이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
대형 언어 모델(LLM)은 텍스트 기반 지식 요약과 추론에는 뛰어나지만, 물리적 세계의 복잡한 역학을 예측하고 질병을 치료하는 데는 한계가 있다. 진정한 과학적 돌파구를 위해서는 추론을 담당하는 '과학자(LLM)'와 물리적 현상을 정밀하게 모사하는 '시뮬레이터(도메인 모델)'가 협력하는 구조가 필요하다. 현재 AI 투자의 90% 이상이 LLM에 집중되어 있으나, 실제 가치는 물리적 데이터를 생성하는 자동화 인프라와 도메인 특화 모델에서 창출된다. 생물학처럼 복잡한 분야는 이론적 유도보다 데이터 기반의 패턴 매칭이 필수적이며, 이를 위한 전용 아키텍처와 인프라 구축이 시급하다.
배경
LLM 및 Transformer 아키텍처에 대한 기본 이해, AlphaFold 등 주요 과학 AI 모델의 존재와 역할에 대한 인지, 기초적인 물리 및 생물학적 복잡성에 대한 개념
대상 독자
AI 연구원, 과학 기술 분야 투자자, 바이오/소재 분야 AI 엔지니어
의미 / 영향
이 아티클은 LLM 중심의 현재 AI 트렌드가 실제 과학적 문제 해결에는 불충분함을 지적하며, 물리 세계와 상호작용하는 시뮬레이터와 데이터 인프라의 중요성을 일깨운다. 향후 AI 산업은 범용 지능 개발과 도메인 특화 과학 AI라는 두 개의 축으로 분화될 가능성이 높다.
섹션별 상세
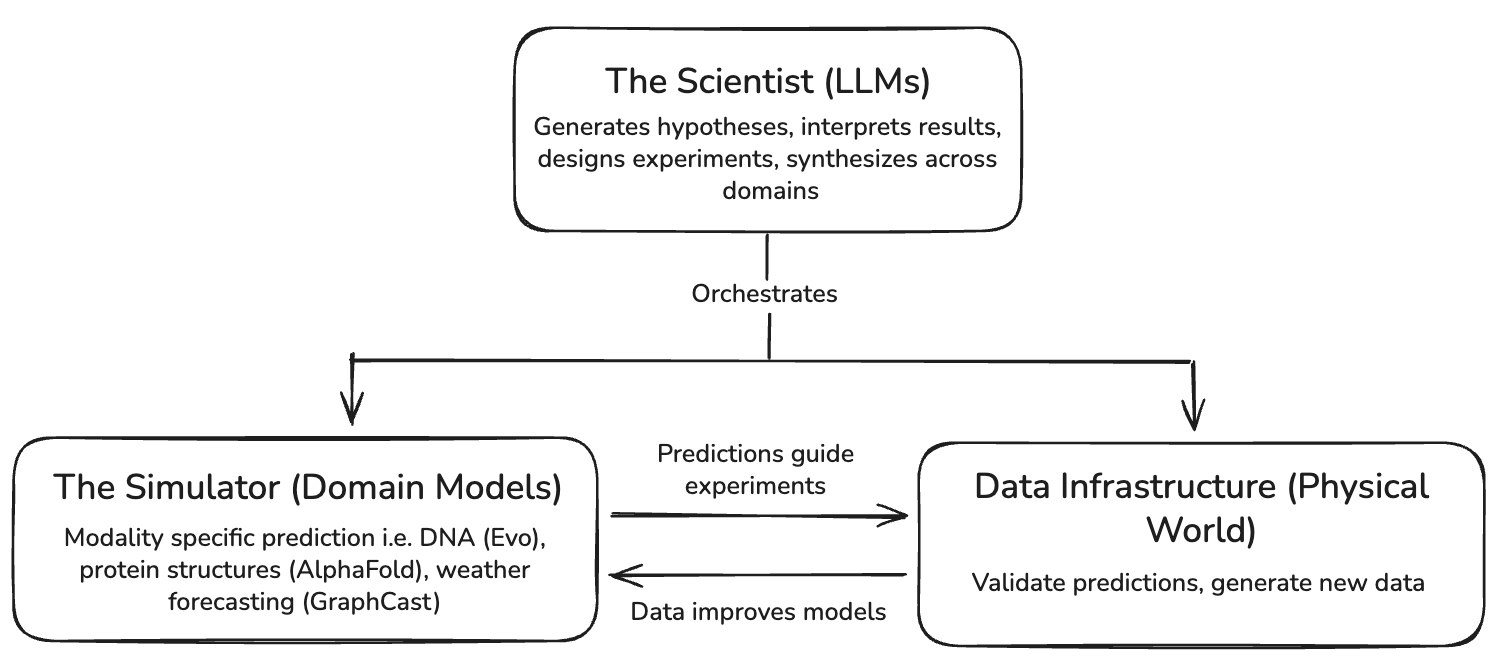
과학자(Scientist) 역할을 수행하는 LLM은 방대한 과학 문헌을 검토하고 가설을 생성하며 실험을 설계하는 고차원적 추론 업무를 담당한다. OpenAI와 Anthropic은 이미 실험실 워크플로우에 LLM을 통합하여 연구 속도를 높이고 있으며, 이는 에이전트 기술의 핵심 응용 분야로 자리 잡고 있다.
