핵심 요약
대규모 언어 모델(LLM)의 추론 및 학습 과정에서 GPU 간 통신 병목 현상은 전체 성능의 주요 장애물이다. Meta는 이를 해결하기 위해 AMD 플랫폼에 최적화된 통신 라이브러리인 RCCLX를 오픈소스로 공개했다. RCCLX는 소규모 메시지 지연 시간을 줄이는 Direct Data Access(DDA)와 대규모 데이터 전송 효율을 높이는 저정밀도(Low Precision) 집합 통신 기능을 도입했다. 이를 통해 AMD MI300X 환경에서 디코딩 단계의 지연 시간을 줄이고 전체 처리량을 개선하는 성과를 거두었다.
배경
GPU 집합 통신(AllReduce, AllGather 등)에 대한 이해, AMD ROCm 환경 및 Instinct GPU 아키텍처 지식, PyTorch 및 Torchcomms 라이브러리 사용 경험
대상 독자
AMD GPU 기반 AI 인프라 엔지니어 및 LLM 성능 최적화 개발자
의미 / 영향
AMD GPU 생태계의 소프트웨어 스택이 강화되어 NVIDIA 중심의 AI 하드웨어 시장에 실질적인 대안을 제시한다. 특히 통신 병목 해결을 통해 AMD 하드웨어의 가성비와 효율성이 크게 개선될 것으로 보인다.
섹션별 상세
이미지 분석
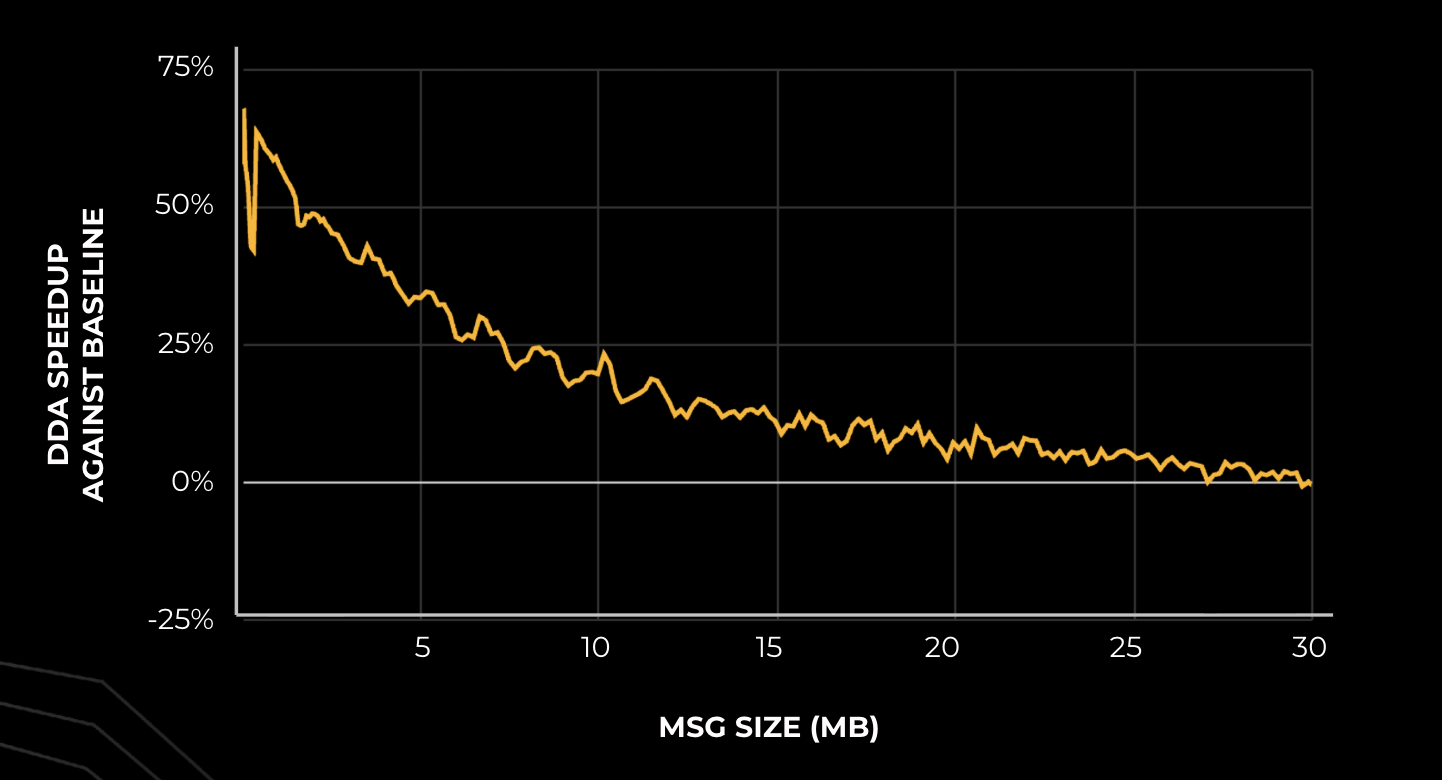
작은 메시지 크기에서 기준 대비 최대 70%에 가까운 속도 향상을 기록했다. 메시지 크기가 커질수록 향상 폭은 줄어들지만 여전히 유의미한 이득을 제공함을 보여준다.
