TL;DR
강화 파인튜닝(RFT)은 정적 데이터셋 학습 대신 보상 신호를 통해 모델의 행동을 교정하여 기본 모델 대비 최대 66%의 정확도 향상을 제공한다. Amazon Bedrock은 AWS Lambda를 활용해 규칙 기반의 RLVR과 AI 피드백 기반의 RLAIF를 모두 지원하는 유연한 보상 함수 환경을 제공한다. GSM8K 수학 추론 데이터셋 실험 결과, RFT는 모델이 단순 패턴 매칭을 넘어 논리적 단계에 따라 정답을 도출하도록 유도함이 확인됐다. 학습 시에는 LoRA 기반 최적화를 통해 1e-4 수준의 학습률과 적절한 배치 크기를 설정하는 것이 성능 안정화에 핵심적이다. 이를 통해 개발자는 대규모 라벨링 비용 없이도 코드 생성, 구조화된 추출 등 복잡한 작업에서 모델 성능을 극대화할 수 있다.
배경
Amazon Bedrock 기본 사용법, 강화학습(RL) 및 파인튜닝의 기본 개념, AWS Lambda 구현 능력
대상 독자
Amazon Bedrock을 사용하여 특정 도메인에 특화된 고성능 LLM을 구축하려는 머신러닝 엔지니어 및 솔루션 아키텍트
의미 / 영향
이 기술은 대규모 고품질 라벨링 데이터 확보가 어려운 기업들에게 보상 함수 설계만으로 모델을 최적화할 수 있는 대안을 제시합니다. 특히 수학, 코딩, 데이터 추출 등 정답이 명확한 영역에서 SFT보다 적은 데이터로 더 높은 신뢰성을 확보할 수 있어 엔터프라이즈 AI 도입의 비용 효율성을 크게 높일 것입니다.
섹션별 상세
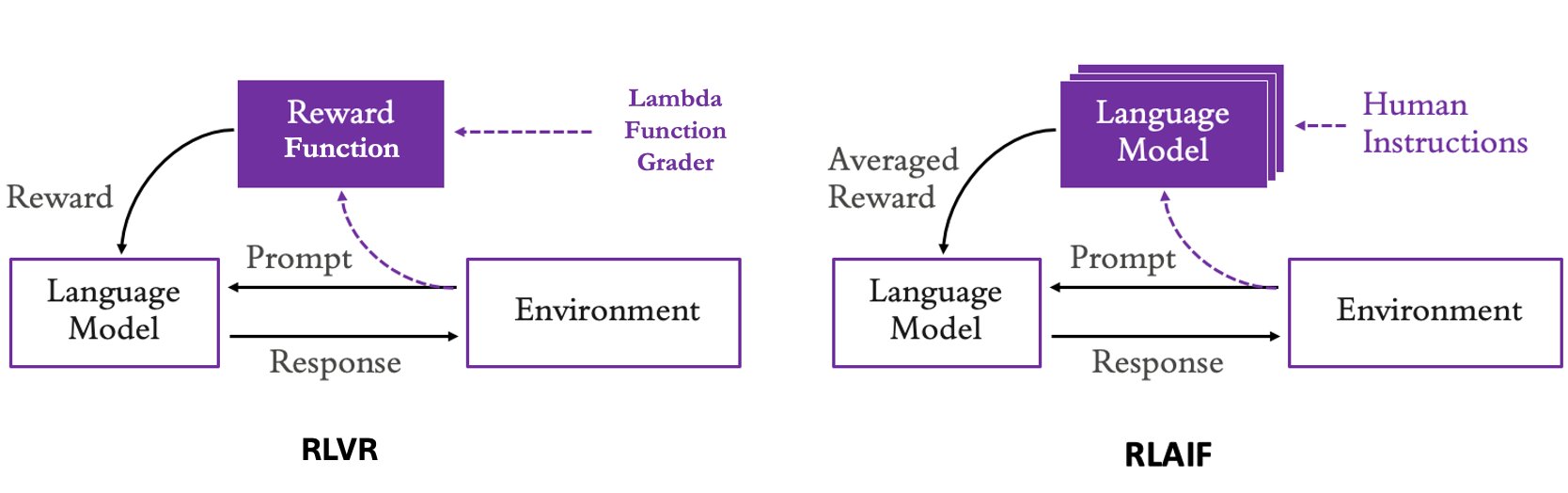
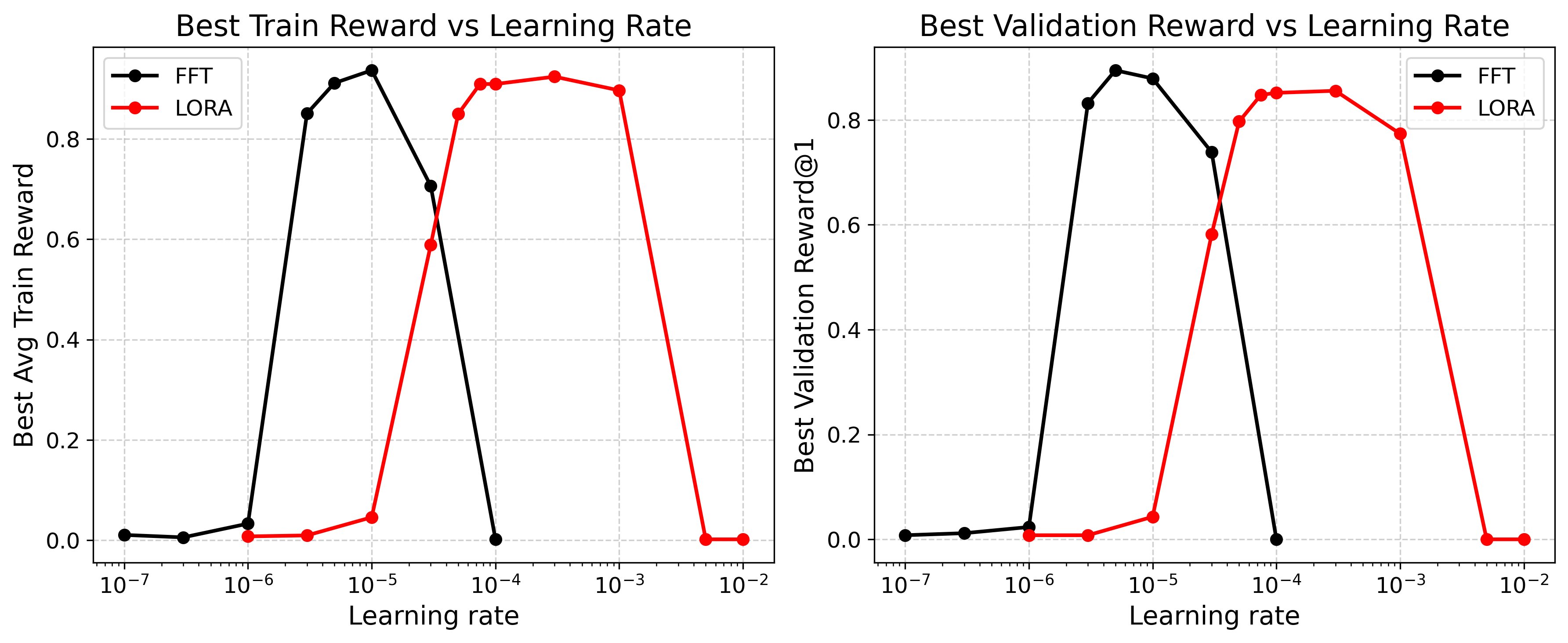
- LoRA 기반 RFT의 최적 학습률은 1e-4에서 1e-3 사이에서 정점을 찍는다. — Hyperparameter tuning guidelines - LearningRate 섹션 및 이미지 5
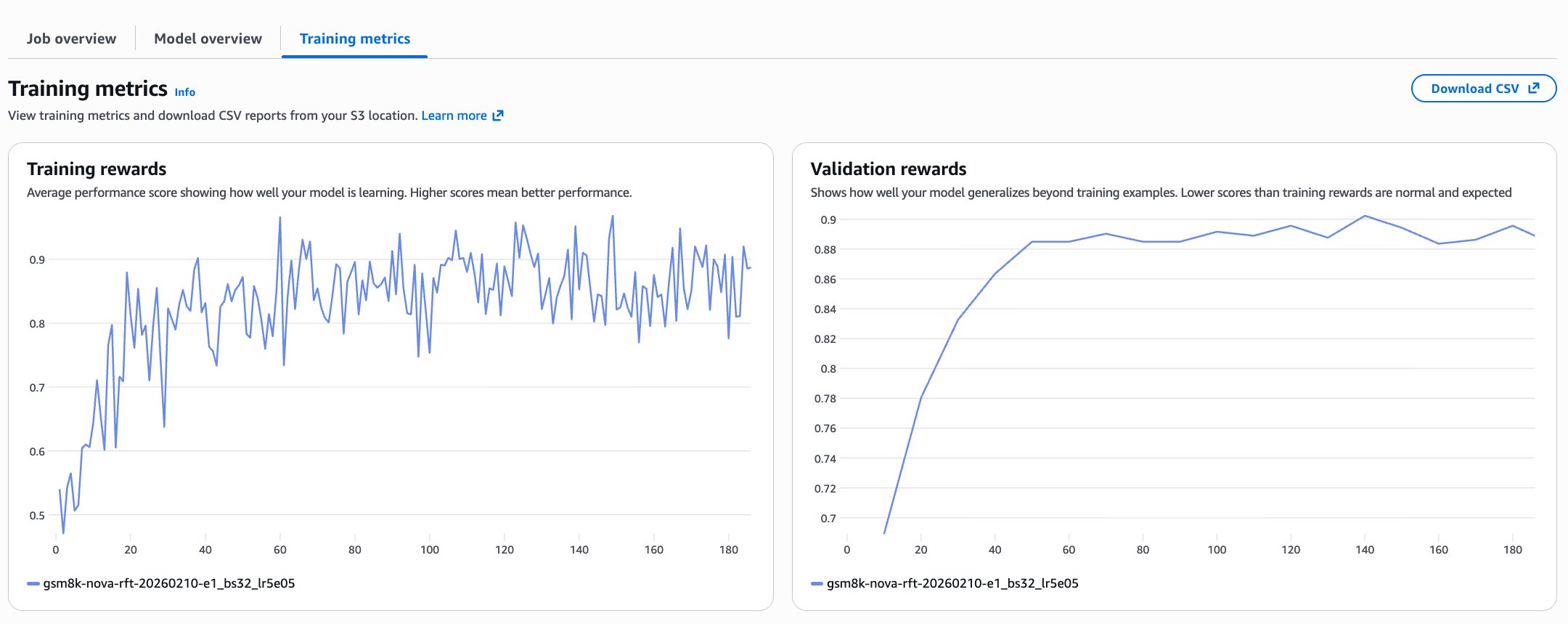