시뮬레이터(Simulator)는 물리적 법칙이나 생물학적 구조를 데이터로부터 직접 학습하여 예측하는 도메인 특화 모델이다. AlphaFold(단백질 구조), GraphCast(기상 예측), GNoME(신소재 발견) 등이 대표적이며, 이들은 Transformer 외에도 그래프 신경망(GNN) 등 도메인에 최적화된 아키텍처를 사용한다.
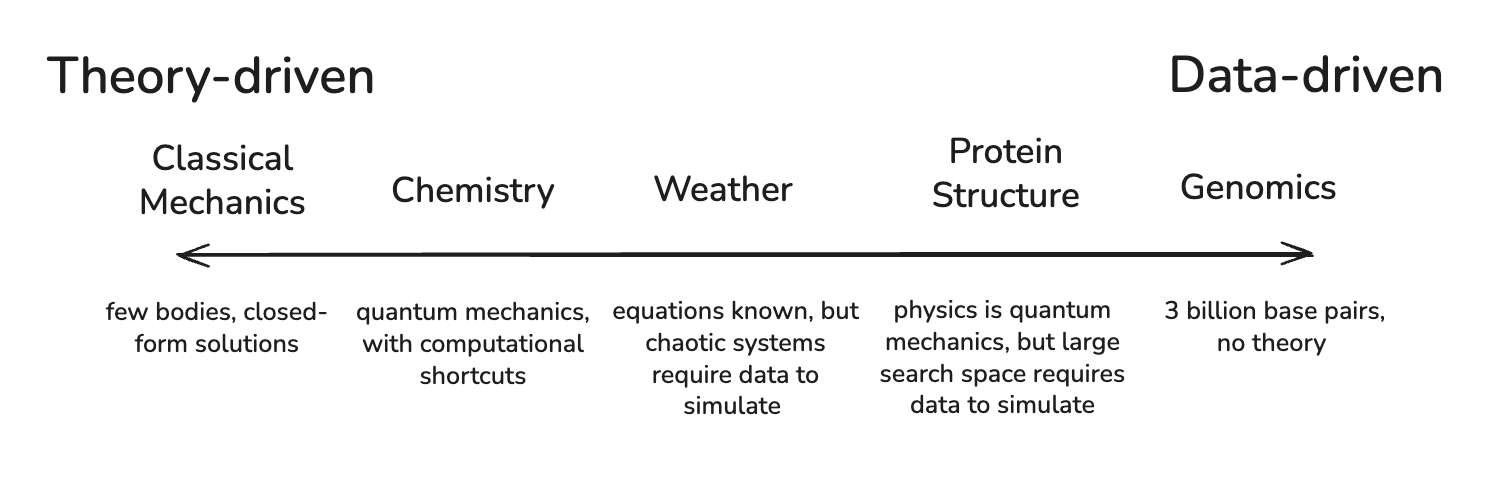
물리학과 생물학은 모델링 접근 방식에서 큰 차이를 보인다. 물리학은 소수의 법칙으로 시스템을 설명하는 이론 중심(Theory-driven) 접근이 가능하지만, 생물학은 수십억 개의 염기서열과 복잡한 상호작용으로 인해 데이터 중심(Data-driven)의 패턴 매칭이 필수적이다.
과학 AI의 가장 큰 병목 현상은 물리 세계의 데이터를 확보하는 인프라에 있다. 특히 생물학 데이터는 획득 비용이 높고 노이즈가 많아, 로봇 실험실(AI Science Factories)과 같은 자동화된 고처리량 실험 시스템을 통한 데이터 생성 루프 구축이 중요하다.
