핵심 요약
시계열 데이터는 순차적인 특성 때문에 정적인 데이터와 다른 피처 엔지니어링 접근 방식이 필요하다. XGBoost나 Random Forest 같은 전통적인 머신러닝 모델은 시간적 흐름을 스스로 파악하지 못하므로, 과거의 값을 현재로 가져오는 Lag 피처와 일정 구간의 통계량을 계산하는 Rolling 피처를 생성해야 한다. 시계열 예측에서 가장 치명적인 실수인 데이터 누수(Data Leakage)를 방지하기 위해 .shift(1)를 활용하는 것이 필수적이다. 이러한 기법들은 판매량 예측, 수요 계획, 주가 분석 등 실무 환경에서 모델의 정확도를 극대화하는 핵심 요소로 작용한다.
배경
Python 및 Pandas 라이브러리 기초 지식, 머신러닝 기본 개념 (회귀, 트리 기반 모델), 시계열 데이터의 기본 특성에 대한 이해
대상 독자
시계열 예측 모델을 개발하고 피처 엔지니어링을 통해 성능을 개선하려는 데이터 사이언티스트 및 ML 엔지니어
의미 / 영향
이 가이드는 시계열 데이터의 특성을 이해하지 못해 발생하는 성능 저하와 데이터 누수 문제를 해결할 수 있는 표준적인 워크플로우를 정립한다. 특히 트리 기반 모델을 시계열 예측에 적용할 때 필수적인 데이터 변환 기법을 구체적인 코드로 제시하여 실무 적용성을 높인다.
섹션별 상세
이미지 분석
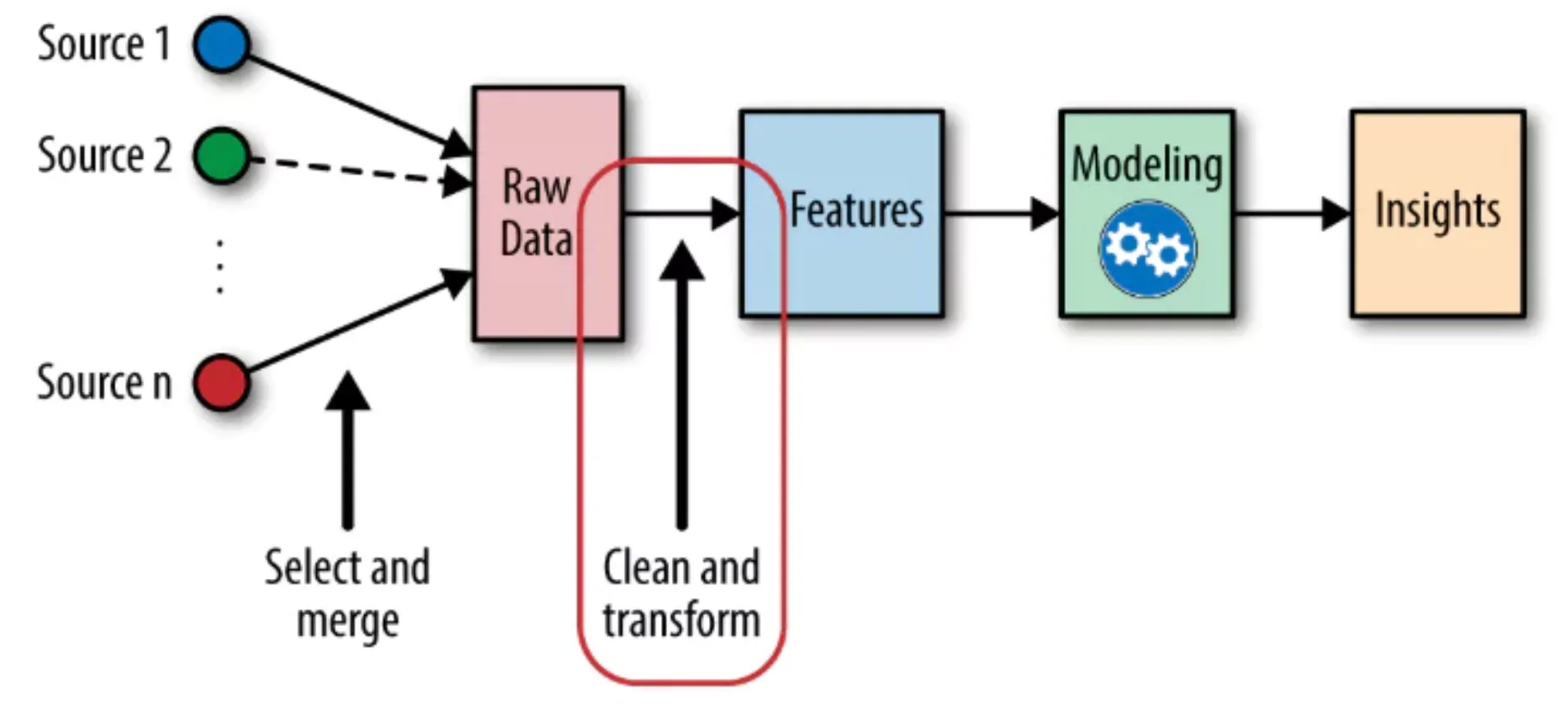
원시 데이터가 정제 및 변환 과정을 거쳐 피처로 생성되고, 모델링을 통해 최종 인사이트로 연결되는 과정을 시각화한다. 특히 'Clean and transform' 단계가 피처 생성의 핵심임을 보여준다.
데이터 소스부터 인사이트 도출까지의 전체 피처 엔지니어링 파이프라인 다이어그램이다.

과거 시점(t-1, t-2, t-3)의 값들이 어떻게 현재 시점의 예측 인자로 사용되는지 표와 그래프로 나타낸다. 시간적 패턴과 추세를 포착하는 데 Lag 피처가 기여함을 명시한다.
시계열 데이터에서 Lag 피처가 생성되는 원리를 설명하는 인포그래픽이다.