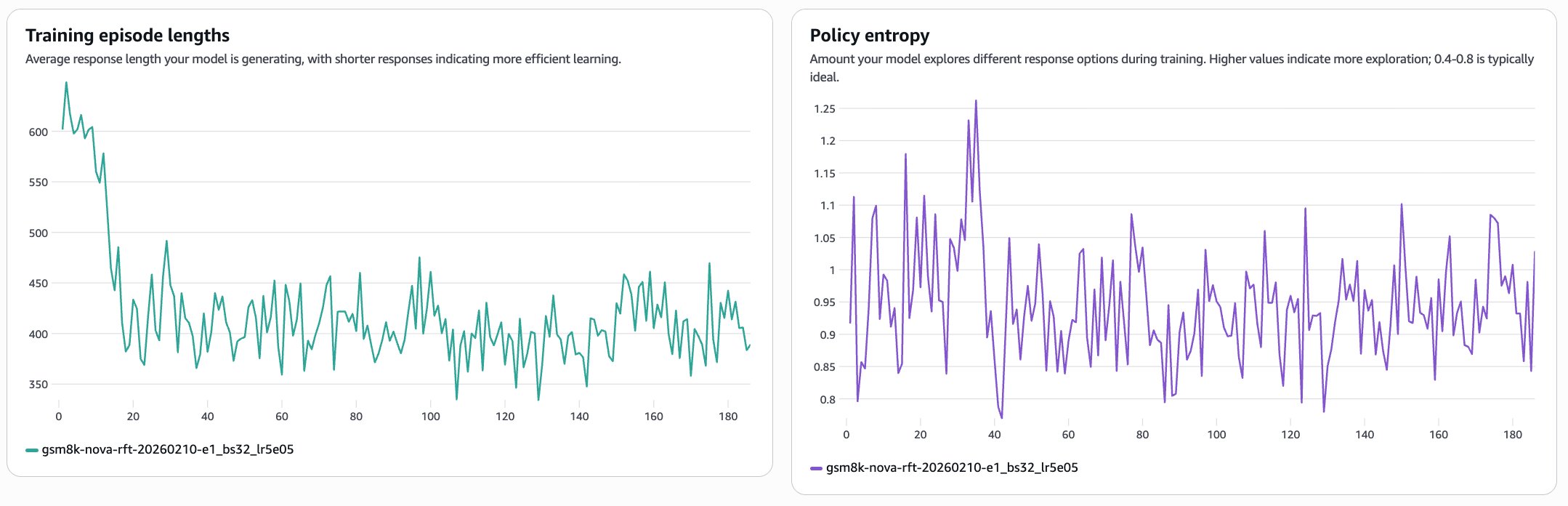
- 학습 과정에서 정책 엔트로피가 0.8~1.1 범위를 유지하는 것이 건강한 탐색의 신호이다. — Evaluating training progress 섹션 및 이미지 3
용어 해설
- Reinforcement Fine-Tuning
- — 정답 라벨이 있는 데이터셋 대신 보상 신호를 사용하여 모델의 행동을 개선하는 기법이다. 모델이 생성한 응답을 보상 함수가 평가하고, 높은 점수를 받은 행동의 확률을 높이는 방식으로 학습한다. 정답을 직접 보여주기 어렵지만 결과의 좋고 나쁨을 판별할 수 있는 작업에 효과적이다.
- RLVR
- — 코드 실행 결과나 수학 정답처럼 객관적으로 검증 가능한 규칙을 보상 신호로 사용하는 강화학습 방식이다. 유닛 테스트 통과율이나 정답 일치 여부를 즉각적인 피드백으로 활용한다. 모델이 단순히 패턴을 복제하는 대신 문제 해결을 위한 최적의 전략을 스스로 발견하도록 유도한다.
- RLAIF
- — 사람 대신 다른 고성능 언어 모델(Judge Model)이 생성물의 품질을 평가하여 보상을 제공하는 방식이다. 요약의 충실도나 대화의 자연스러움처럼 규칙으로 정의하기 어려운 주관적 가치를 학습시킨다. 사람이 직접 라벨링하는 비용과 시간을 획기적으로 줄이면서도 정렬된 결과를 얻을 수 있다.
- Policy Entropy
- — 모델이 응답을 생성할 때 얼마나 다양한 전략을 탐색하고 있는지를 나타내는 척도이다. 높은 엔트로피는 모델이 아직 불확실성을 가지고 다양한 시도를 하고 있음을 의미하며, 너무 낮으면 특정 답변에만 고착되는 모드 붕괴 위험이 있다. 학습 과정에서 건강한 탐색이 이루어지고 있는지 판단하는 지표로 쓰인다.
근거 모음
- RFT는 기본 모델 대비 최대 66%의 정확도 향상을 제공한다. — Introduction 섹션 첫 번째 문단
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.