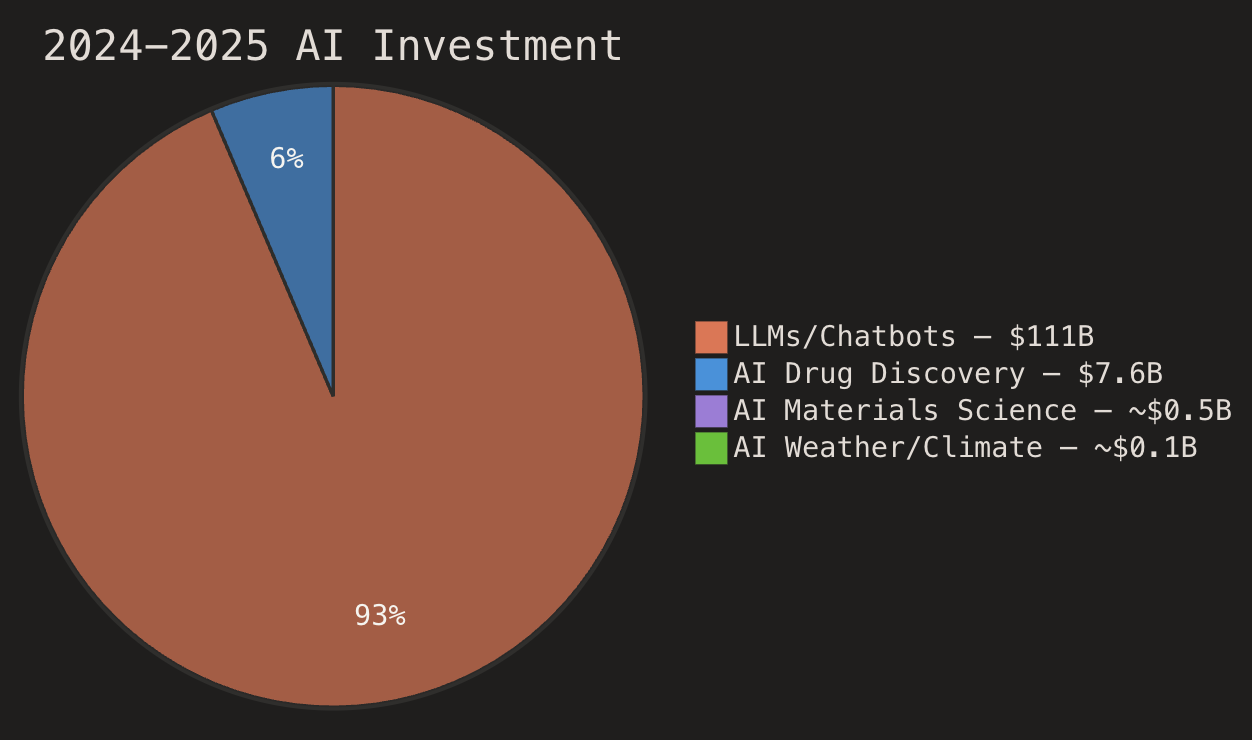
2024-2025년 AI 투자 현황을 보면 LLM 및 챗봇 분야에 1,110억 달러가 투입된 반면, 신약 개발이나 기후 분야 투자는 그 10분의 1에도 미치지 못한다. 프론티어 랩들이 범용 지능에 집중하는 동안, 실제 물리적 문제를 해결할 시뮬레이터와 인프라 기업들에 대한 독립적인 생태계 조성이 필요하다.
용어 해설
- Graph Neural Network
- — 그래프 구조의 데이터를 처리하기 위해 설계된 신경망 구조이다. 노드와 엣지 간의 관계를 학습하여 기상 예측(GraphCast)이나 분자 구조 분석처럼 요소 간 상호작용이 중요한 도메인에서 탁월한 성능을 발휘한다.
- Density Functional Theory
- — 양자 역학 체계에서 전자 밀도를 이용해 물질의 전자 구조를 계산하는 방법론이다. 신소재 발견 시 시뮬레이션의 기준점(Ground Truth) 역할을 하며, 계산 복잡도가 높아 AI 모델의 학습 데이터 생성에 주로 활용된다.
- Inductive Bias
- — 학습 모델이 접해보지 않은 데이터에 대해 예측할 때 사용하는 가정들의 집합이다. 특정 도메인의 물리 법칙이나 대칭성을 모델 구조에 반영함으로써 데이터 효율성과 예측 정확도를 높이는 역할을 한다.
- State Space Model
- — 시계열 데이터의 상태 변화를 수학적으로 모델링하는 기법이다. Transformer의 연산 복잡도 문제를 해결할 대안으로 주목받으며, 특히 긴 DNA 서열 모델링과 같은 대규모 과학 데이터 처리에 효과적이다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 02. 11.수집 2026. 02. 21.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.

