핵심 요약
Meta는 AMD GPU 플랫폼에서 AI 워크로드의 통신 병목 현상을 해결하기 위해 최적화된 통신 라이브러리인 RCCLX를 오픈소스로 공개했다. 이 라이브러리는 기존 RCCL을 기반으로 하며, Meta 내부 워크로드에서 검증된 Direct Data Access(DDA)와 저정밀도(Low Precision) 집합 통신 기능을 포함한다. DDA는 LLM 추론의 디코딩 단계에서 지연 시간을 대폭 줄여주며, 저정밀도 기능은 FP8 양자화를 통해 통신 대역폭 효율을 극대화한다. RCCLX는 Torchcomms와 통합되어 개발자가 플랫폼에 구애받지 않고 고성능 통신 기능을 쉽게 사용할 수 있도록 지원한다.
배경
PyTorch, AMD ROCm, 분산 컴퓨팅 기초, GPU 집합 통신(Collective Communication) 개념
대상 독자
분산 학습 및 고성능 LLM 추론 시스템을 구축하는 인프라 엔지니어 및 연구자
의미 / 영향
AMD GPU 생태계의 소프트웨어 스택 경쟁력을 강화하며, 특히 LLM 추론 비용과 지연 시간을 줄여 AMD 하드웨어 도입의 실질적인 이점을 제공한다.
섹션별 상세
이미지 분석
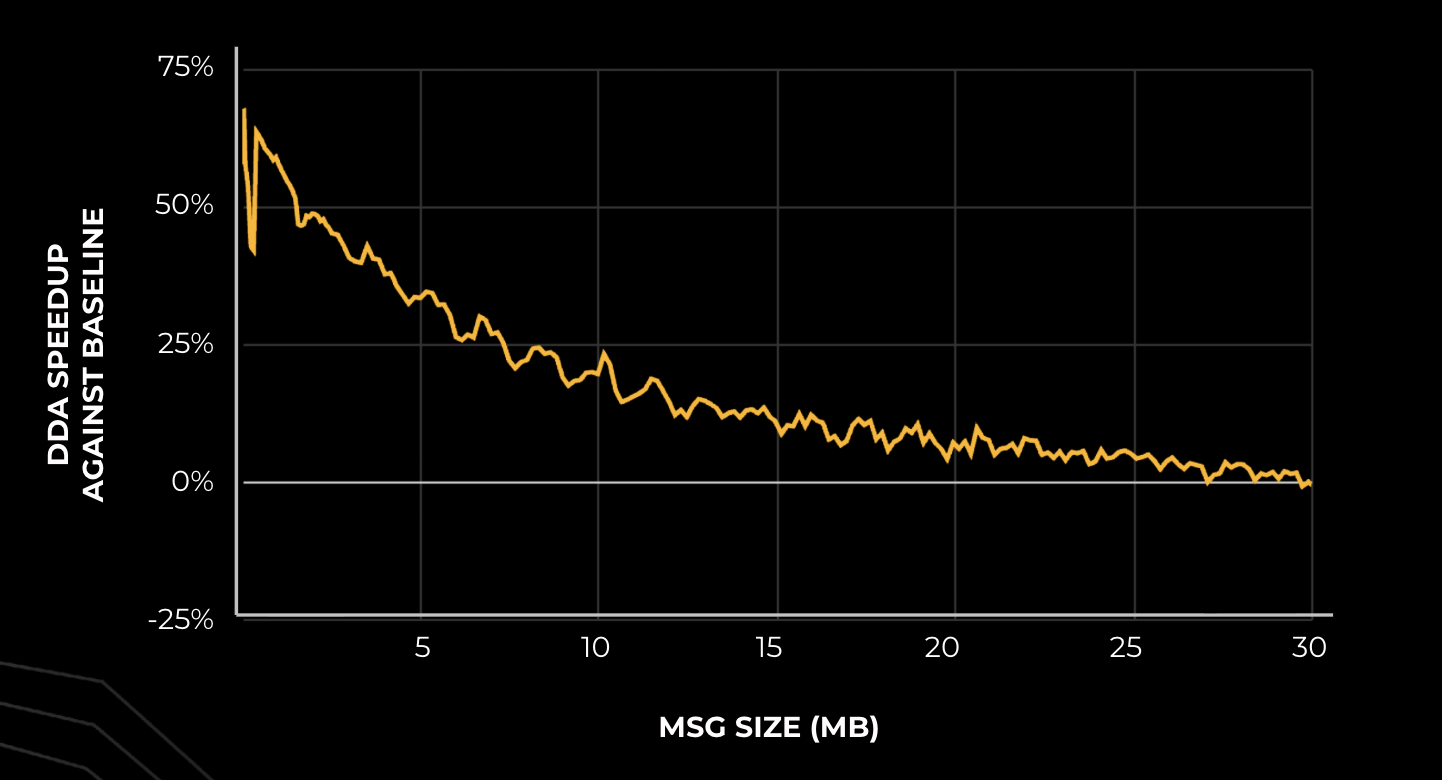
메시지 크기가 작을수록 DDA의 성능 향상이 두드러지며, 특히 5MB 이하의 소규모 메시지에서 기존 베이스라인 대비 최대 50% 이상의 속도 향상을 입증한다.
