핵심 요약
대형 언어 모델(LLM) 추론에서 KV 캐시는 성능의 핵심이지만 GPU 메모리 용량 제한으로 인해 대규모 동시 요청 처리에 한계가 있다. llm-d는 이를 해결하기 위해 vLLM의 오프로딩 커넥터를 기반으로 한 파일 시스템(FS) 백엔드를 도입했다. 이 시스템은 KV 블록을 공유 스토리지에 저장하여 여러 노드 간에 캐시를 공유하고 GPU/CPU 메모리 범위를 넘어서는 방대한 데이터를 관리한다. 벤치마크 결과 대규모 사용자 환경에서 기존 GPU 전용 방식 대비 처리량을 획기적으로 유지하며 긴 프롬프트의 경우 TTFT를 최대 16.8배 단축했다.
배경
LLM 추론 메커니즘(Prefill/Decode), KV 캐시 개념, vLLM 아키텍처, 분산 시스템 기초
대상 독자
대규모 LLM 추론 인프라를 운영하거나 vLLM 성능 최적화에 관심 있는 엔지니어
의미 / 영향
이 기술은 고가의 GPU 메모리에 의존하지 않고도 방대한 컨텍스트를 저비용 스토리지로 관리할 수 있게 함으로써 엔터프라이즈급 대규모 AI 서비스 운영의 비용 효율성과 확장성을 동시에 확보한다.
섹션별 상세
이미지 분석
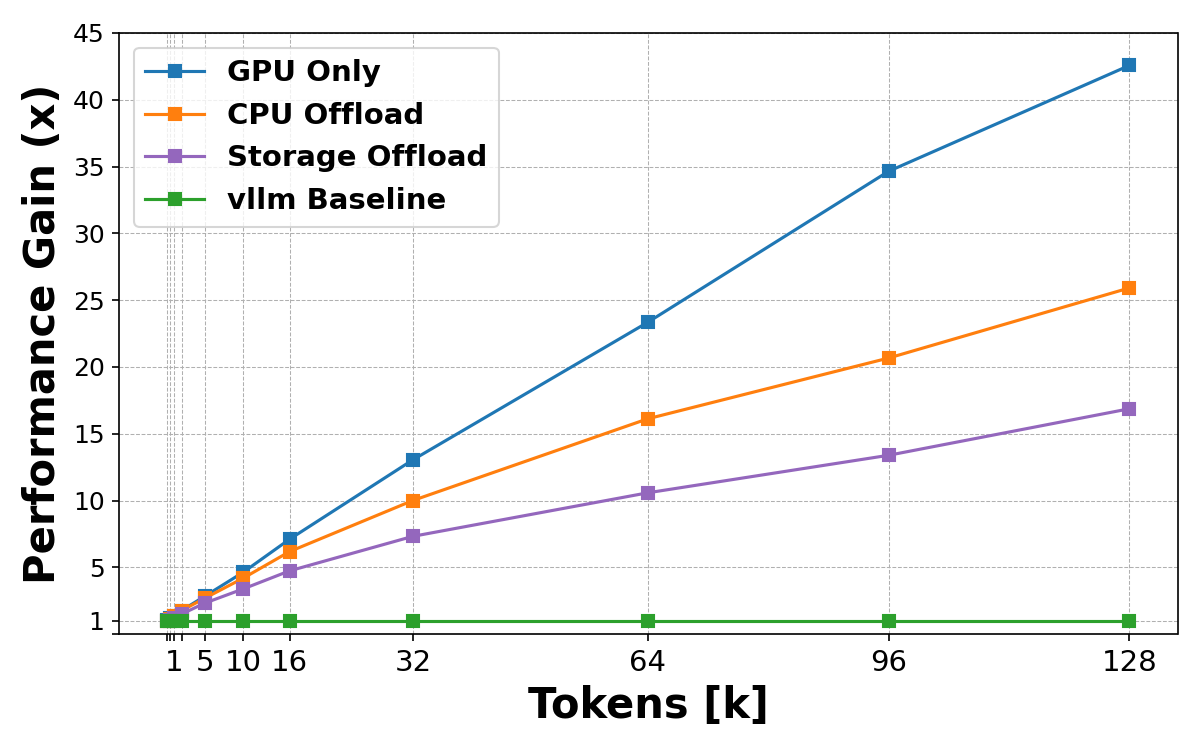
토큰 수가 많아질수록 스토리지 오프로딩이 프리필보다 효율적이며 128k 토큰 기준 최대 16.8배의 속도 향상을 보임을 입증한다. 다만 GPU 및 CPU 캐시보다는 속도가 낮음을 함께 보여준다.
