이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
현재의 LLM은 다음 토큰을 예측하는 '단어 모델'에 기반하여 겉보기에 완벽한 결과물을 만들어내지만, 실제 환경에서 타인과 상호작용하는 '세계 모델'은 부족하다. 체스처럼 모든 정보가 공개된 영역에서는 LLM이 우수하지만, 포커처럼 숨겨진 정보와 상대의 의도를 읽어야 하는 영역에서는 한계를 보인다. 전문가들은 결과물 자체보다 그 결과물이 환경 내 다른 에이전트들에게 어떤 반응을 이끌어낼지를 시뮬레이션하며, AI가 이를 극복하기 위해서는 결과 중심의 강화학습과 멀티 에이전트 훈련이 필요하다.
배경
LLM 추론 메커니즘에 대한 기본 이해, RLHF 및 강화학습의 기본 개념, 게임 이론의 기초 지식
대상 독자
LLM 에이전트를 개발하거나 프로덕션에 배포하는 엔지니어 및 AI 전략가
의미 / 영향
이 아티클은 LLM의 추론 능력이 텍스트 생성 수준을 넘어 타인의 심리와 사회적 역학을 시뮬레이션하는 방향으로 진화해야 함을 시사한다. 이는 향후 AI 훈련 방식이 정적인 데이터셋 학습에서 동적인 멀티 에이전트 환경에서의 강화학습으로 이동할 것임을 예고한다.
섹션별 상세
LLM은 겉보기에 훌륭한 결과물(Artifact)을 생성하지만, 전문가들은 이를 환경 내 다른 에이전트들과의 상호작용 속에서 실행되는 '수(Move)'로 평가한다. LLM은 텍스트의 일관성과 톤을 맞추는 데 집중하는 반면, 전문가는 해당 텍스트가 상대방의 인센티브와 제약 조건에 어떻게 작용할지를 시뮬레이션한다.
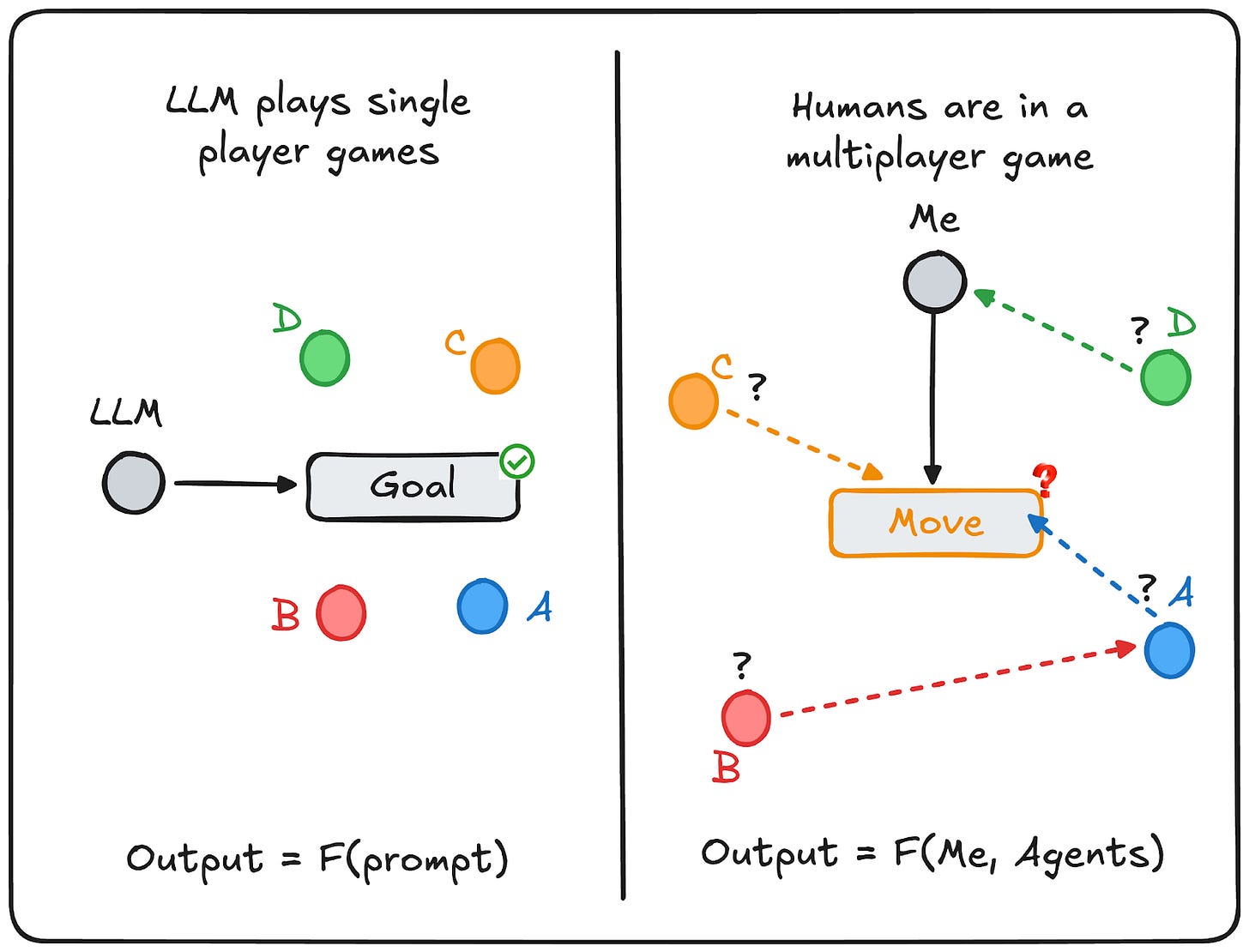