메시지 크기에 따른 DDA의 속도 향상 폭을 나타내는 그래프이다.
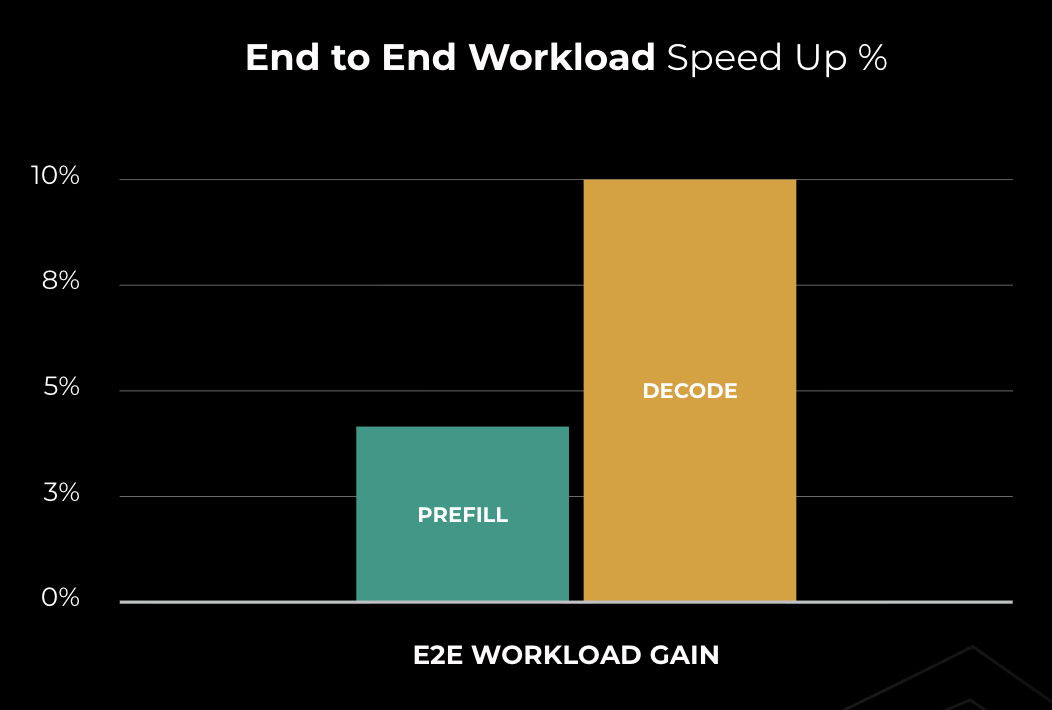
프리필 단계에서 약 4%, 디코딩 단계에서 약 10%의 성능 향상이 발생했음을 시각화했다. 이는 DDA 기술이 실제 LLM 추론 워크로드에 미치는 실질적인 영향을 입증한다.
엔드투엔드 워크로드에서 프리필과 디코딩 단계의 속도 향상 비율을 보여주는 막대 그래프이다.