토큰 수 증가에 따른 프리필 대비 캐시 로드 방식별 성능 향상 폭 그래프
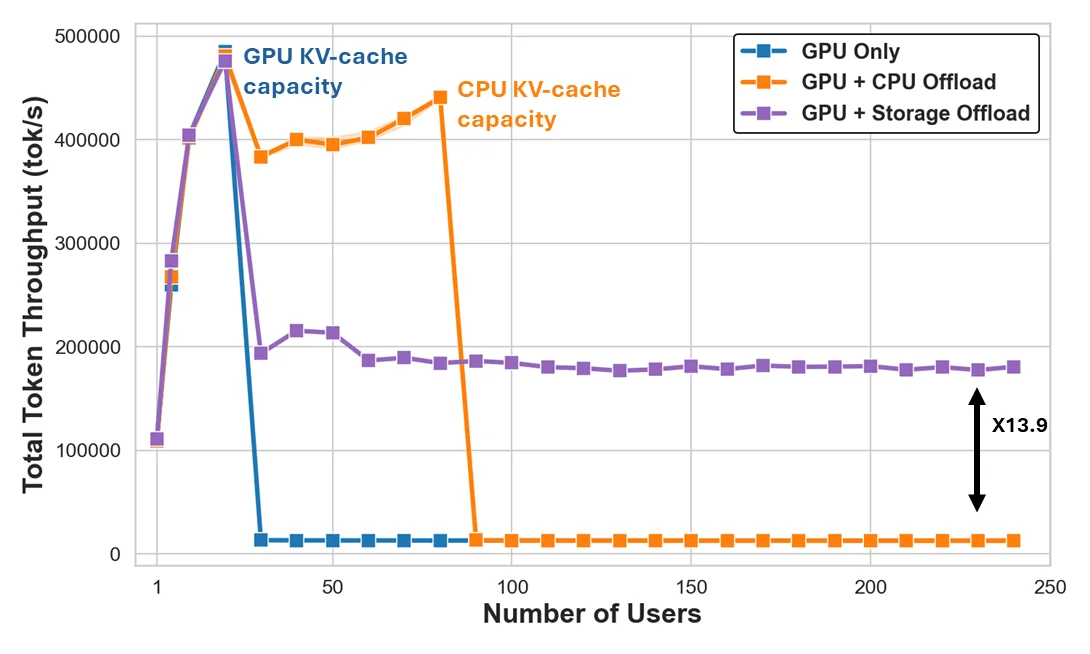
GPU 및 CPU 캐시 용량을 초과하는 지점에서 성능이 급락하는 기존 방식과 달리 스토리지 오프로딩은 사용자 수가 늘어나도 안정적인 처리량을 유지함을 시각화한다.