체스와 같은 완전 정보 게임에서는 모든 상태가 공개되어 있어 상대의 마음을 모델링할 필요가 없으며, LLM은 이와 유사한 결정론적 도메인(코드 작성, 수학)에서 뛰어난 성능을 보인다. 반면 포커와 같은 불완전 정보 게임은 정보의 비대칭성을 활용한 기만과 상대방의 모델을 역으로 이용하는 재귀적 추론이 필수적이다.
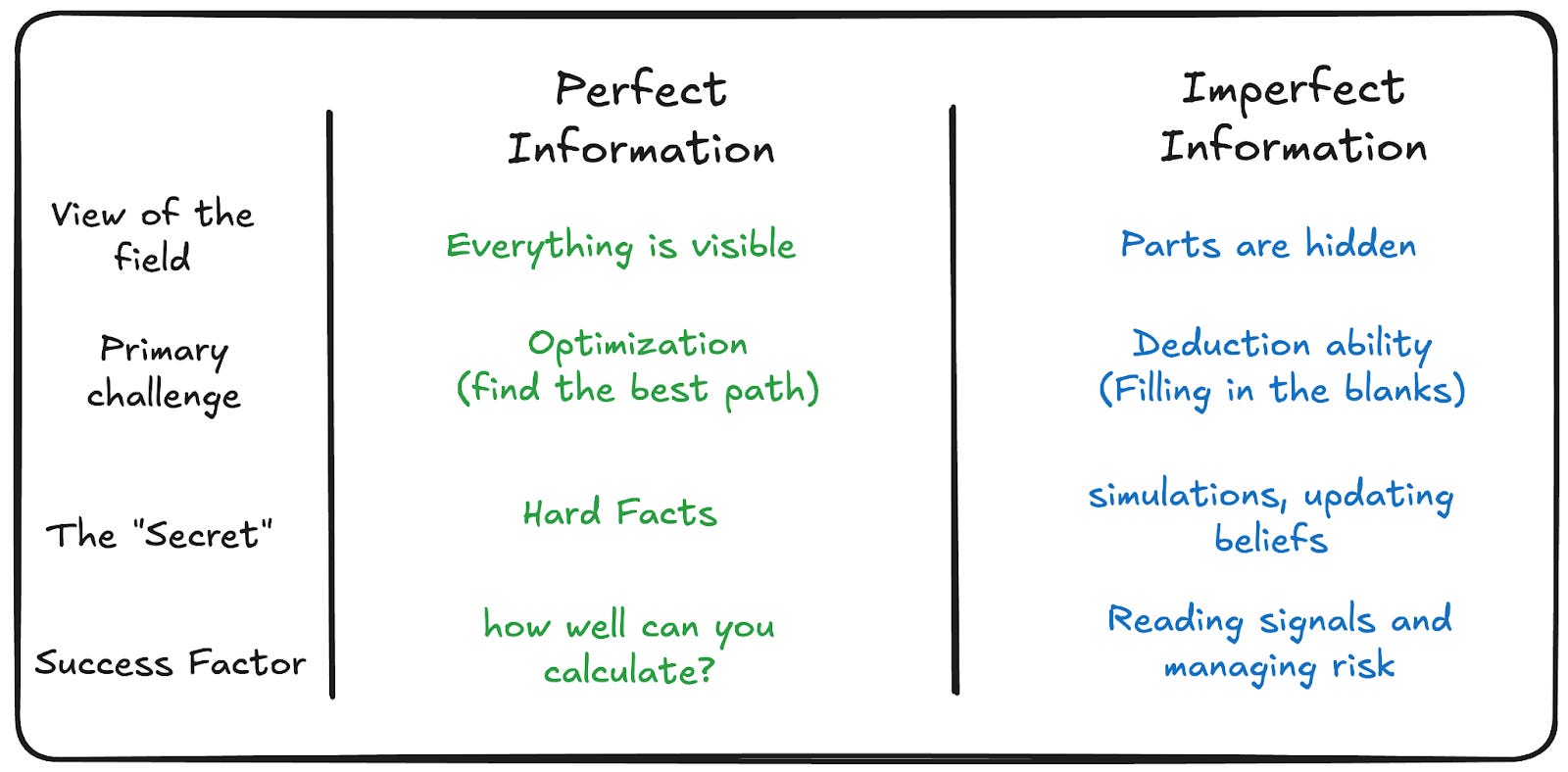
Meta의 Pluribus와 같은 포커 AI는 자신의 패와 상관없이 모든 가능성을 고려하여 전략을 균형 있게 배분함으로써 상대방이 자신의 행동에서 정보를 읽어내지 못하게(Unreadable) 설계되었다. 현재의 LLM은 RLHF를 통해 협력적이고 예측 가능한 패턴을 보이도록 학습되었으며, 이는 적대적 환경에서 상대방에게 쉽게 읽히고 이용당하는 취약점이 된다.
LLM은 상대방이 자신을 테스트하거나 정보를 캐내기 위해 프로빙(Probing)을 수행하고 있다는 사실을 감지하지 못하는 '읽히기 쉬운(Readable)' 상태에 머물러 있다. 인간 전문가는 상대의 의도를 파악하고 의도적으로 오해의 소지가 있는 신호를 보내는 등 재귀적으로 대응하지만, LLM은 고정된 프롬프트 전략을 일관되게 수행하여 패턴이 노출된다.

AI가 진정한 전문가 수준의 전략적 능력을 갖추기 위해서는 '다음 토큰 예측'에서 벗어나 자신의 행동이 가져올 환경의 변화를 예측하는 '다음 상태 예측'으로 학습 패러다임이 전환되어야 한다. 이를 위해 텍스트의 품질이 아닌 실제 결과(Outcome)를 보상으로 제공하는 멀티 에이전트 강화학습 환경에서의 훈련이 필수적이다.
용어 해설
- Theory of Mind
