핵심 요약
Anthropic과 OpenAI가 차세대 코딩 특화 모델인 Claude Opus 4.6과 GPT-5.3-Codex를 동시에 발표하며 AI 업계의 기술 경쟁이 심화되고 있다. Anthropic은 100만 토큰 컨텍스트 창과 자율적 에이전트 팀 기능을 강조한 반면, OpenAI는 NVIDIA GB200 하드웨어 최적화와 압도적인 추론 속도 및 토큰 효율성을 내세웠다. 이번 업데이트는 단순한 모델 개선을 넘어 지식 노동을 자동화하는 에이전트 플랫폼으로의 진화를 보여주며, 소프트웨어 개발 및 기업용 워크플로우에 근본적인 변화를 예고한다.
배경
LLM 벤치마크 지표(SWE-bench, ARC-AGI)에 대한 이해, 에이전트 아키텍처 및 멀티 에이전트 시스템 개념, NVIDIA Blackwell 하드웨어 구조에 대한 기초 지식
대상 독자
AI 엔지니어, 소프트웨어 아키텍트, LLM 프로덕션 개발자
의미 / 영향
이번 동시 출시는 AI 모델이 단순한 보조 도구에서 자율적인 에이전트로 전환되는 변곡점을 의미한다. 특히 하드웨어 최적화와 롱 컨텍스트 기술의 결합은 소프트웨어 개발 비용을 획기적으로 낮추고 지식 노동의 자동화 속도를 가속화할 것이다.
섹션별 상세
이미지 분석
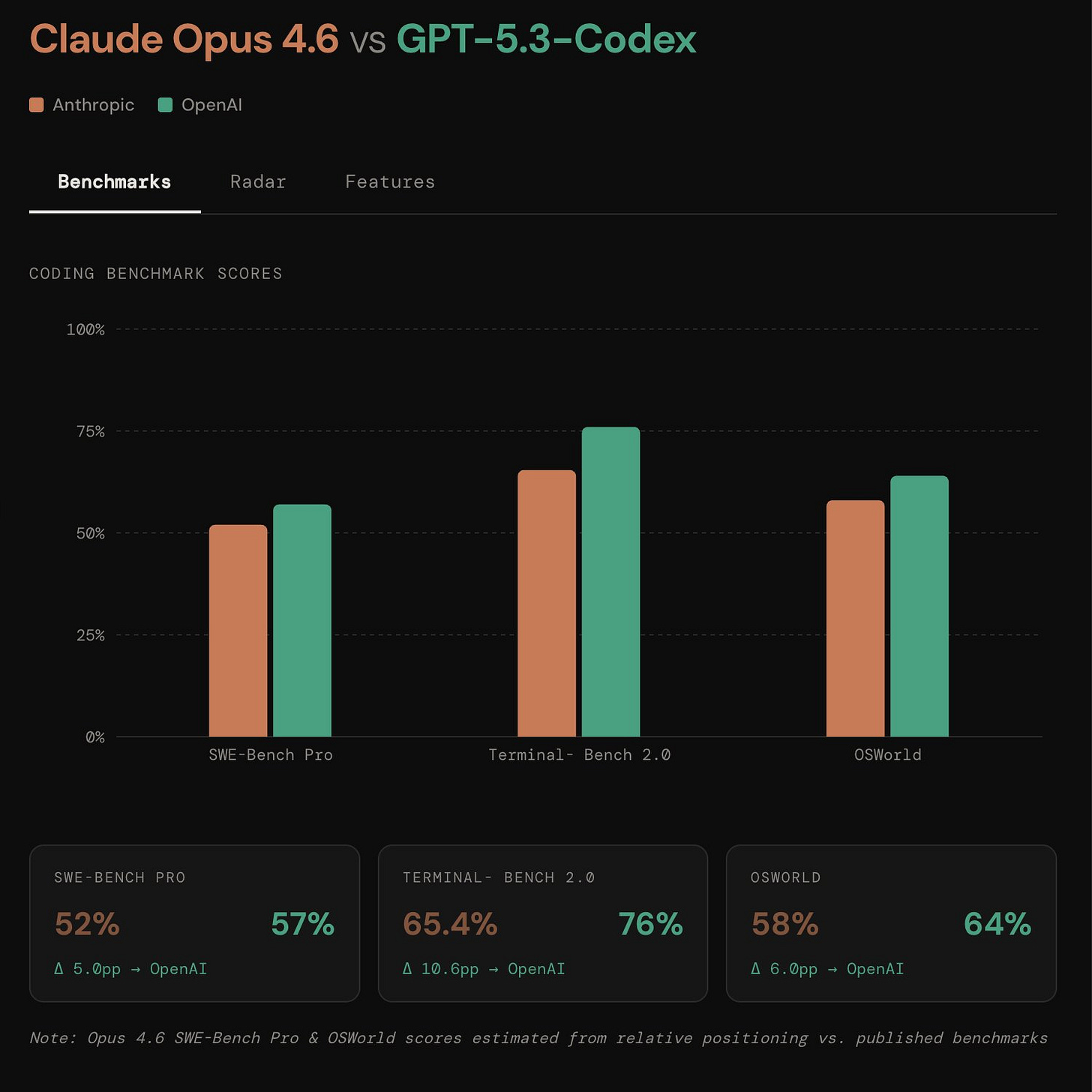
SWE-Bench Pro, Terminal-Bench 2.0, OSWorld 세 가지 지표 모두에서 GPT-5.3-Codex가 Claude Opus 4.6을 앞서고 있음을 보여준다. 특히 Terminal-Bench 2.0에서 10.6%p의 가장 큰 격차를 기록하며 OpenAI 모델의 우위를 입증한다.