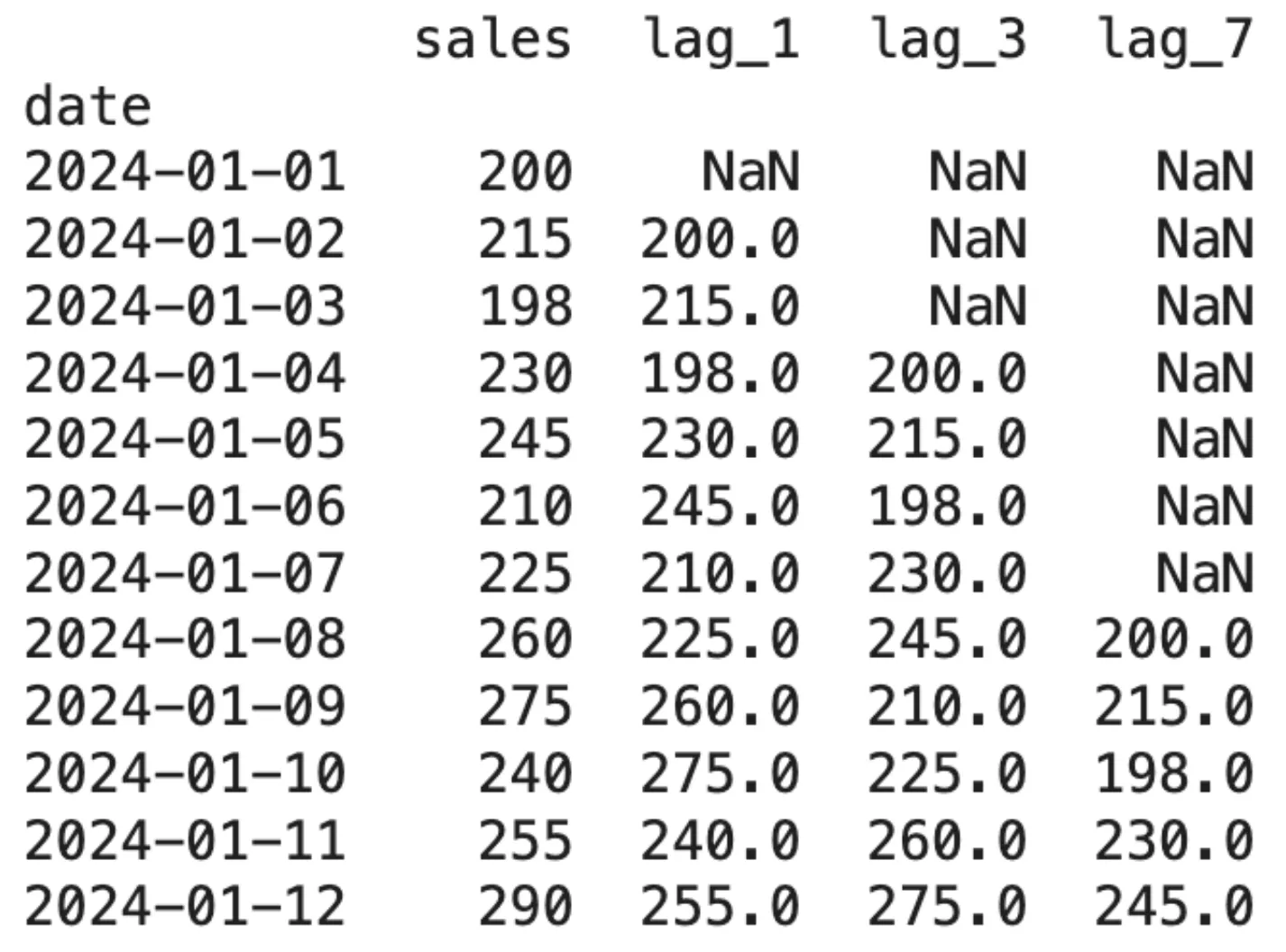
sales 열을 기준으로 lag_1, lag_3, lag_7 피처가 생성된 모습을 보여준다. 데이터 이동으로 인해 초기 행들에 발생하는 NaN(결측치) 값을 확인할 수 있다.
Pandas를 이용해 구현한 Lag 피처의 출력 결과 데이터프레임이다.

윈도우 크기가 3일 때, 특정 구간의 데이터를 합산하거나 평균을 내어 새로운 피처를 만드는 수식을 시각화한다. 노이즈 제거와 추세 파악에 유용함을 설명한다.
Rolling Window 기법을 이용해 평균과 합계를 계산하는 과정을 보여주는 다이어그램이다.
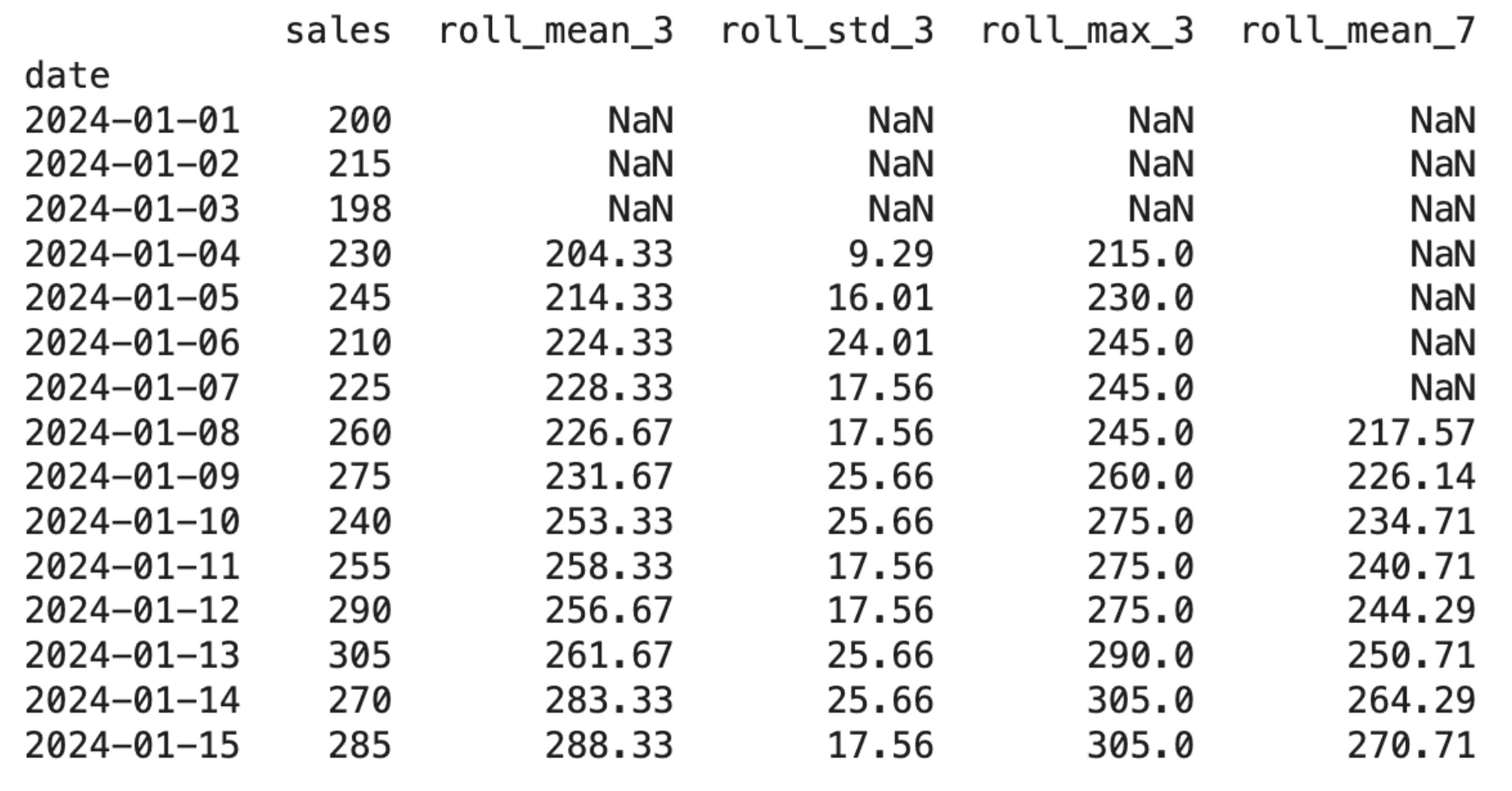
윈도우 크기 3과 7에 따른 통계량들이 계산된 결과를 보여준다. .shift(1)을 적용하여 현재 행의 sales 값이 계산에 포함되지 않았음을 수치로 증명한다.
Rolling Mean, Std, Max 등 다양한 이동 통계 피처가 적용된 데이터프레임 결과이다.

총 12개의 피처 컬럼이 생성되었으며, 데이터 누수 없이 정제된 최종 학습용 데이터셋의 형태를 보여준다. 원본 데이터 대비 행 수가 줄어든 것은 결측치 제거 결과임을 나타낸다.
Lag와 Rolling 피처를 모두 결합한 최종 엔지니어링 데이터의 구조와 샘플 행이다.
실무 Takeaway
- 시계열 피처 생성 시 반드시 .shift(1)을 적용하여 현재 시점의 데이터가 피처 계산에 포함되는 데이터 누수를 방지해야 한다.
- ACF(자기상관함수)를 활용하여 통계적으로 유의미한 Lag 값을 식별하고, 비즈니스 주기(예: 주간 7일)에 맞춘 피처를 우선적으로 생성한다.
- 노이즈가 많은 시계열 데이터에는 Rolling Mean을 적용해 추세를 부각시키고, 변동성 파악이 필요한 경우 Rolling Std를 추가 피처로 활용한다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료