사용자 수 증가에 따른 캐시 계층별 총 토큰 처리량(Throughput) 비교 그래프
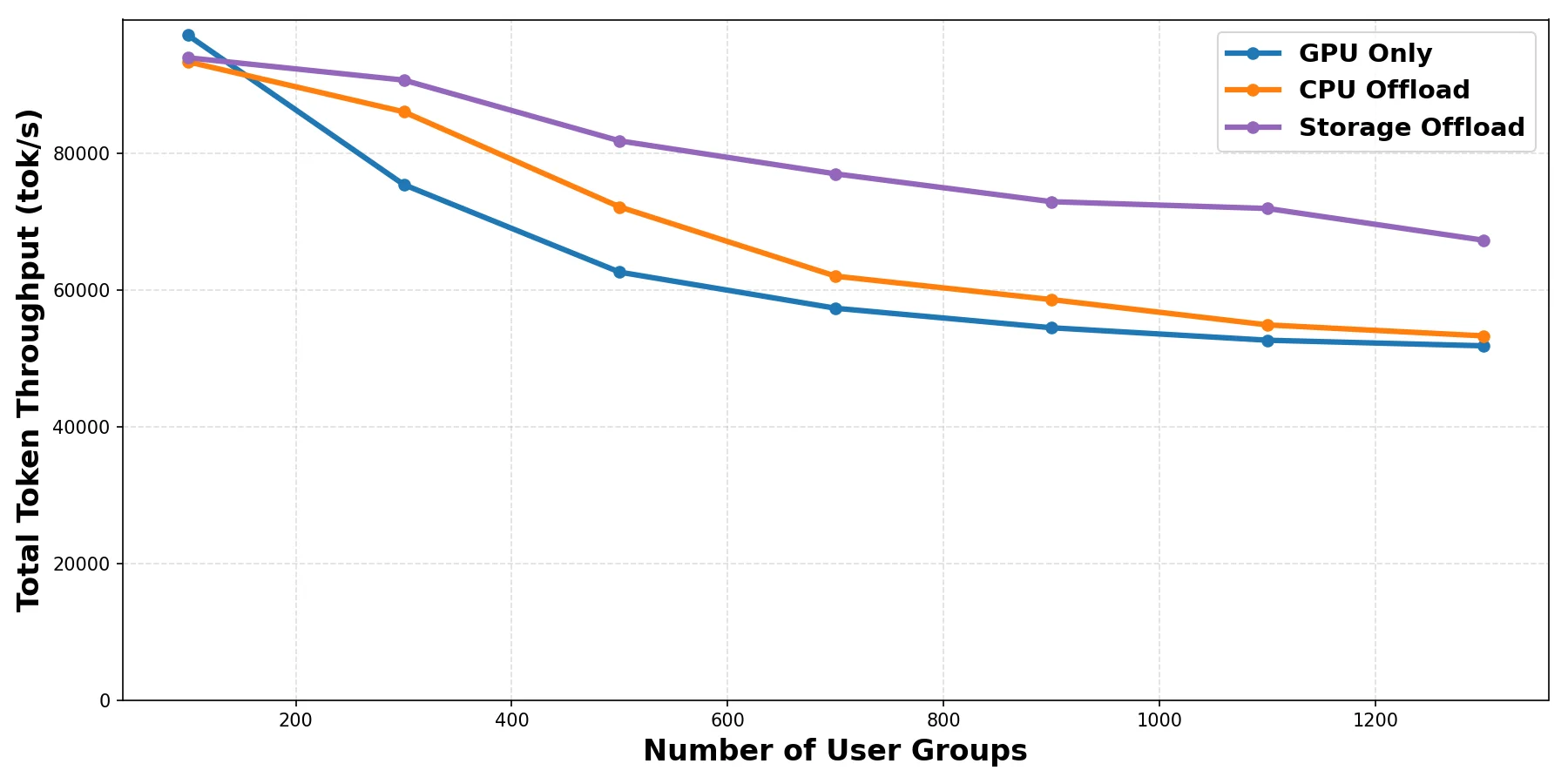
스토리지 오프로딩이 고부하 환경에서도 GPU 전용 방식 대비 약 13.9배 높은 처리량을 유지하며 실제 서비스 환경에서의 확장성을 증명한다.
실제 혼합 워크로드 환경에서 사용자 그룹 수에 따른 처리량 변화 그래프
실무 Takeaway
- 공유 스토리지를 KV 캐시 계층으로 활용하여 분산 추론 클러스터의 캐시 히트율을 극대화하고 노드 간 데이터 공유를 실현한다.
- GPU/CPU 메모리 한계를 초과하는 대규모 동시 접속 환경에서 추론 처리량 붕괴를 방지하고 안정적인 성능을 유지한다.
- 비동기 I/O 및 병렬 처리 설계를 통해 스토리지 접근으로 인한 GPU 연산 간섭을 최소화하고 전체 시스템 효율을 높인다.
AI 요약 · 북마크 · 개인 피드 설정 — 무료