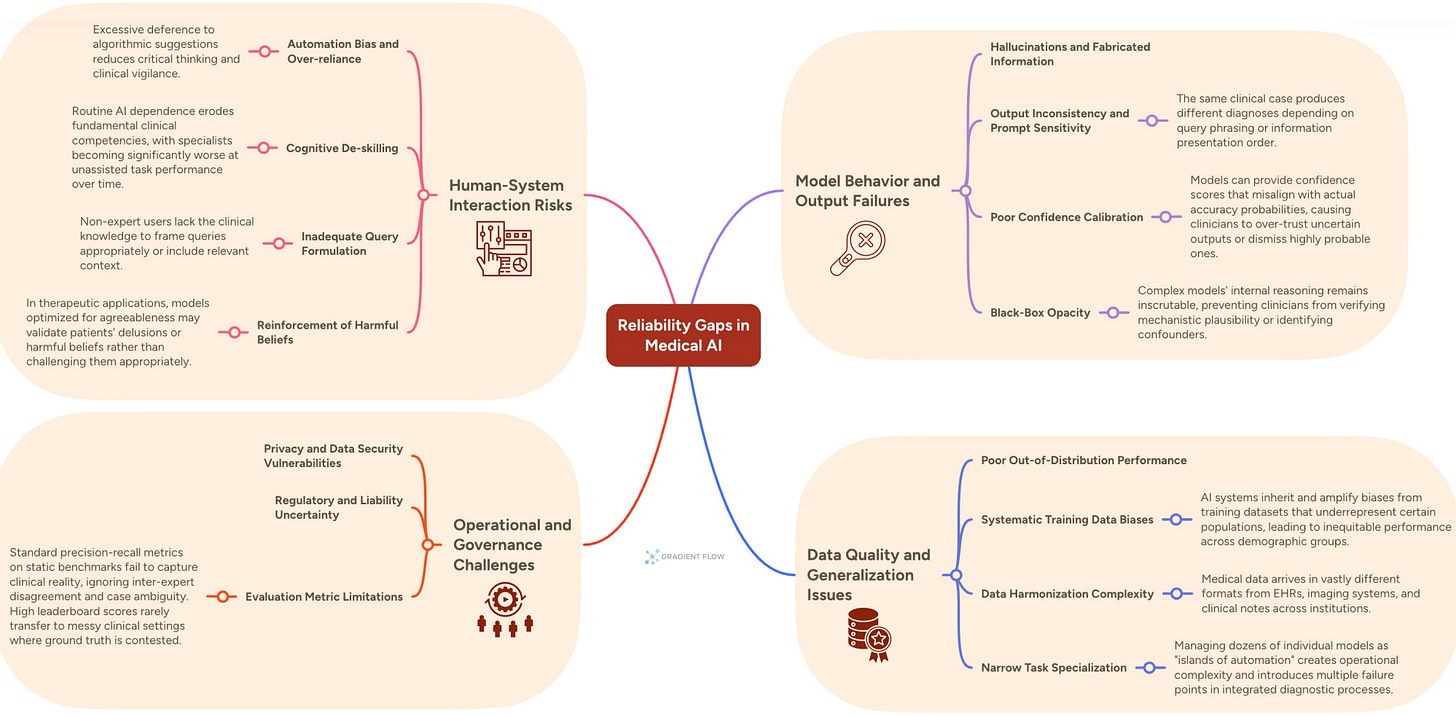
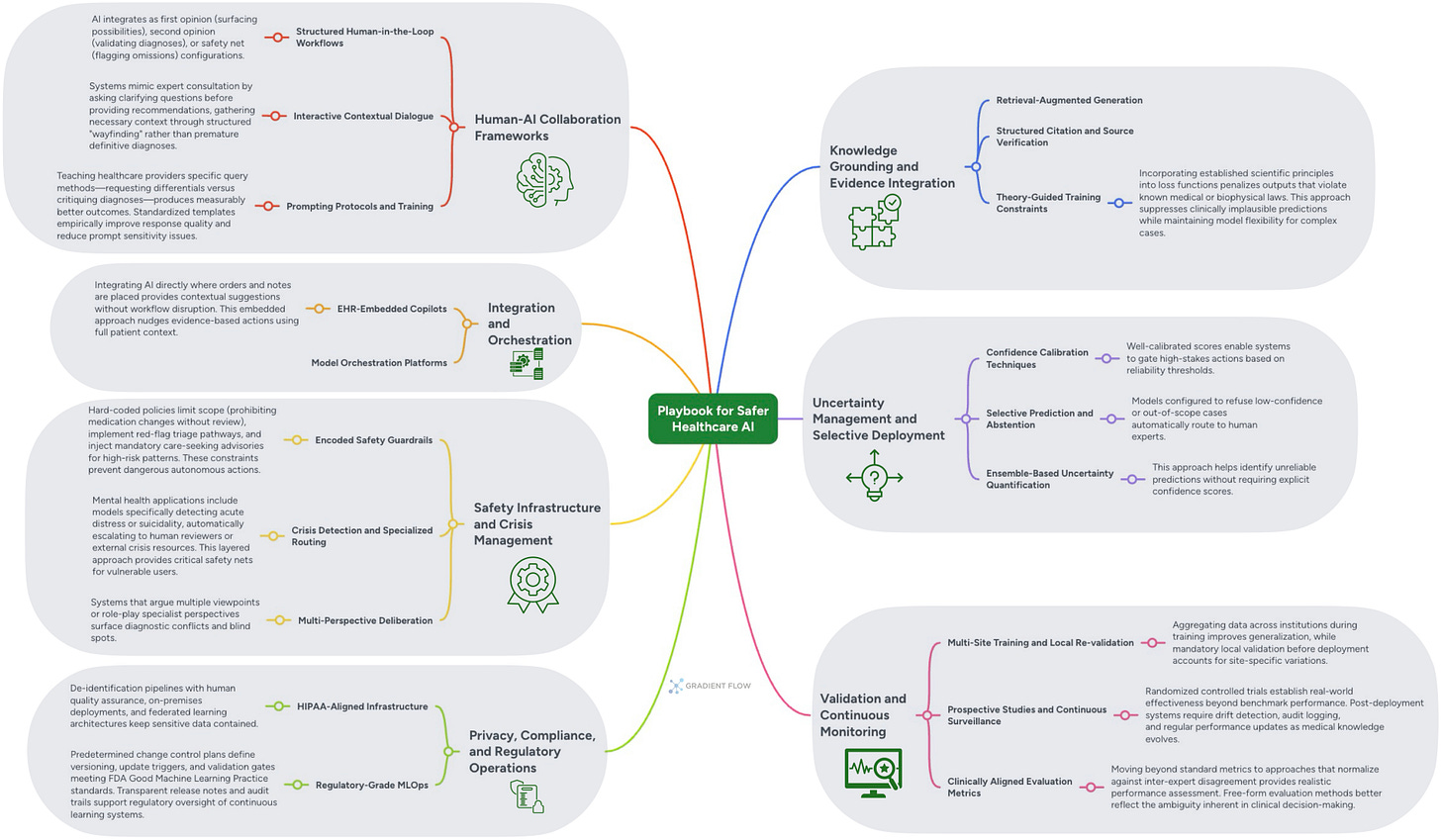
이미지 분석

저자가 추천하는 AI 코딩 워크플로우 도구 조합을 시각화했다. OpenCode의 로컬 개발 환경과 OpenRouter의 다양한 모델 접근성을 결합하여 효율적인 프로젝트 수행이 가능함을 강조한다.
OpenCode 데스크톱 앱과 OpenRouter의 결합을 보여주는 인포그래픽이다.
용어 해설
- Automation Bias
- — 인간이 자동화된 시스템의 제안을 비판 없이 수용하고 자신의 판단보다 알고리즘의 결과를 과도하게 신뢰하는 경향이다. 이는 시스템 오류 발생 시 인간의 감시 능력을 저하시켜 치명적인 사고로 이어질 수 있는 중요한 심리적 요인이다.
- Cognitive De-skilling
- — AI 도구에 지속적으로 의존함으로써 인간 전문가가 원래 보유하고 있던 핵심 역량이나 판단 능력이 점진적으로 퇴화하는 현상이다. 이는 AI가 없는 상황에서 전문가의 업무 수행 능력을 현저히 떨어뜨려 전체 시스템의 복원력을 약화시킨다.
- Confidence Calibration
- — 모델이 예측한 결과에 대해 부여하는 확률값(Confidence)이 실제 정답률과 일치하도록 조정하는 기법이다. 잘 보정된 모델은 자신이 모르는 것에 대해 낮은 점수를 부여하므로, 고위험 의사결정에서 시스템의 신뢰성을 판단하는 핵심 지표가 된다.
- Abstention
- — 모델이 입력된 쿼리에 대해 충분한 확신이 없거나 학습 범위를 벗어났다고 판단할 때 억지로 답을 내놓는 대신 답변을 거부하는 전략이다. 이를 통해 할루시네이션을 방지하고 해당 문제를 인간 전문가에게 자동으로 라우팅하여 안전성을 확보한다.
- RAG
- — 모델의 내부 파라미터에만 의존하지 않고 외부의 검증된 지식 베이스에서 관련 정보를 검색하여 입력 컨텍스트로 제공하는 방식이다. 최신 정보 반영이 가능하고 출처 제시를 통해 할루시네이션을 획기적으로 줄일 수 있어 실무 배포의 필수 기술로 꼽힌다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.
