핵심 요약
Anthropic은 DeepSeek, Moonshot AI, MiniMax가 24,000개 이상의 허위 계정을 통해 Claude와 1,600만 건 이상의 대화를 나누며 모델 능력을 무단 추출했다고 발표했다. 이는 미-중 AI 경쟁 구도에서 모델 보안과 지적 재산권 보호의 중요성을 부각하는 사건이다. 동시에 업계에서는 SWE-Bench Verified의 신뢰성 하락으로 인한 벤치마크 개편, 코딩 에이전트의 실질적 도입, 추론 효율성을 위한 웹소켓 기술 적용 등 기술적 진보와 진통이 병행되고 있다.
배경
LLM 증류(Distillation) 개념, 코딩 에이전트 아키텍처, RAG 및 컨텍스트 윈도우 이해
대상 독자
AI 보안 전문가, LLM 애플리케이션 개발자, AI 전략 기획자
의미 / 영향
미-중 기술 패권 경쟁이 모델 가중치 탈취를 넘어 API를 통한 능력 추출 전쟁으로 번지고 있다. 이는 향후 AI 기업들의 API 보안 정책과 수출 통제 논의에 결정적인 영향을 미칠 것으로 보인다.
섹션별 상세
이미지 분석
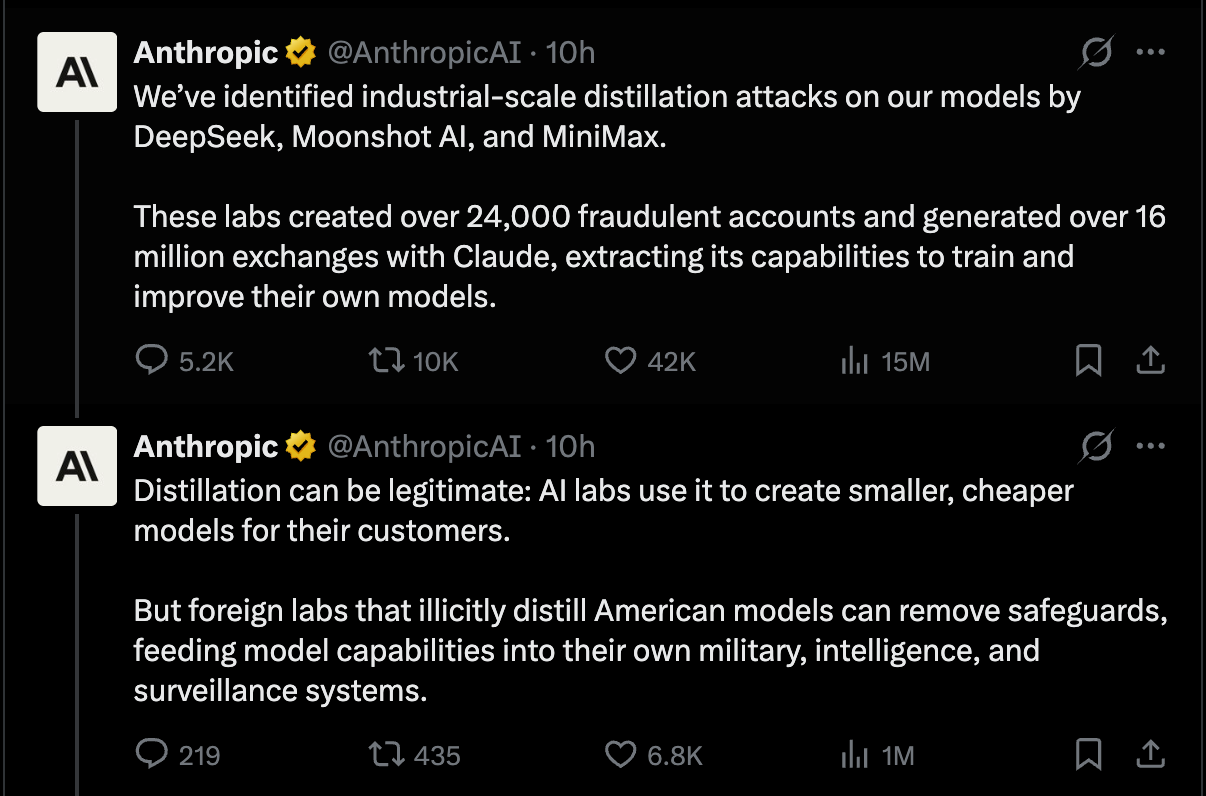
DeepSeek, Moonshot AI, MiniMax가 24,000개 이상의 계정을 동원해 1,600만 건의 대화를 생성하며 Claude의 능력을 추출했다는 구체적인 수치를 제시한다. 증류 기술이 합법적일 수 있으나 외국 연구소의 무단 추출은 안보 위협이 될 수 있음을 경고한다.
