핵심 요약
기존 LLM의 순차적 디코딩 방식은 에이전트나 RAG와 같은 반복 루프 환경에서 지연 시간 누적 문제를 야기한다. Inception은 이를 해결하기 위해 여러 토큰을 동시에 생성하고 정제하는 디퓨전 기반 아키텍처의 Mercury 2를 출시했다. 이 모델은 NVIDIA Blackwell GPU에서 초당 1,009토큰의 속도를 기록하며 기존 모델 대비 5배 이상의 성능 향상을 보여준다. 실시간 음성 인터페이스, 복잡한 에이전트 워크플로, 실시간 코드 편집 등 지연 시간에 민감한 프로덕션 환경에 최적화된 솔루션을 제공한다.
배경
LLM 추론 메커니즘(Autoregressive Decoding), 디퓨전 모델 기초, API 통합 지식
대상 독자
실시간 응답이 중요한 LLM 에이전트 및 프로덕션 서비스 개발자
의미 / 영향
LLM 아키텍처가 순차적 생성에서 병렬 생성(디퓨전)으로 진화하는 중요한 변곡점을 보여준다. 이는 특히 지연 시간이 병목이었던 멀티 에이전트 시스템과 실시간 인터랙티브 AI 시장의 확장을 가속화할 것이다.
섹션별 상세
이미지 분석
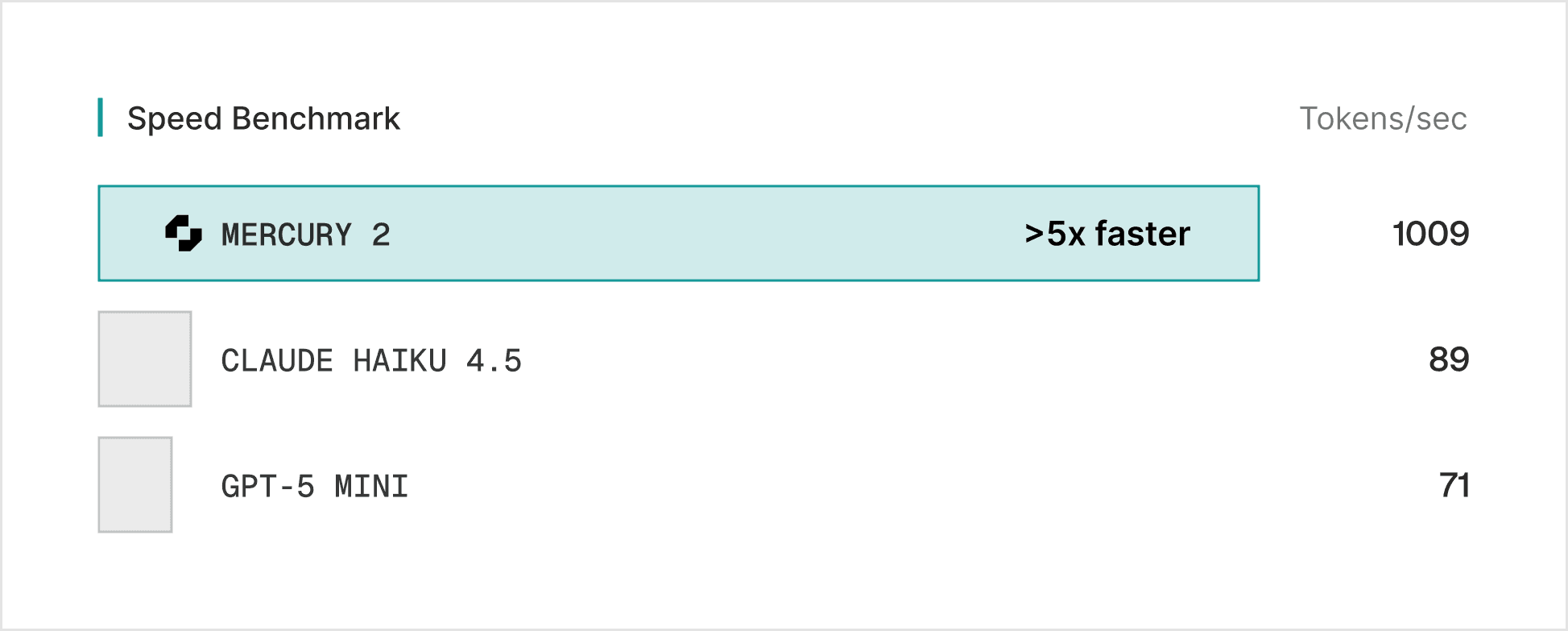
Mercury 2가 1,009 t/s를 기록하며 Claude Haiku 4.5(89 t/s)나 GPT-5 Mini(71 t/s)보다 5배 이상 빠르다는 점을 시각적으로 증명한다.