Claude Opus 4.6과 GPT-5.3-Codex의 주요 코딩 벤치마크 점수 비교 차트이다.
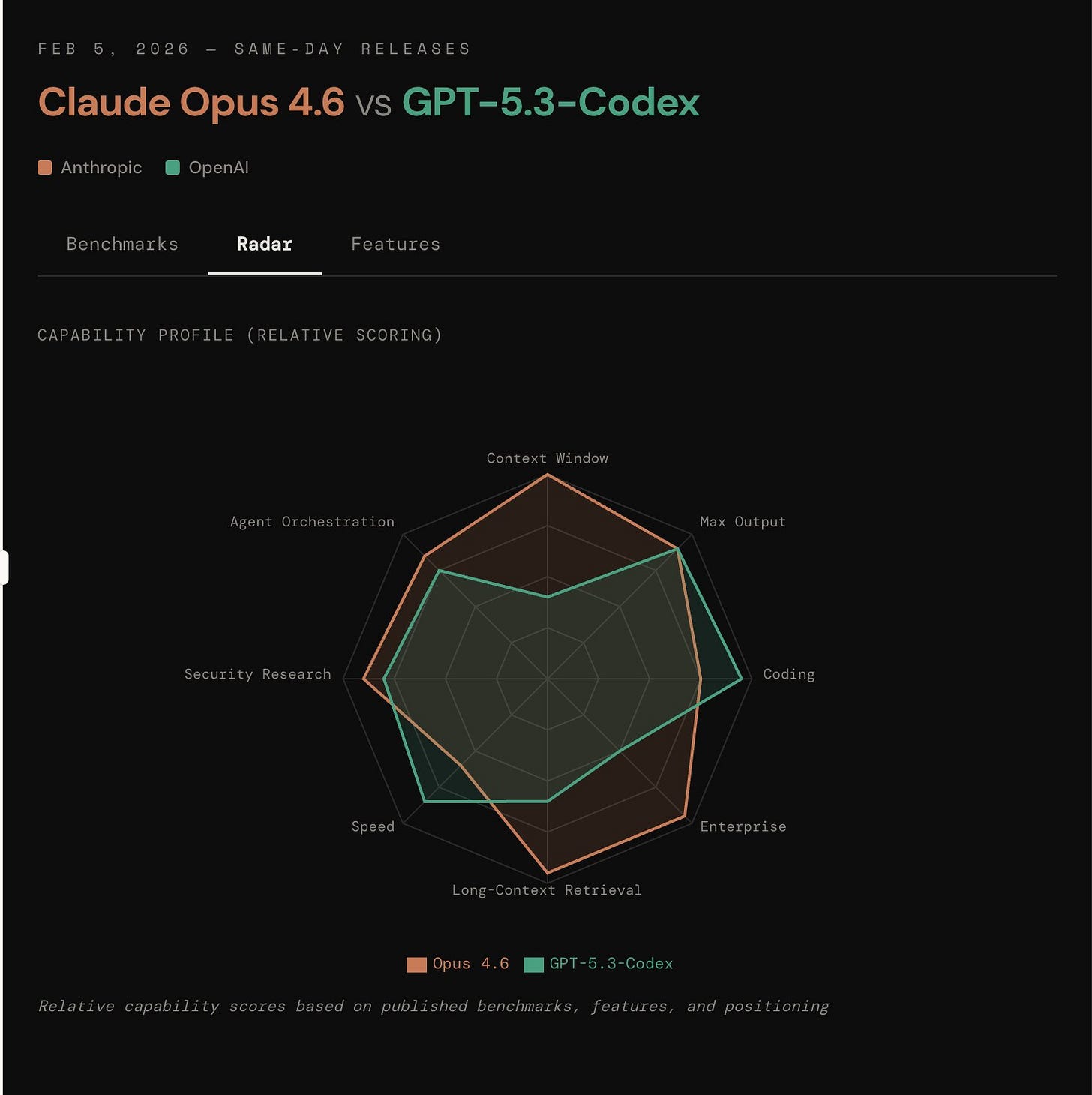
Claude Opus 4.6은 컨텍스트 창(Context Window)과 롱 컨텍스트 검색(Long-Context Retrieval)에서 압도적인 면모를 보이며, GPT-5.3-Codex는 속도(Speed)와 코딩(Coding) 역량에서 상대적 우위를 점하고 있음을 시각화한다.
두 모델의 역량 프로필을 비교한 레이더 차트이다.
실무 Takeaway
- 코딩 모델 선택 시 단순 성능뿐만 아니라 토큰 효율성과 추론 속도가 비용 최적화의 핵심 지표로 부상했다.
- 100만 토큰 이상의 롱 컨텍스트는 대규모 코드베이스 전체를 이해하고 리팩터링하는 에이전트 워크플로우의 필수 요소가 되었다.
- 기업은 단순 챗봇을 넘어 자율적으로 업무를 수행하고 결과를 검증하는 에이전트 플랫폼 도입을 검토해야 한다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료