이 요약은 AI가 원문을 분석해 생성했습니다. 정확한 내용은 원문 기준으로 확인하세요.
TL;DR
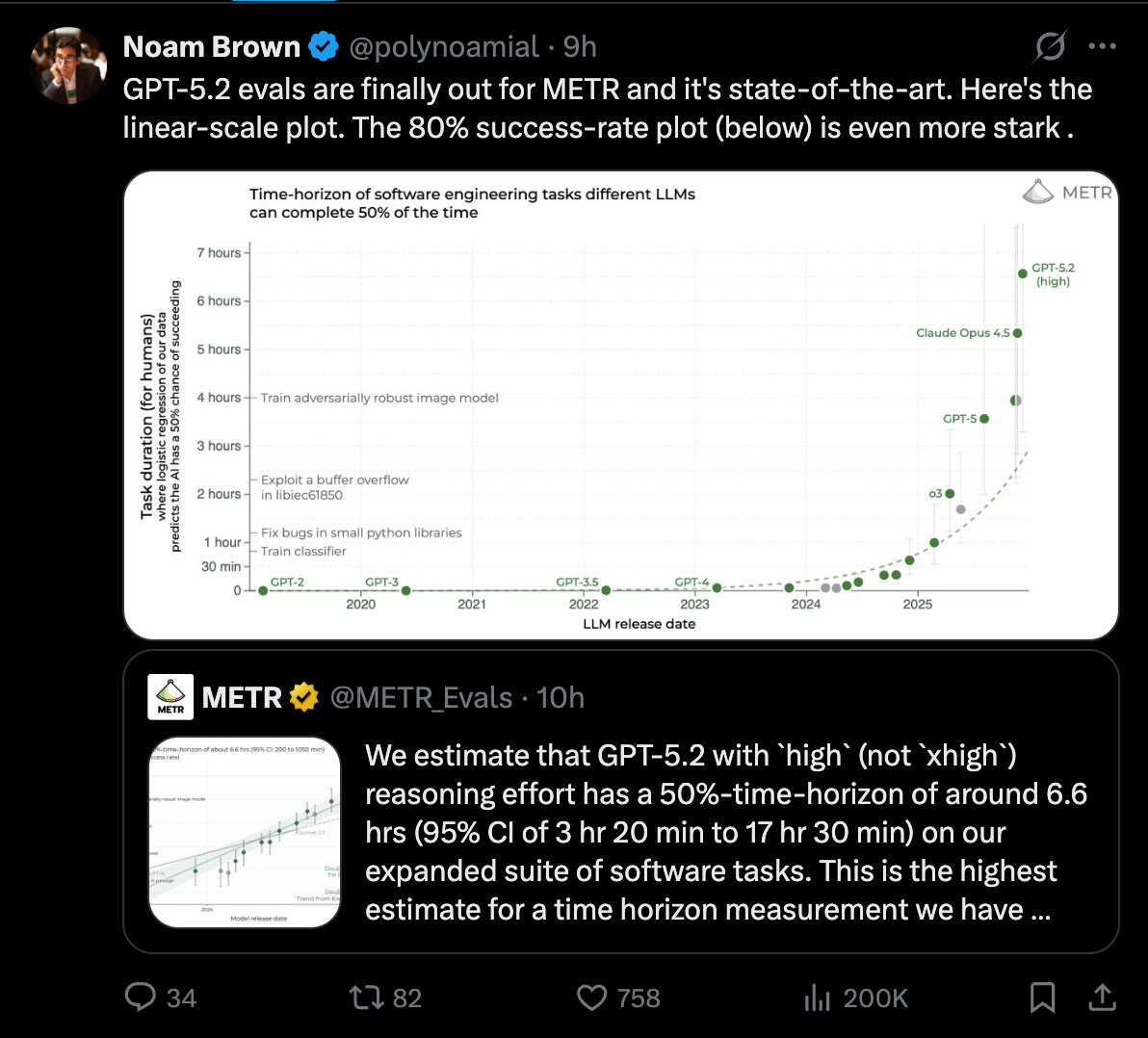
이번 주 AI 업계는 GPT-5.2의 압도적인 추론 성능 입증과 주요 기업들의 기록적인 펀딩 소식으로 요약된다. OpenAI의 GPT-5.2는 METR 벤치마크에서 인간 수준의 복잡한 소프트웨어 작업을 6.6시간 동안 수행할 수 있음을 보여주며 SOTA를 경신했다. ElevenLabs와 Cerebras는 각각 110억 달러와 230억 달러의 기업 가치를 인정받으며 데카콘 반열에 올랐고, VS Code와 GitHub는 코딩 에이전트를 IDE의 핵심으로 통합하는 대규모 업데이트를 단행했다. 이러한 흐름은 단순한 챗봇을 넘어 자율적인 에이전트 공학 시대로의 전환을 가속화하고 있다.