Mercury 2와 타 모델 간의 초당 토큰 생성 속도 비교 차트
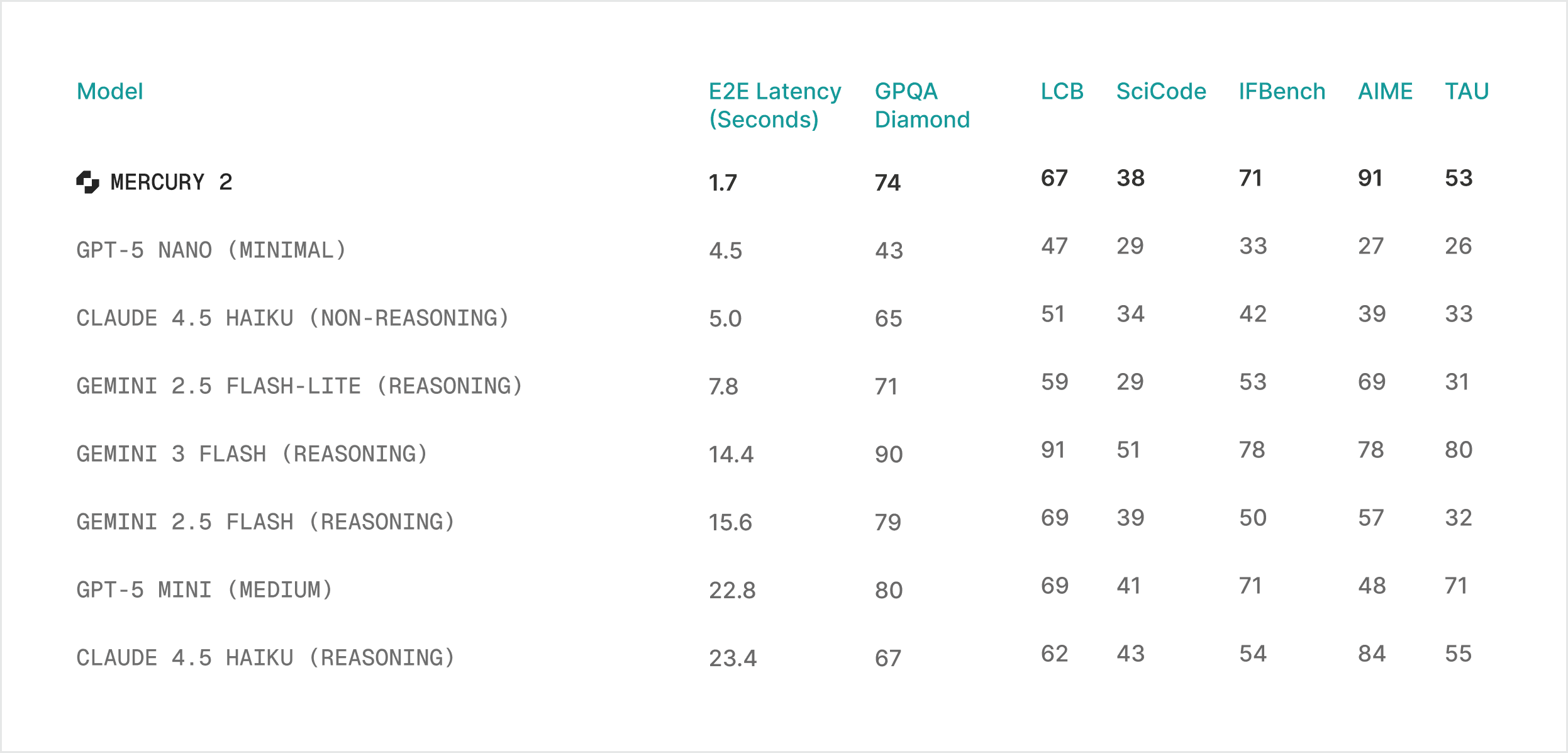
Mercury 2가 1.7초의 낮은 지연 시간을 유지하면서도 GPQA Diamond(74), AIME(91) 등 주요 추론 벤치마크에서 경쟁 모델 대비 우수한 성능을 보임을 나타낸다.
다양한 벤치마크 점수와 지연 시간을 정리한 모델 성능 비교표
실무 Takeaway
- 디퓨전 기반 병렬 디코딩을 통해 추론형 모델의 고질적인 문제인 높은 지연 시간을 획기적으로 단축했다.
- 초당 1,000토큰 이상의 속도와 저렴한 토큰 가격($0.25/$0.75)을 결합하여 대규모 에이전트 루프 운영 비용을 최적화할 수 있다.
- OpenAI API 호환성을 제공하므로 기존 LLM 기반 서비스를 최소한의 노력으로 고속 추론 환경으로 전환 가능하다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료