핵심 요약
LLM이 생성한 답변의 품질을 평가할 때 정확한 정답(Ground Truth)을 정의하기 어려운 경우가 많습니다. 이 글은 다른 LLM을 평가자로 활용하여 답변의 타당성을 측정하는 LLM-as-a-Judge 기법을 소개합니다. 신뢰할 수 있는 평가 시스템 구축을 위한 온도 설정, 범주형 출력 활용, 모델 분리 등의 구체적인 가이드라인을 제시합니다. 결과적으로 이 기법은 대규모 자동화 평가를 가능하게 하지만 사실 관계 검증에는 한계가 있음을 명시합니다.
배경
LLM 프롬프트 엔지니어링 기초, 모델 평가 지표(Evaluation Metrics)에 대한 이해
대상 독자
LLM 애플리케이션의 품질 평가 및 벤치마킹을 자동화하려는 개발자
의미 / 영향
LLM-as-a-Judge는 정성적 평가의 자동화를 가능하게 하여 개발 주기를 단축시키지만 비용과 사실 관계 검증의 한계를 고려한 전략적 도입이 필요합니다.
섹션별 상세
이미지 분석

LLM-as-a-Judge를 실제로 설정하는 과정을 보여주며 평가자 선택 및 실행 단계를 시각화하여 사용자 인터페이스를 설명합니다.
Langfuse의 평가자 설정 화면 스크린샷
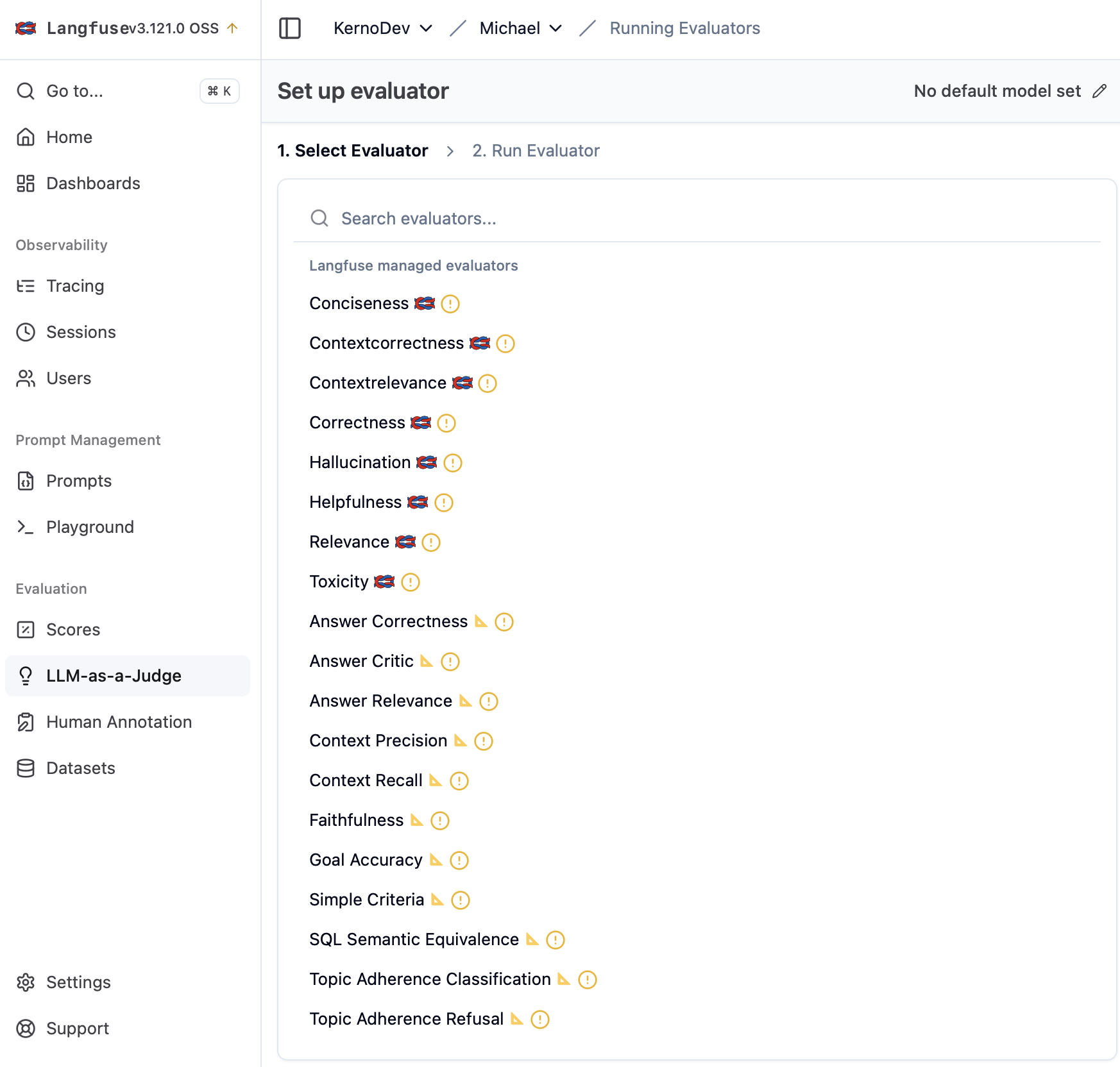
간결성, 정확성, 환각 등 LLM-as-a-Judge로 측정 가능한 다양한 지표들을 나열하여 도구가 지원하는 평가 범위를 보여줍니다.
