TL;DR
NVIDIA Blackwell(B200) 아키텍처에서 지원하는 마이크로스케일링 포맷인 MXFP8과 NVFP4를 활용해 이미지 및 비디오 확산 모델의 추론 효율성을 극대화했다. Flux.1-Dev, LTX-2, QwenImage 모델을 대상으로 테스트한 결과, BF16 대비 MXFP8은 최대 1.26배, NVFP4는 최대 1.68배의 속도 향상을 달성했다. 단순히 전체 모델을 양자화하는 대신 특정 레이어를 제외하는 선택적 양자화(Selective Quantization)와 CUDA Graphs를 적용해 정확도 손실을 최소화하면서 CPU 오버헤드를 줄였다. LPIPS 지표를 통해 양자화 모델이 생성한 이미지의 시각적 품질이 원본과 유사함을 검증했으며, 실무에서 즉시 적용 가능한 TorchAO 기반의 구현 코드를 포함한다.
배경
NVIDIA Blackwell 아키텍처 GPU (B200 등), PyTorch Nightly 버전 및 TorchAO 라이브러리, Diffusers 라이브러리에 대한 기본 지식
대상 독자
NVIDIA Blackwell GPU 기반으로 고성능 이미지/비디오 생성 서비스를 구축하려는 ML 엔지니어 및 최적화 연구자
의미 / 영향
이 기술은 고해상도 생성 모델의 운영 비용을 획기적으로 낮추고 추론 처리량을 높여, Blackwell 아키텍처 기반 클라우드 인프라의 가치를 극대화합니다. 특히 NVFP4와 같은 초저정밀도 포맷이 시각적 품질을 유지하면서도 실용 가능하다는 것을 입증함으로써 차세대 양자화 표준의 방향성을 제시합니다.
섹션별 상세
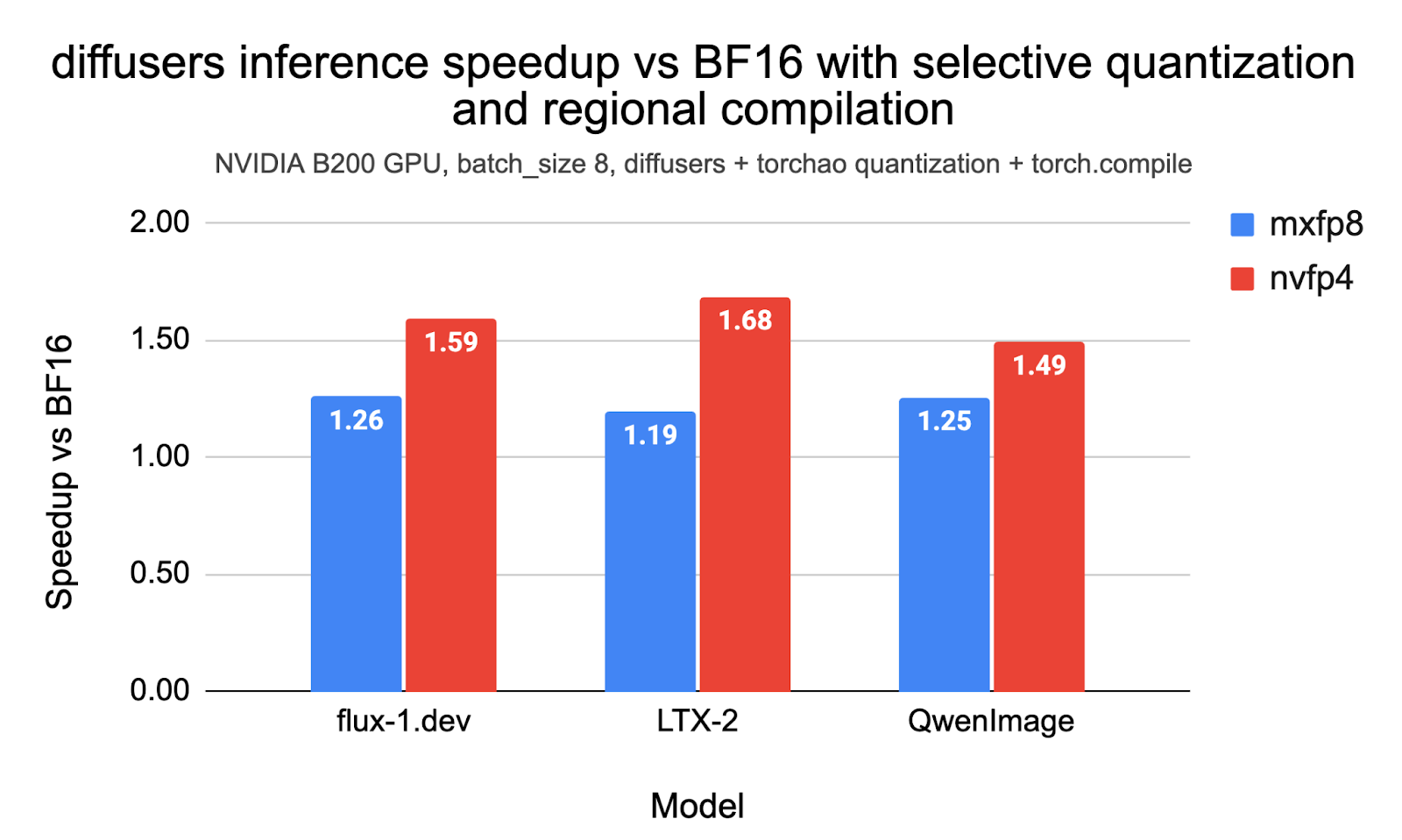
- Flux.1-Dev 모델에서 NVFP4 양자화 적용 시 BF16 대비 최대 1.59배의 속도 향상을 달성했다. — Benchmark Results - Flux.1-Dev - Performance and Peak Memory 표
from diffusers import DiffusionPipeline, TorchAoConfig, PipelineQuantizationConfig
import torch
from torchao.prototype.mx_formats.inference_workflow import (
NVFP4DynamicActivationNVFP4WeightConfig,
)
config = NVFP4DynamicActivationNVFP4WeightConfig(
use_dynamic_per_tensor_scale=True,
use_triton_kernel=True,
)