메시지 크기에 따른 DDA의 성능 향상 폭을 보여주는 그래프이다.
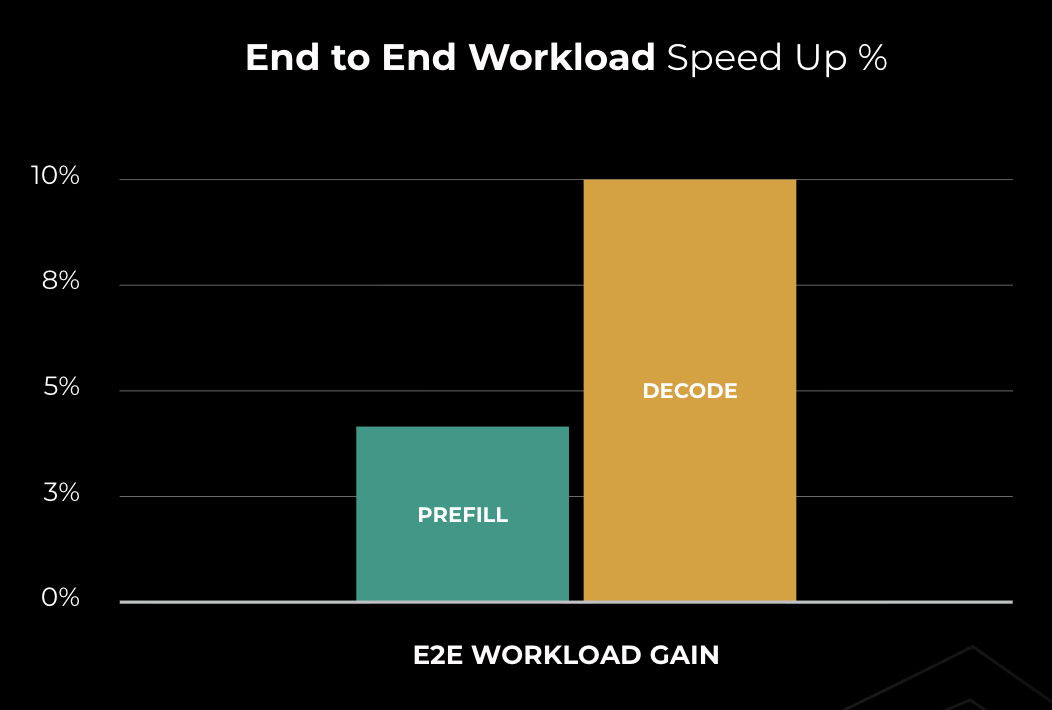
DDA 적용 시 Prefill 단계에서는 약 4%, Decode 단계에서는 약 10%의 전체 워크로드 성능 향상이 발생함을 시각화한다.
LLM 추론의 Prefill과 Decode 단계에서의 E2E 워크로드 성능 향상 지표이다.

torchcomms.new_comm 함수를 통해 'rcclx' 백엔드와 'hip' 디바이스를 지정하여 AMD GPU 환경에서 통신을 설정하는 방법을 보여준다.
Torchcomms를 사용하여 RCCLX 백엔드를 초기화하는 Python 코드 예시이다.
실무 Takeaway
- AMD MI300X 환경에서 LLM 추론 시 DDA를 활성화하면 디코딩 지연 시간을 최대 50%까지 단축하여 사용자 경험(TTIT)을 개선할 수 있다.
- 대규모 메시지 통신이 빈번한 학습/추론 환경에서는 RCCL_LOW_PRECISION_ENABLE=1 설정을 통해 FP8 압축 기반의 성능 이득을 즉시 얻을 수 있다.
- Torchcomms를 활용하면 NVIDIA(NCCLX)와 AMD(RCCLX) 간의 코드 변경을 최소화하면서 고성능 커스텀 통신 기능을 유지하는 멀티 플랫폼 전략이 가능하다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료