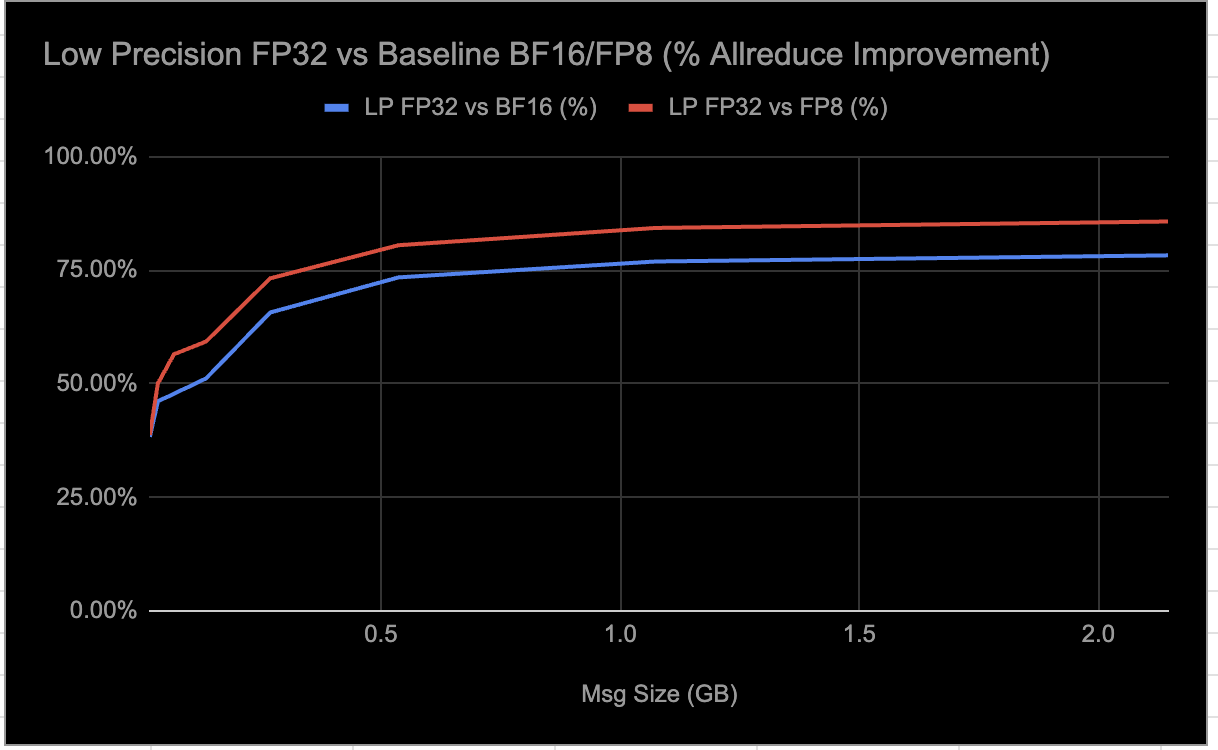
메시지 크기가 커질수록 개선율이 상승하여 최대 75-85% 수준의 성능 향상을 달성했다. 대규모 데이터 통신에서 저정밀도 최적화의 효율성을 뒷받침한다.
저정밀도 FP32와 기준 BF16/FP8 간의 AllReduce 개선율을 나타낸다.

기존 NVIDIA 환경에서의 통신 초기화 및 AllReduce 실행 방식을 보여준다. 이후 제시되는 AMD용 코드와 구조가 동일함을 비교하기 위한 자료이다.
NVIDIA 플랫폼에서 NCCLX 백엔드를 사용하는 Torchcomms 코드 예제이다.

백엔드 이름을 'rcclx'로, 장치를 'hip'으로 변경하는 것만으로 AMD 최적화 기능을 사용할 수 있음을 증명한다. 플랫폼 간 코드 이식성이 매우 높음을 시사한다.
AMD 플랫폼에서 RCCLX 백엔드를 사용하는 Torchcomms 코드 예제이다.
실무 Takeaway
- AMD MI300X 기반 LLM 서비스 구축 시 RCCLX의 DDA 기능을 활용해 디코딩 지연 시간을 최대 50%까지 단축 가능하다.
- 대규모 모델 학습 및 추론 시 RCCL_LOW_PRECISION_ENABLE=1 설정을 통해 수치 정확도를 유지하며 통신 처리량을 7% 향상시킬 수 있다.
- Torchcomms를 사용하면 코드 수정 없이 NVIDIA(NCCLX)와 AMD(RCCLX) 플랫폼 간의 통신 최적화 기능을 교체 적용할 수 있다.
언급된 리소스
AI 요약 · 북마크 · 개인 피드 설정 — 무료