pipe_quant_config = PipelineQuantizationConfig(
quant_mapping={"transformer": TorchAoConfig(config)}
)
pipe = DiffusionPipeline.from_pretrained(
"black-forest-labs/FLUX.1-dev",
torch_dtype=torch.bfloat16,
quantization_config=pipe_quant_config
).to("cuda")
pipe.transformer.compile_repeated_blocks(fullgraph=True)TorchAO의 NVFP4 양자화 설정을 Diffusers 파이프라인에 적용하고 지역 컴파일을 활성화하는 예시
- LTX-2 비디오 모델에서 NVFP4 적용 시 최대 1.68배의 추론 가속이 확인됐다. — Benchmark Results - LTX-2 - Performance and Peak Memory 표

- CUDA Graphs를 적용했을 때 QwenImage 모델의 배치 사이즈 1 추론 속도가 1.81배 향상됐다. — Technical Considerations - Improving CPU Overhead with CUDA Graphs 섹션

용어 해설
- Microscaling Formats
- — 텐서 전체가 아닌 작은 블록 단위(16~32개 요소)로 고정밀 스케일 인자를 공유하는 양자화 방식이다. 이를 통해 낮은 비트 깊이에서도 넓은 동적 범위를 유지하며 정확도 손실을 최소화할 수 있다.
- MXFP8
- — OCP 표준의 8비트 마이크로스케일링 부동소수점 포맷이다. BF16 대비 시각적 품질 저하가 거의 없으면서도 빠른 추론 속도를 제공하여 성능과 정확도의 균형이 뛰어나다.
- NVFP4
- — NVIDIA Blackwell 아키텍처에서 가속되는 4비트 부동소수점 포맷이다. 가장 높은 처리량과 가장 낮은 메모리 점유율을 제공하여 연산 집약적인 대규모 배치 작업에 최적화되어 있다.
- LPIPS
- — 인간의 시각적 인지 유사도를 측정하는 딥러닝 기반 지표이다. 두 이미지 간의 차이를 수치화하며, 0에 가까울수록 원본과 시각적으로 구별하기 어려울 만큼 유사함을 의미한다.
- CUDA Graphs
- — GPU 작업을 일련의 그래프 형태로 정의하여 CPU 오버헤드를 줄이는 기술이다. 특히 배치 사이즈가 작은 추론 환경에서 CPU의 커널 실행 준비 시간을 단축해 전체 지연 시간을 크게 개선한다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.