배경
LLM 벤치마크(MMLU, METR)에 대한 기본 이해, IDE 확장 프로그램 및 AI 에이전트 개념 지식, MoE(Mixture of Experts) 아키텍처에 대한 기초 지식
대상 독자
AI 연구원, 소프트웨어 엔지니어, AI 전략 기획자, 기술 투자자
의미 / 영향
AI 모델의 성능이 시간 단위의 복잡한 작업 수행으로 확장됨에 따라 인간의 역할은 직접 수행에서 에이전트 관리 및 검증으로 빠르게 전환될 것이다. 또한 하드웨어와 특화 모델에 대한 막대한 투자는 AI 생태계의 수직적 통합과 전문화를 가속화할 전망이다.
섹션별 상세
GPT-5.2(High reasoning effort)는 METR 벤치마크에서 복잡한 소프트웨어 공학 작업에 대해 약 6.6시간의 50% 성공 시간 지평을 기록하며 SOTA를 달성했다. 이는 Claude Opus 4.5를 능가하는 수치로, 모델이 장시간 동안 일관된 추론을 유지하며 문제를 해결할 수 있는 능력이 비약적으로 상승했음을 의미한다.
ElevenLabs는 110억 달러 가치로 5억 달러 규모의 Series D 투자를 유치했으며, Cerebras는 OpenAI와의 대규모 계약 이후 불과 5개월 만에 기업 가치가 230억 달러로 급등하며 10억 달러의 투자를 유치했다. 이는 AI 인프라와 특화 모델 시장에 대한 자본의 집중이 여전히 강력함을 보여준다.
VS Code는 Agent Sessions 워크스페이스를 도입하여 로컬 및 클라우드 에이전트를 통합 관리할 수 있게 했으며, GitHub Copilot은 Claude와 Codex 에이전트를 선택하여 비동기적으로 백로그를 처리하는 기능을 추가했다. 안드레아 카파시는 이를 Vibe Coding에서 Agentic Engineering으로의 패러다임 변화라고 정의했다.
알리바바의 Qwen3-Coder-Next는 80B MoE 구조임에도 3B의 활성 파라미터만으로 기존 대형 모델에 필적하는 코딩 성능을 보여주며 로컬 배포의 효율성을 증명했다. 또한 MIT 라이선스의 오픈소스 오디오 모델인 ACE-Step 1.5가 출시되어 Suno와 같은 상용 서비스에 근접한 품질의 음악 생성을 로컬 환경에서도 가능하게 했다.
Artificial Analysis는 기존의 포화된 벤치마크 대신 경제적으로 유용한 작업과 사실적 신뢰성에 초점을 맞춘 Intelligence Index v4.0을 발표했다. Perplexity는 딥 리서치 성능 측정을 위한 오픈소스 벤치마크인 DRACO를 공개하며 모델 평가 기준이 복잡한 의사결정 및 연구 수행 능력으로 이동하고 있음을 시사했다.
용어 해설
- METR
- — AI 모델의 자율적 능력과 위험성을 평가하는 비영리 연구 기관이다. 특히 모델이 복잡한 소프트웨어 공학 작업을 얼마나 오랜 시간 동안(Time-horizon) 일관되게 수행할 수 있는지를 측정하는 벤치마크를 통해 모델의 실질적인 추론 능력을 평가한다.
- Agentic Engineering
- — 개발자가 코드를 직접 작성하는 대신 AI 에이전트에게 목표를 부여하고, 에이전트가 코드를 작성, 실행, 수정하는 과정을 조율하고 감독하는 새로운 소프트웨어 개발 패러다임이다. 단순한 코드 완성을 넘어 자율적인 문제 해결 프로세스에 집중한다.
- MoE
- — 모델의 전체 파라미터 중 데이터에 따라 필요한 일부 전문가(Expert) 네트워크만 활성화하여 추론하는 구조이다. 전체 파라미터 대비 적은 계산량으로도 높은 성능을 낼 수 있어 Qwen3-Coder-Next와 같은 고효율 모델의 핵심 기술로 사용된다.
- Time Horizon
- — AI 모델이 특정 성공률을 유지하며 복잡한 작업을 지속적으로 수행할 수 있는 시간적 범위를 의미한다. 모델이 단발성 응답을 넘어 장기적인 프로젝트를 수행할 수 있는 추론의 깊이와 일관성을 나타내는 중요한 지표로 활용된다.
- Decacorn
- — 기업 가치가 100억 달러(약 13조 원) 이상인 비상장 스타트업을 의미한다. ElevenLabs와 Cerebras가 이번 대규모 펀딩을 통해 이 반열에 올라섰으며, 이는 AI 인프라 및 특화 모델 시장에 대한 자본의 강력한 신뢰를 상징한다.
AI 분석 전체 내용 보기
AI 요약 · 북마크 · 개인 피드 설정 — 무료
출처 · 인용 안내
원문 발행 2026. 02. 05.수집 2026. 02. 21.출처 타입 RSS
인용 시 "요약 출처: AI Trends (aitrends.kr)"를 표기하고, 사실 확인은 원문 보기 기준으로 진행해 주세요. 자세한 기준은 운영 정책을 참고해 주세요.