Anthropic의 공식 트위터 계정이 중국 AI 연구소들의 증류 공격을 폭로하는 게시물 캡처본이다.
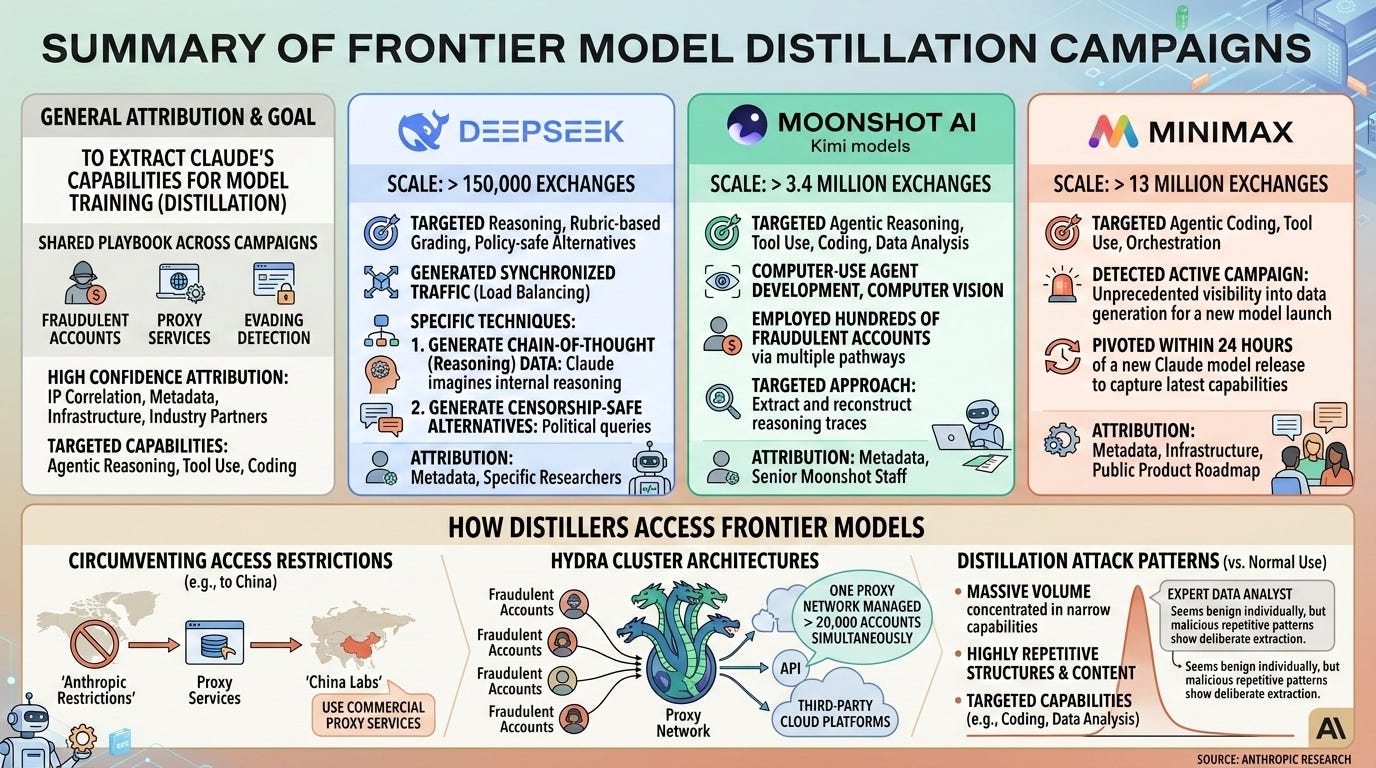
DeepSeek, Moonshot AI, MiniMax 각 연구소별 공격 규모와 타겟팅된 능력(추론, 코딩, 도구 사용 등)을 상세히 비교한다. 프록시 서비스와 허위 계정을 이용한 '히드라 클러스터' 아키텍처 등 공격자들이 접근 제한을 우회하는 기술적 방법론을 시각화하여 보여준다.
프론티어 모델 증류 캠페인에 대한 Anthropic의 연구 요약 인포그래픽이다.
실무 Takeaway
- 모델 출력값 추출을 통한 증류 공격이 고도화됨에 따라 API 수준에서의 부정 계정 탐지 및 행동 핑거프린팅 보안 강화가 필수적이다.
- 코딩 에이전트 도입 시 샌드박스 환경 구축과 명확한 권한 제어를 통해 파괴적인 자동화 오류를 방지해야 한다.
- 벤치마크 점수에만 의존하기보다 실제 업무 환경에서의 비용 대비 효율성과 데이터 오염 여부를 직접 검증하는 평가 루프를 구축해야 한다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료