핵심 요약
과거의 합성 데이터는 부족한 데이터를 보충하는 수준이었으나, 현대의 AI 에이전트 학습을 위해서는 복잡한 추론 과정과 도구 사용이 포함된 고품질 데이터가 필수적이다. 이러한 데이터 생성은 단순한 모델 호출을 넘어 다단계 에이전트 워크플로, 실시간 코드 실행 검증, 대규모 중복 제거 과정을 포함하며 '산업적 규모'의 컴퓨팅 부하를 발생시킨다. 메타의 Matrix와 같은 시스템은 분산 컴퓨팅 프레임워크를 활용해 이러한 '데이터 공장'을 구현하고 있으며, 이는 AI 인프라 현대화의 핵심 동력이 되고 있다. 결국 합성 데이터는 일회성 작업이 아닌, 모델 생애 주기 전반에 걸쳐 지속되는 상시 가동 인프라로 자리 잡고 있다.
배경
LLM 추론 및 파인튜닝 기본 지식, 분산 컴퓨팅 프레임워크(Ray 등)에 대한 이해, AI 에이전트 아키텍처 개념
대상 독자
AI 인프라 엔지니어 및 에이전트 시스템 개발자
의미 / 영향
합성 데이터 생성이 단순한 데이터 보강 도구에서 핵심적인 AI 인프라 구성 요소로 격상되었다. 이는 GPU 위주의 인프라 투자를 넘어 분산 컴퓨팅과 실시간 검증 환경을 포함한 종합적인 시스템 엔지니어링 역량의 중요성을 시사한다.
섹션별 상세

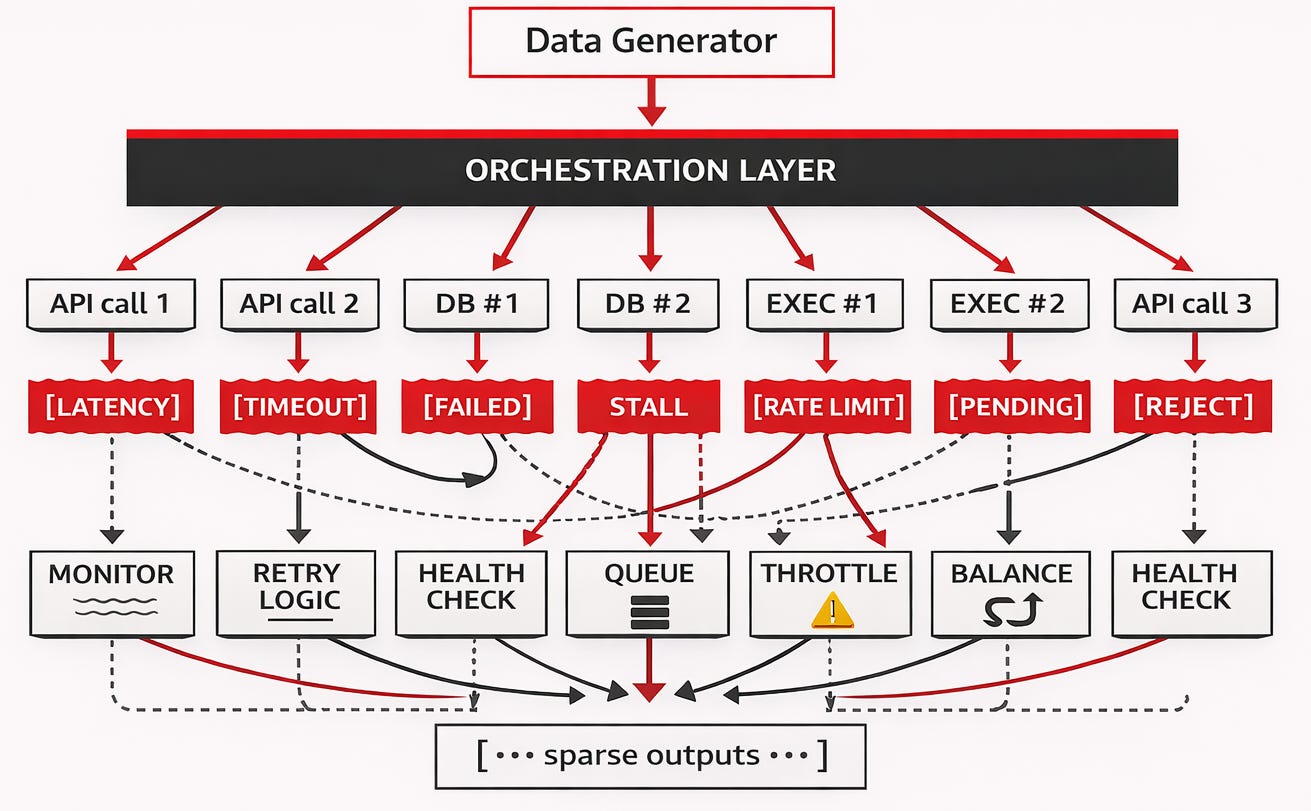

이미지 분석

모델 아키텍처 변화, 품질 보증 오버헤드, 인프라 요구사항 등 5가지 핵심 영역으로 분류하여 합성 데이터 생성의 복잡성을 시각화한다. 각 영역이 왜 산업적 규모의 컴퓨팅을 요구하는지 구체적인 근거를 제시한다.
합성 데이터 생성이 대규모 컴퓨팅을 필요로 하는 이유를 정리한 마인드맵이다.
실무 Takeaway
- 에이전트용 합성 데이터 파이프라인 구축 시 GPU 기반의 모델 추론뿐만 아니라 코드 실행을 위한 CPU 및 메모리 자원의 병목 현상을 사전에 고려해야 한다.
- 데이터의 품질을 보장하기 위해 최종 결과물만 검사하는 방식 대신, 각 단계별로 LLM 판독기나 실행 환경을 통한 실시간 검증 루프를 설계해야 한다.
- Ray나 Kubernetes와 같은 분산 컴퓨팅 도구를 활용하여 생성, 검증, 임베딩, 저장소 워크로드를 독립적으로 확장할 수 있는 유연한 인프라 구조를 채택해야 한다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.