- — 타인의 지식, 믿음, 의도 등 정신 상태를 추론하고 이해하는 능력이다. AI가 멀티 에이전트 환경에서 상대방의 다음 행동을 예측하고 자신의 행동이 상대에게 어떻게 해석될지 시뮬레이션하는 데 필수적인 요소이다.
- Imperfect Information Game
- — 포커처럼 모든 플레이어가 게임의 전체 상태를 알 수 없는 게임이다. 상대방의 숨겨진 정보(패)를 추론하고 자신의 정보를 전략적으로 노출하거나 숨기는 기만과 블러핑이 핵심적인 전략 요소가 된다.
- Adversarial Robustness
- — 상대방이 시스템의 취약점을 찾아내어 악용하려 할 때도 의도한 성능을 유지하는 능력이다. LLM 에이전트가 협상이나 보안 환경에서 상대의 유도 질문이나 전략적 프로빙에 넘어가지 않고 목표를 달성하는 능력을 의미한다.
- Test-time Compute
- — 모델이 답변을 내놓기 전 더 많은 추론 단계나 시뮬레이션을 거치도록 자원을 투입하는 기법이다. OpenAI의 o1 모델처럼 복잡한 전략적 상황에서 여러 시나리오를 검토하여 최적의 '수'를 찾기 위해 사용된다.
- RLHF
- — 인간의 선호도에 맞춰 모델을 미세 조정하는 기법이다. 모델을 더 유용하고 안전하게 만들지만, 적대적 상황에서도 지나치게 협력적이고 예의 바른 태도를 보이게 만들어 전략적 유연성을 떨어뜨리는 부작용을 낳기도 한다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 02. 08.수집 2026. 02. 21.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.