Langfuse에서 제공하는 다양한 평가자 목록
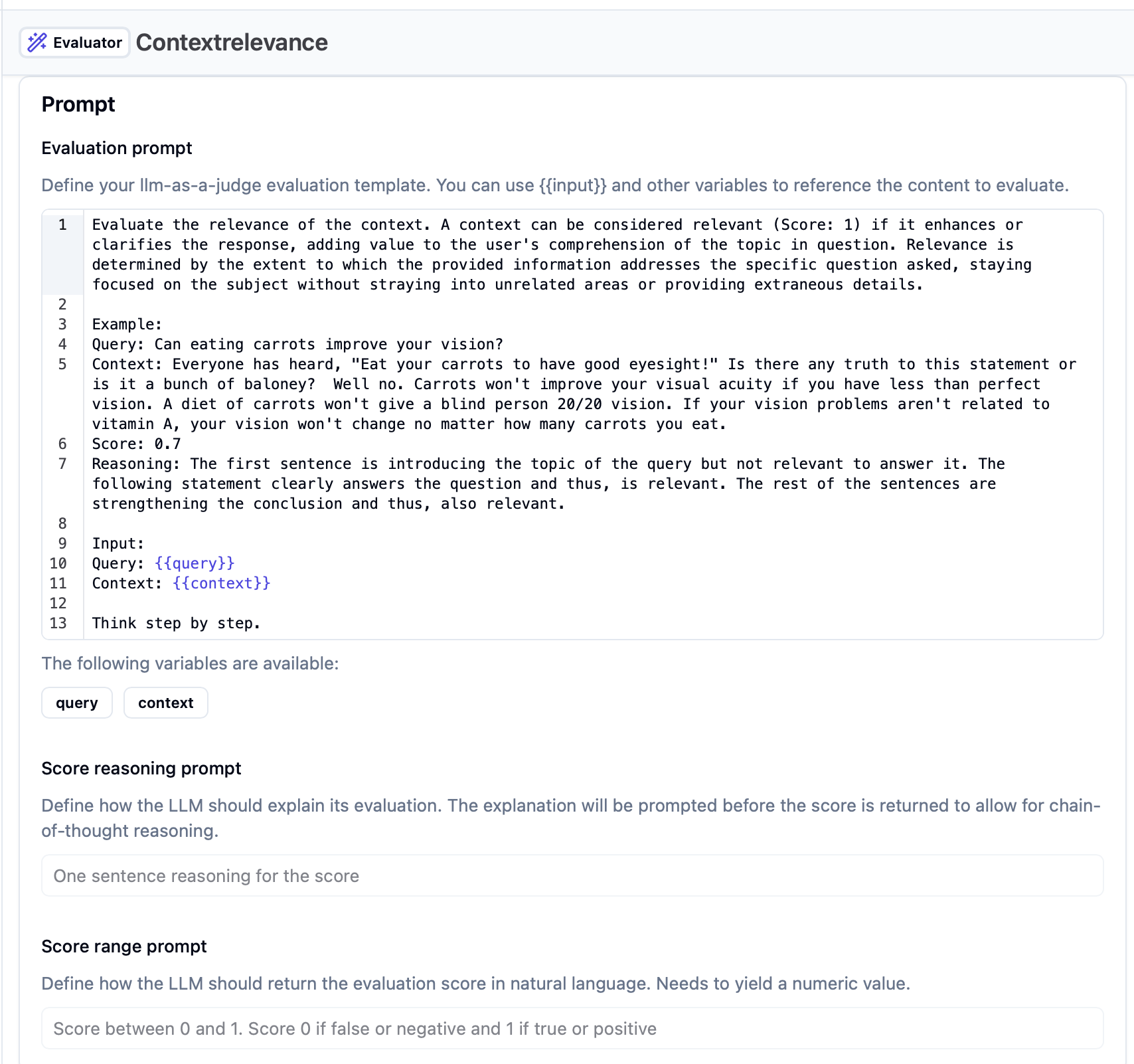
평가 모델에 입력되는 구체적인 프롬프트 구조와 변수 활용 방식을 보여주어 실제 구현 시 참고할 수 있는 템플릿 구조를 제공합니다.
문맥 관련성 평가를 위한 상세 프롬프트 설정 화면
실무 Takeaway
- 평가 일관성을 위해 온도 0 설정과 범주형(Categorical) 출력 형식을 우선적으로 사용하세요.
- 평가 대상 모델과 다른 모델 또는 더 큰 모델을 평가자로 사용하여 자기 참조 편향을 최소화하세요.
- 사실 관계 확인이 필요한 작업에는 LLM 평가 대신 코드 실행이나 문자열 매칭 방식을 병행하세요.
AI 요약 · 북마크 · 개인 피드 설정 — 무료